max-http-header-size引起的oom是什么情况,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
记一次线上OOM事故
根据用户反馈,某服务不能提供服务,然后我们进行排查,进程id还在,但日志不输出。通过jstat -gcutil 查看内存使用情况;发现出现Full GC了。
ps -ef | grep --color=auto 项目名 | grep --color=auto -v "grep" | awk '{print $2}' | xargs -i jstat -gcutil {} 2000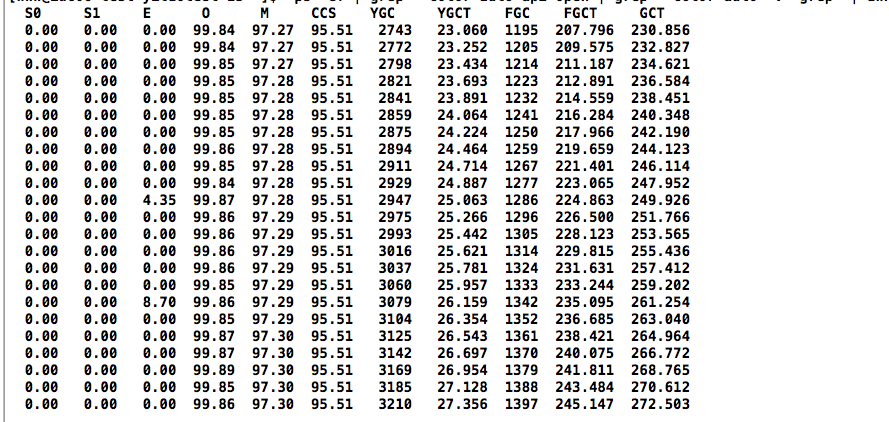
S0:幸存1区当前使用比例 S1:幸存2区当前使用比例 E:伊甸园区使用比例 O:老年代使用比例 M:元数据区使用比例 CCS:压缩使用比例 YGC:年轻代垃圾回收次数 FGC:老年代垃圾回收次数 FGCT:老年代垃圾回收消耗时间 GCT:垃圾回收消耗总时间
