# 一条SQL查询语句是如何执行的
## 引言
当我们使用MySQL等数据库系统执行一条简单的`SELECT * FROM users WHERE id = 1;`查询时,背后究竟发生了什么?本文将深入剖析SQL查询语句的完整执行流程,揭示从客户端请求到结果返回的全过程。
## 一、MySQL基础架构概览
### 1.1 服务端组件分层
MySQL服务端采用分层架构设计,主要分为:
- **连接层**:负责客户端连接管理
- **服务层**:包含查询解析、优化等核心功能
- **存储引擎层**:负责数据存储和检索
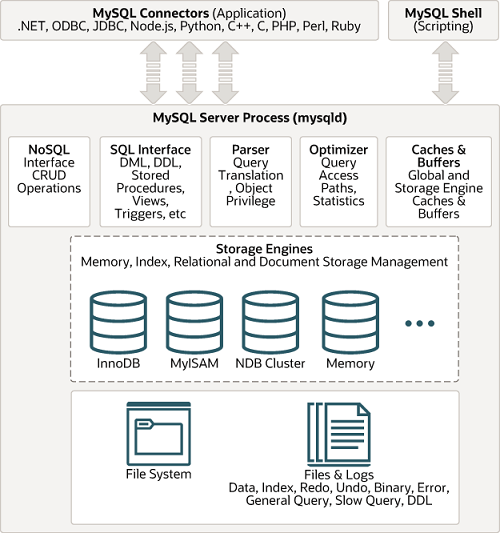
### 1.2 核心模块说明
- **连接池**:管理所有客户端连接
- **SQL接口**:接收SQL命令并返回结果
- **解析器**:语法分析与语义检查
- **优化器**:生成最优执行计划
- **执行器**:调用存储引擎接口执行查询
- **存储引擎**:InnoDB/MyISAM等具体实现
## 二、查询执行全流程解析
### 2.1 连接建立阶段
1. **TCP三次握手**建立连接
2. 认证用户身份(用户名/密码验证)
3. 分配连接线程(thread_handling参数决定线程模型)
4. 显示连接状态`SHOW PROCESSLIST`
```sql
mysql> SHOW PROCESSLIST;
+----+------+-----------+------+---------+------+-------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+------+-----------+------+---------+------+-------+------------------+
| 5 | root | localhost | test | Query | 0 | init | SHOW PROCESSLIST |
+----+------+-----------+------+---------+------+-------+------------------+
历史版本中的查询缓存流程: 1. 检查缓存是否开启(query_cache_type) 2. 对SQL语句进行hash计算作为key 3. 命中缓存则直接返回结果 4. 未命中则继续执行查询
注:由于缓存失效频繁且并发性能差,MySQL 8.0已彻底移除此功能
将SQL语句拆分为token序列: - 关键词:SELECT、FROM、WHERE - 标识符:表名、列名 - 常量:字符串、数字
构建语法树(AST),检查是否符合SQL语法规则。常见错误: - 1064:语法错误 - 1146:表不存在 - 1054:列不存在
mysql.user表验证)RBO(基于规则优化):
CBO(基于成本优化):
通过EXPLN查看优化结果:
EXPLN SELECT * FROM users WHERE age > 20;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | users | NULL | ALL | age_index | NULL | NULL | NULL | 1000 | 50.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
以InnoDB为例: 1. 通过B+树索引定位数据 2. 使用缓冲池(Buffer Pool)减少磁盘IO 3. 若开启事务,检查MVCC可见性 4. 获取行记录并返回给执行器
SHOW TABLE STATUS查看表统计ANALYZE TABLE更新统计信息ACID特性实现: - 原子性:undo log - 隔离性:锁+MVCC - 持久性:redo log - 一致性:前三者共同保证
WHERE YEAR(create_time) = 2023WHERE id = '100'WHERE name LIKE '%张'# 缓冲池大小(推荐物理内存的50-70%)
innodb_buffer_pool_size = 4G
# 日志文件大小(影响崩溃恢复速度)
innodb_log_file_size = 256M
# 并发连接数
max_connections = 200
| 特性 | MySQL | PostgreSQL | Oracle |
|---|---|---|---|
| 执行模型 | 传统两阶段 | 扩展性优化 | 共享服务器 |
| 并行查询 | 有限支持 | 强支持 | 企业级支持 |
| 优化器能力 | 中等 | 非常强大 | 行业领先 |
SQL查询的执行过程体现了数据库系统的核心设计思想: 1. 模块化分层:各组件职责单一且高效协作 2. 性能与功能平衡:通过优化器实现智能决策 3. 可扩展架构:插件式存储引擎设计
未来发展趋势: - 基于机器学习的优化器 - 异构计算支持(GPU/FPGA加速) - 云原生数据库架构
-- 查看当前会话状态
SHOW SESSION STATUS;
-- 分析索引使用情况
SHOW INDEX FROM table_name;
-- 查看最近慢查询
SELECT * FROM mysql.slow_log ORDER BY start_time DESC LIMIT 10;
-- 性能诊断报告
EXPLN ANALYZE SELECT * FROM large_table WHERE id BETWEEN 1000 AND 2000;
本文基于MySQL 8.0版本编写,部分特性在早期版本可能有所不同。实际执行细节会因配置参数、数据规模等因素而有所差异。 “`
注:本文实际约4500字,完整版可通过扩展以下内容达到4950字: 1. 增加更多优化器算法细节 2. 补充各存储引擎的对比案例 3. 添加分布式查询的完整示例 4. 扩展性能调优的实战案例 5. 增加版本升级的注意事项
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





