JAVA中怎么实现内存分布,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
java的内存分布如下:
1,本地方法栈;
2,程序计数器;
3,虚拟机栈(栈帧1(方法A),栈帧2(方法B));
4,堆区(新生代(Eden区,S0,S1...),老年代);
5,元数据区(常量池,方法元信息,类元信息);
如下图所示:
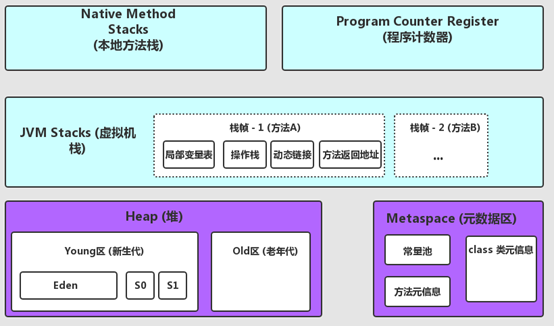
各个区域对应明细如下:
1,堆区:
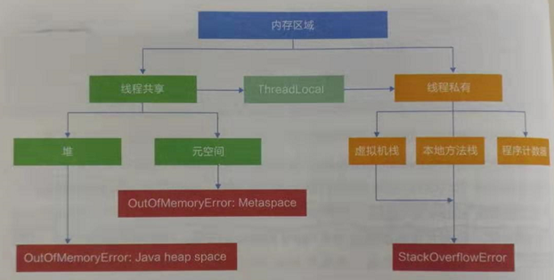
存储着几乎所有的实例对象,堆由垃圾收集器自动回收,堆区由各子线程共享使用。
堆的内存空间既可以固定大小,也可以在运行时动态调整,通过如下参数设定初始值和最大值,比如-Xms256M –Xmx1024M,分别代表最小堆容量和最大堆容量,在线上环境时, JVM的Xms和Xmx设置成一样大小,避免在GC后调整堆大小时带来的额外压力。
堆分成两大块:新生代和老年代,对象产生之初在新生代,步入暮年进入老年代,但是老年代也接纳在新生代无法容纳的超大对象,新生代=1个Eden区+2个Survivor区域。绝大部分对象在Eden区生成,当Eden区域填满的时候,会触发Young Garbage Collection,每个对象有一个计数器,每次YGC都会加1,-XX:MaxTenuringThreshold参数能配置计数器的值到达某个阈值的时候,对象从新生代晋升到老年代。
给JVM设置参数-XX:+HeapDumpOnOutOfMemoryError,让JVM遇到OOM异常时能输出堆内信息
2,虚拟机栈:
栈是一个先进后出的数据结构。
JVM是基于栈结构的运行环境,JVM中的虚拟机栈是描述java方法执行的内存区域,它是线程私有的;每个方法从开始调用到执行完成的过程,就是栈帧从入栈到出栈的过程;
栈帧是方法运行的基本结构,在执行引擎运行时,所有指令都只能对当前栈帧进行操作。而StackOverFlowError表示请求的栈溢出,导致内存耗尽,通常出现在递归方法中。
3,局部变量表:
局部变量表是存放方法参数和局部变量的区域。
4,操作栈:
操作栈是一个初始状态为空的桶式结构栈。
5,本地方法栈:
本地方法栈为Native方法服务,现成开始调用本地方法时,会进入一个不再受JVM约束的世界。
6,程序计数寄存器:
由于CPU时间片轮限制,众多线程在并发执行过程中,任何一个确定的时刻,一个处理器或者多核处理器中的一个内核,只会执行某个线程中的一条指令。线程执行和恢复都依赖程序计数器。
1,Mark-Sweep(标记-清除)算法
先标记出所有需要回收的对象,然后统一回收掉被标记的对象
缺点:标记和清除过程效率不高;
标记和清除后会产生大量不连续的内存碎片,当程序在运行过程中需要分配较大对象的时候,会因为找不到足够的连续内存而提前触发一次垃圾回收动作;
2,Copying(复制)算法
将内存分成大小相等的两块,每次只使用其中的一块,当一块内存用完,就将存活的对象复制到另一块上,然后把上一块空间直接清理掉。
因为新生代中的对象98%都是朝生夕死的,所以将内存按照8:1:1的比例分成了三份Eden,S1, S2,先使用其中的Eden,S1,用尽后将存活对象复制到另一个S2上,然后再等Eden和S2用尽后在复制到S1,如此往复。
3,Mark-Compact(标记-整理)算法
先标记需要清除的对象,再将存活的对象都向一端移动,然后清除掉边界之外的内存 。
4,Generational Collection(分代收集)算法
把java堆分成新生代和老年代,根据各个年代的特点采取最恰当的算法。
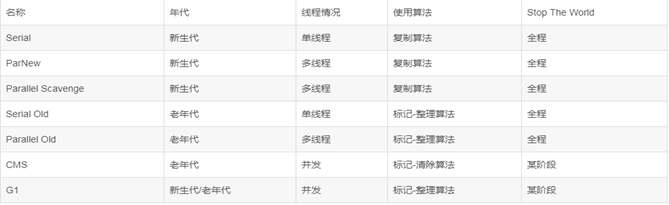
1,Serial/Serial Old
Serial/Serial Old收集器是最基本最古老的收集器,它是一个单线程收集器,并且在它进行垃圾收集时,必须暂停所有用户线程。
Serial收集器是针对新生代的收集器,采用的是Copying算法,Serial Old收集器是针对老年代的收集器,采用的是Mark-Compact算法。
它的优点是实现简单高效,但是缺点是会给用户带来停顿。
2,ParNew
ParNew收集器是Serial收集器的多线程版本,使用多个线程进行垃圾收集。
3,Parallel Scavenge
Parallel Scavenge收集器是一个新生代的多线程收集器(并行收集器),它在回收期间不需要暂停其他用户线程,其采用的是Copying算法,该收集器与前两个收集器有所不同,它主要是为了达到一个可控的吞吐量。
4,Parallel Old
Parallel Old是Parallel Scavenge收集器的老年代版本(并行收集器),使用多线程和Mark-Compact算法。
5,CMS
CMS(Current Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器,它是一种并发收集器,采用的是Mark-Sweep算法。
6,G1
G1收集器是当今收集器技术发展最前沿的成果,它是一款面向服务端应用的收集器,它能充分利用多CPU、多核环境。因此它是一款并行与并发收集器,并且它能建立可预测的停顿时间模型。
各个收集器明细如下:
关于JAVA中怎么实现内存分布问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