当年轻代内存满时,会引发一次普通GC,该GC仅回收年轻代。需要强调的时,年轻代满是指Eden代满,Survivor满不会引发GC
当年老代满时会引发Full GC,Full GC将会同时回收年轻代、年老代
jmap -dump:format=b,file=812.hprof 15968tar -czf 814.tar.gz 814.hprof
一看就有问题了。
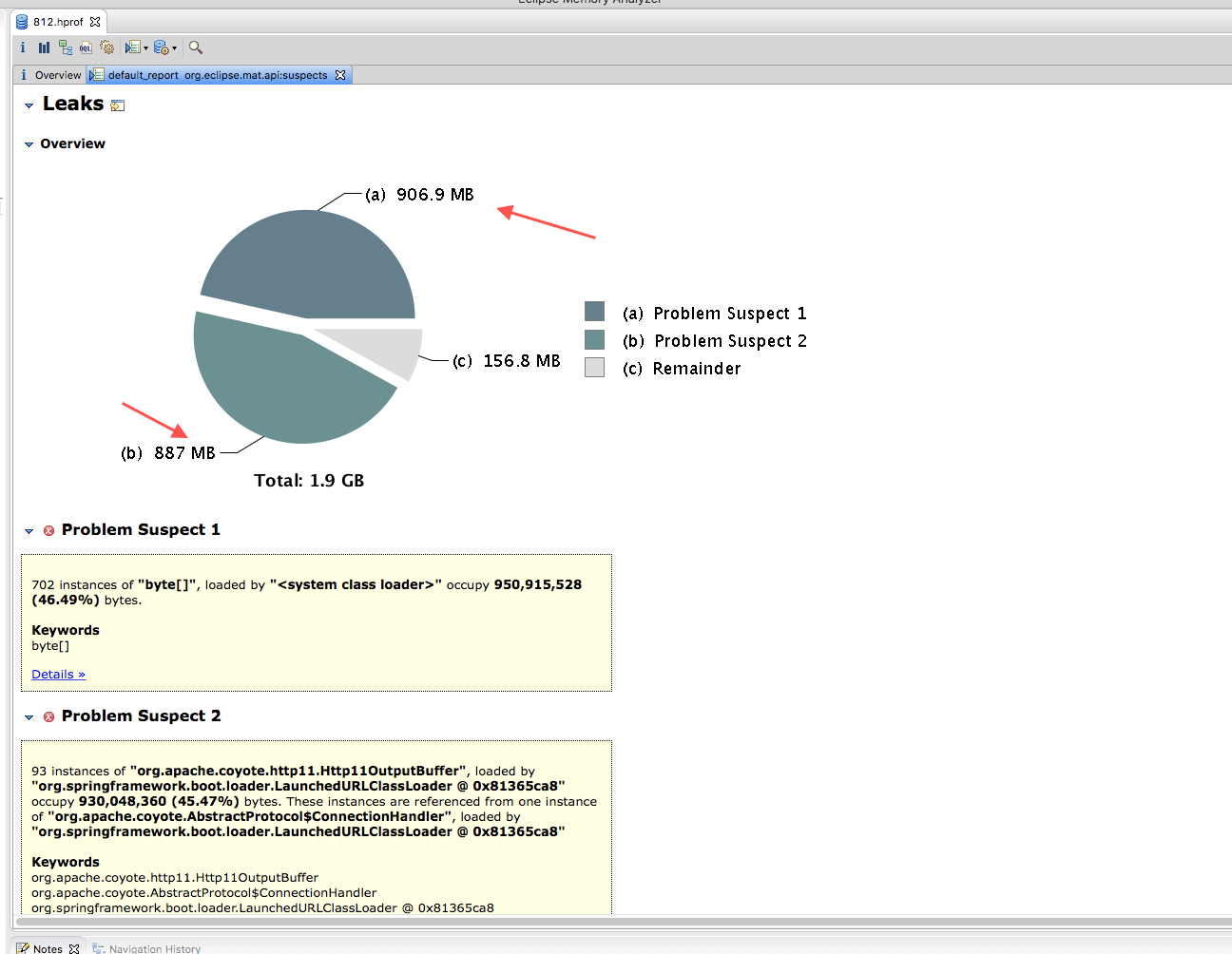
查看Histogram
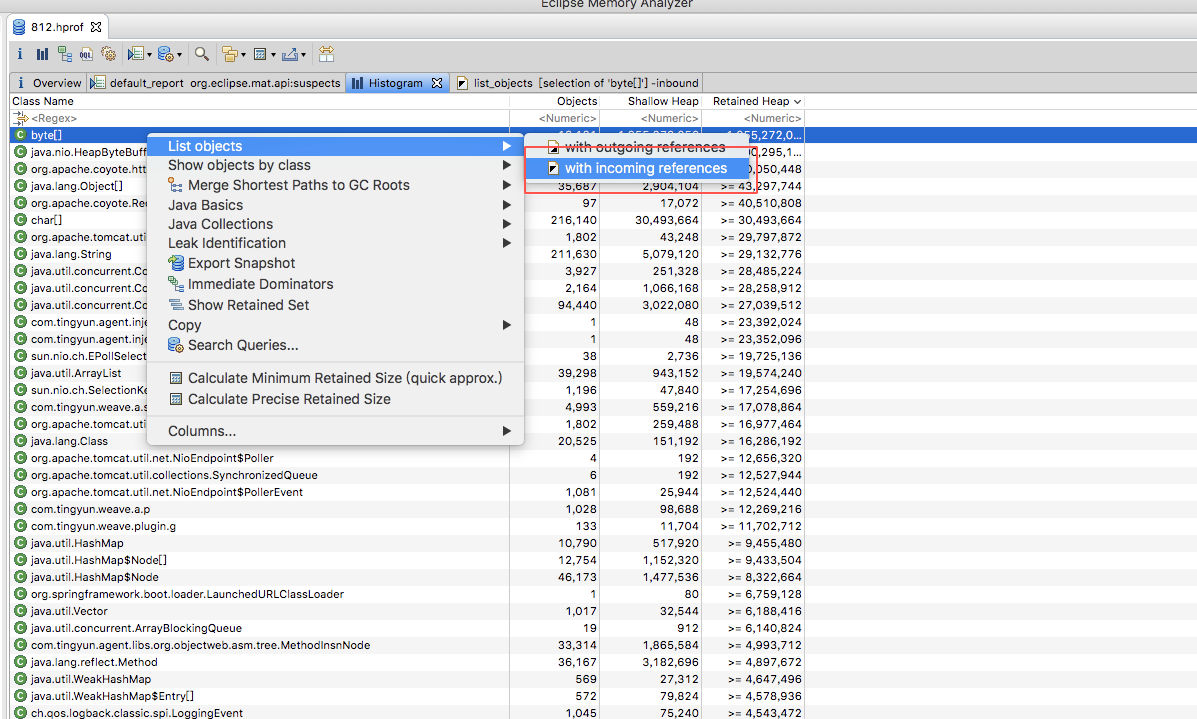
进行引用查看

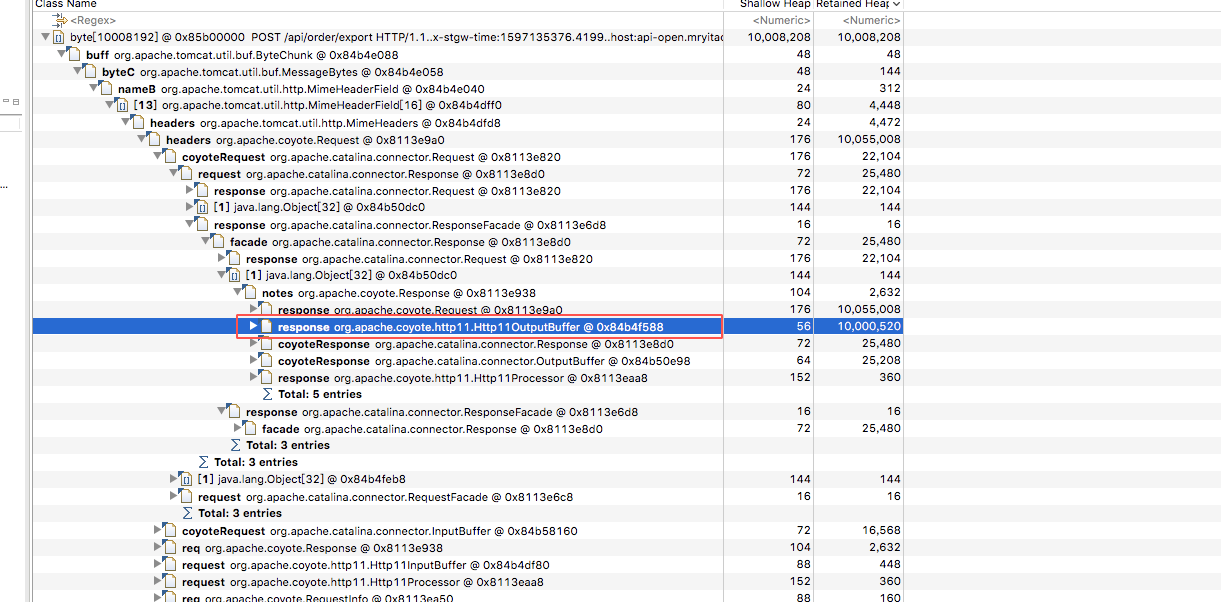
通过mat分析查看这个对象内存占用很大有10M左右,所以重点对这个类分析,看看干了什么。
org.apache.coyote.Response#outputBuffer这个类是tomcat输出到socket时的类。
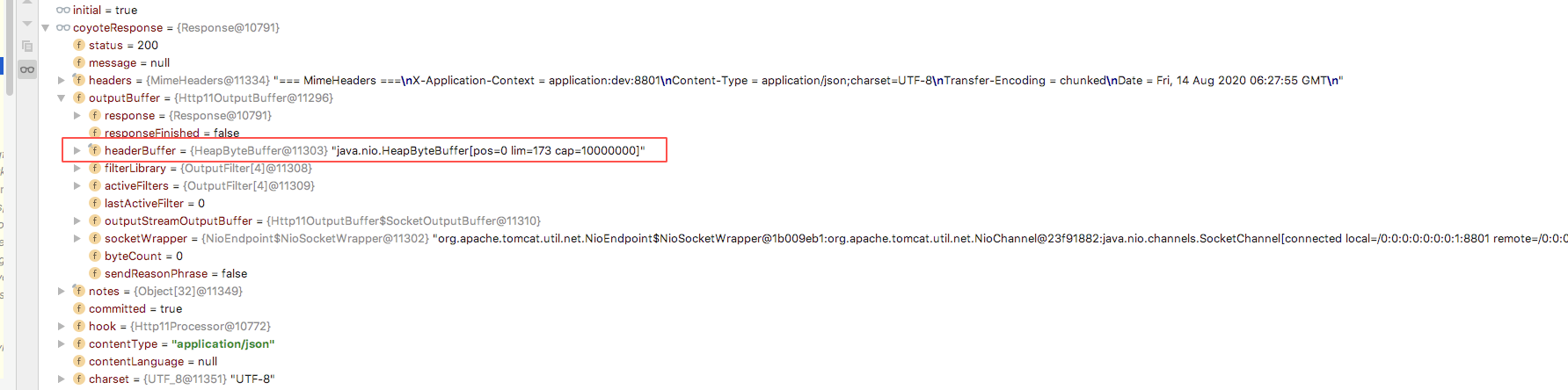
问题就在这里了,这里的对象内存10m左右!!!
这个值怎么来的呢?老同事设置的,也不知道当初为啥设置这个值。这个原因后面给出
server:
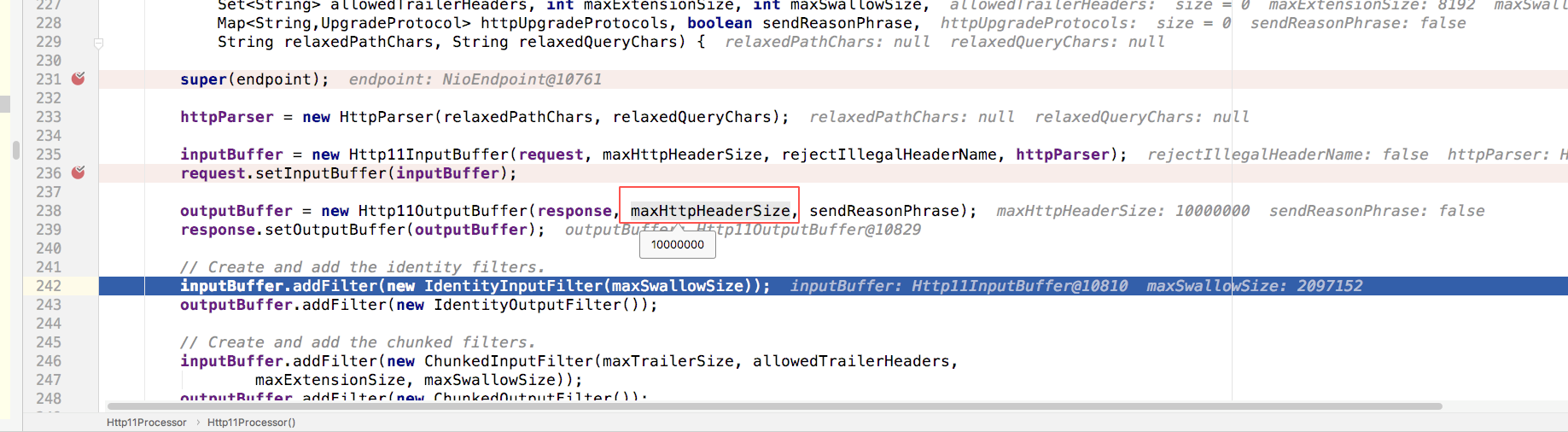
max-http-header-size: 10000000源码分析,后方高能!查看tomcat调用链路
org.apache.catalina.connector.CoyoteAdapter#service 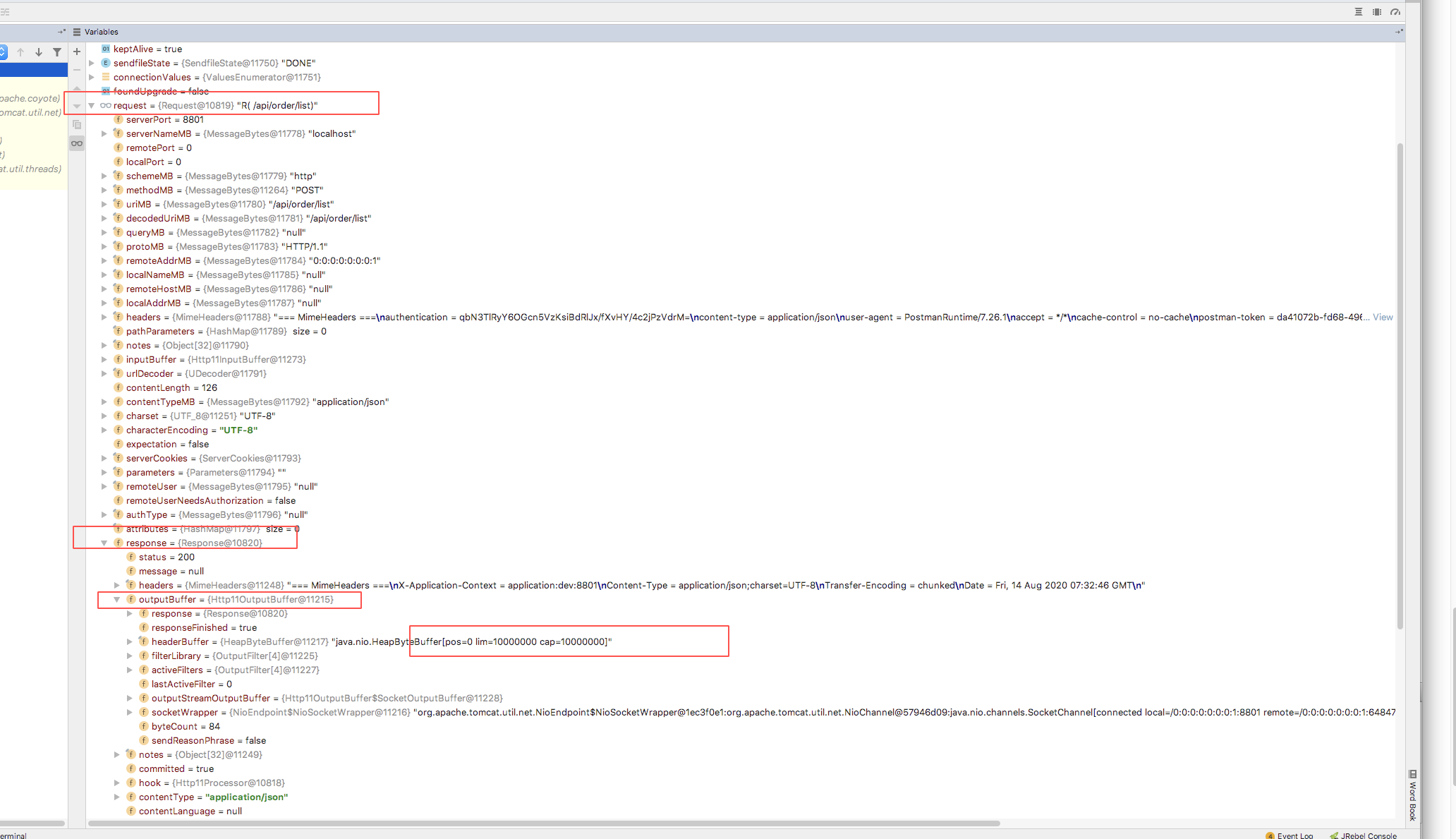
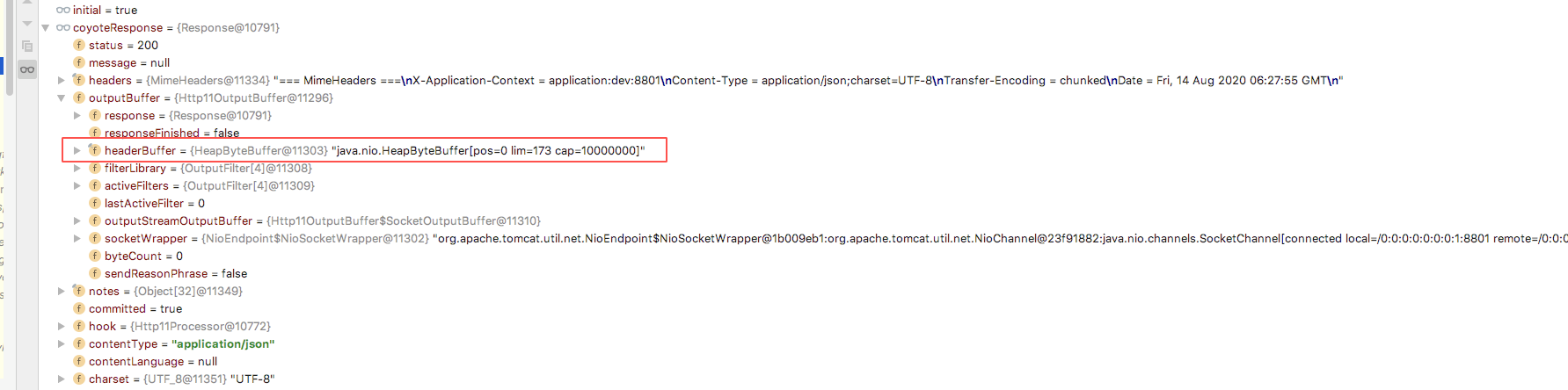
 最后tomcat通过socket返回结果
最后tomcat通过socket返回结果
org.apache.coyote.http11.Http11OutputBuffer#commit
protected void commit() throws IOException {
response.setCommitted(true);
if (headerBuffer.position() > 0) {
// Sending the response header buffer
headerBuffer.flip();
try {
socketWrapper.write(isBlocking(), headerBuffer);
} finally {
headerBuffer.position(0).limit(headerBuffer.capacity());
}
}
}也就是一个请求会返回10m数据给前端,在用jemter100个并发测试时,堆内存直接打满。服务停止。
由于项目提供的api接口提供给第三方平台使用,用户身份校验是放在header里来做的。当第三方平台没按着规范来传值呢?系统发生错误。Error parsing HTTP request header
org.apache.coyote.http11.Http11Processor#service
public SocketState service(SocketWrapperBase<?> socketWrapper)
throws IOException {
RequestInfo rp = request.getRequestProcessor();
rp.setStage(org.apache.coyote.Constants.STAGE_PARSE);
// Setting up the I/O
setSocketWrapper(socketWrapper);
inputBuffer.init(socketWrapper);
outputBuffer.init(socketWrapper);
// Flags
keepAlive = true;
openSocket = false;
readComplete = true;
boolean keptAlive = false;
SendfileState sendfileState = SendfileState.DONE;
while (!getErrorState().isError() && keepAlive && !isAsync() && upgradeToken == null &&
sendfileState == SendfileState.DONE && !endpoint.isPaused()) {
// Parsing the request header
try {
// 这行代码报错
if (!inputBuffer.parseRequestLine(keptAlive)) {
if (inputBuffer.getParsingRequestLinePhase() == -1) {
return SocketState.UPGRADING;
} else if (handleIncompleteRequestLineRead()) {
break;
}
}
.....
} catch (IOException e) {
if (log.isDebugEnabled()) {
// 打印错误。。。。。。
log.debug(sm.getString("http11processor.header.parse"), e);
}
setErrorState(ErrorState.CLOSE_CONNECTION_NOW, e);
break;
} catch (Throwable t) {
ExceptionUtils.handleThrowable(t);
UserDataHelper.Mode logMode = userDataHelper.getNextMode();
if (logMode != null) {
String message = sm.getString("http11processor.header.parse");
switch (logMode) {
case INFO_THEN_DEBUG:
message += sm.getString("http11processor.fallToDebug");
//$FALL-THROUGH$
case INFO:
log.info(message, t);
break;
case DEBUG:
log.debug(message, t);
}
}
// 400 - Bad Request
response.setStatus(400);
setErrorState(ErrorState.CLOSE_CLEAN, t);
getAdapter().log(request, response, 0);
}
......
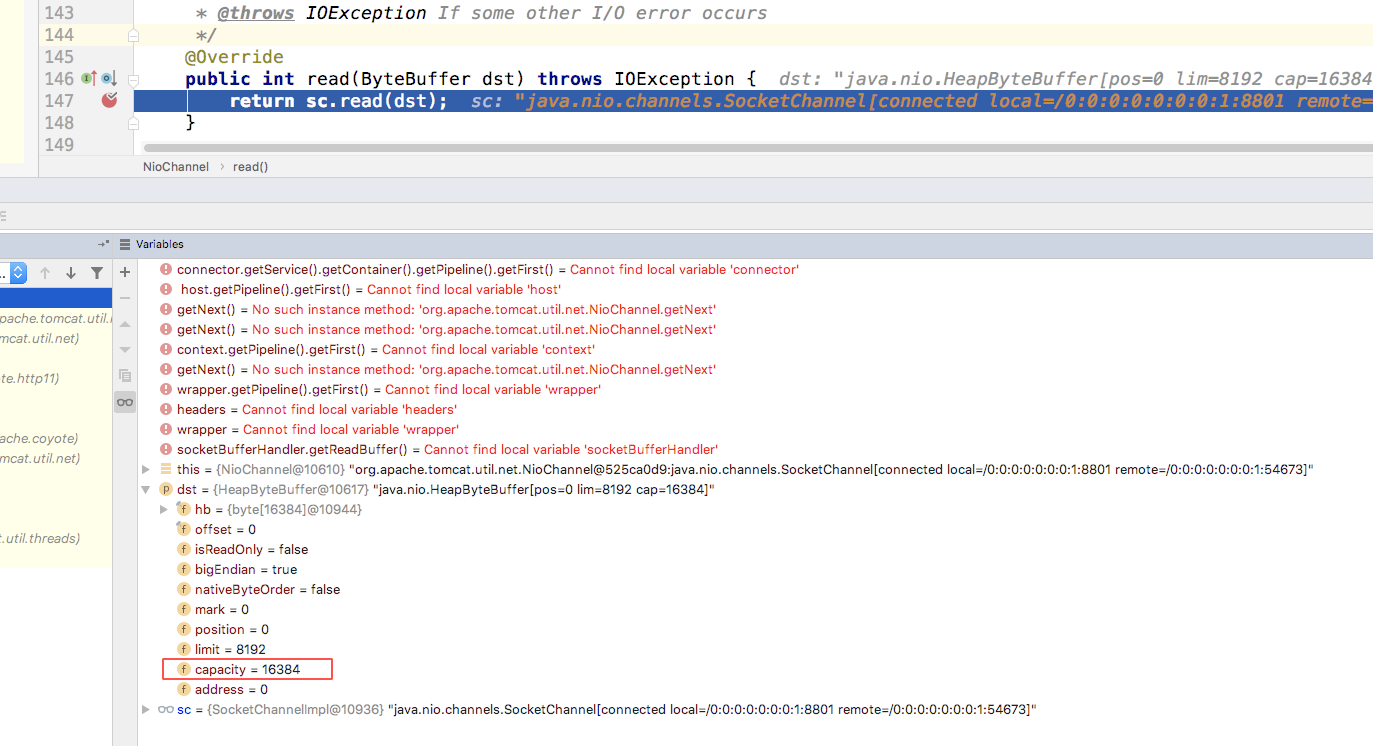
}org.apache.tomcat.util.net.NioChannel#read
protected SocketChannel sc = null;
@Override
public int read(ByteBuffer dst) throws IOException {
return sc.read(dst);
}
org.apache.coyote.http11.Http11InputBuffer#init 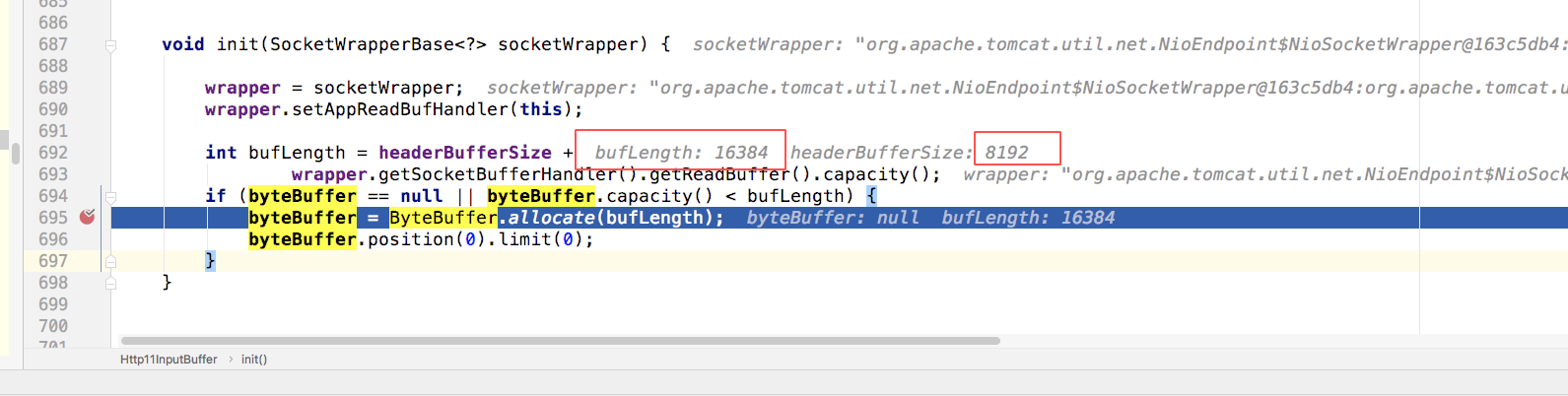
报错原因在于,SocketChannel.read的数据大于接受的buffer了。默认buffer的是16kb,如果超出则报错。而tomcat遇到这个错误时并没有抛出该异常,而是记录日志;并输出结果是code=400;
而老同事通过排查日志发现Error parsing HTTP request header 百度搜索后,果断调整max-http-header-size。当把max-http-header-size调整10m时,第三方平台调用接口正常并返回验证失败错误;第三方平台发现后跳转验证规则后并未反馈该情况给老同事;则为oom埋下深坑;
关于max-http-header-size引起的oom是什么情况问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/penghaozhong/blog/4494663



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



