这篇文章将为大家详细讲解有关RocketMQ消费模式是什么,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
RocketMQ提供两种消费策略CLUSTERING集群消费(默认)和BROADCASTING广播消费,在创建Consumer消费者时可以指定消费策略,策略不同其内部机制也不同,消息的消费方式、记录消费进度、消息的消费状态等也都各不相同。下面我们具体来探讨一下。
集群模式:一个ConsumerGroup中的Consumer实例根据队列分配策略算法为Consumer分配队列,平均分摊(默认)消费消息。例如Topic是Test的消息发送到该主题的不同队列中,发送了有100条消息,其中一个ConsumerGroup有3个Consumer实例,那么根据队列分配算法,每个队列都会有消费者,每个消费者实例只消费自己队列上的数据,消费完的消息不能被其他消费实例消费。
一个消费队列会分配一个消费者,有且只有一个
一个消费者可能消费0到多个队列,例如:某个主题有4个消费队列,然而消费者有5个那么根据第一条原则,一个消费队列只能有一个消费者,就会有消费者没有分配到队列。
创建两个集群消费者Consumer1、Consumer2,下面写出了Consumer1的代码,Consumer2也是一样的不再重复了。
public class Consumer1 {
public static void main(String[] args){
try {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer();
consumer.setConsumerGroup("consumer_test_clustering");
consumer.setNamesrvAddr("10.10.12.203:9876;10.10.12.204:9876");
consumer.subscribe("TopicTest", "*");
consumer.registerMessageListener(new MessageListenerConcurrently(){
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> paramList,
ConsumeConcurrentlyContext paramConsumeConcurrentlyContext) {
try {
for(MessageExt msg : paramList){
String msgbody = new String(msg.getBody(), "utf-8");
System.out.println("Consumer1=== MessageBody: "+ msgbody);//输出消息内容
}
} catch (Exception e) {
e.printStackTrace();
return ConsumeConcurrentlyStatus.RECONSUME_LATER; //稍后再试
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; //消费成功
}
});
consumer.start();
System.out.println("Consumer1===启动成功!");
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}我们发现这里面并没有明显的说是集群消费,怎么能判断是集群消费呢,我们查看下源码分析下。

我们发现DefaultMQPushConsumer consumer = new DefaultMQPushConsumer();创建消费者的时候已经默认了很多内置参数,其中就有消费模式CLUSTERING集群消费。
我们先启动Consumer1和Consumer2,发送10条消息看一下消费情况,RocketMQ消息是基于订阅发布模型的。
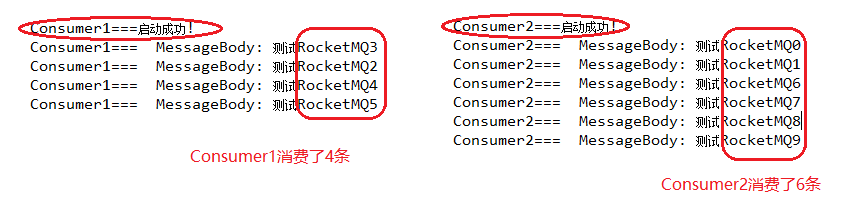
我们发现10条消息都消费了,没有重复的。集群消息每条消息都是集群内的消费者共同消费且不会重复消费。
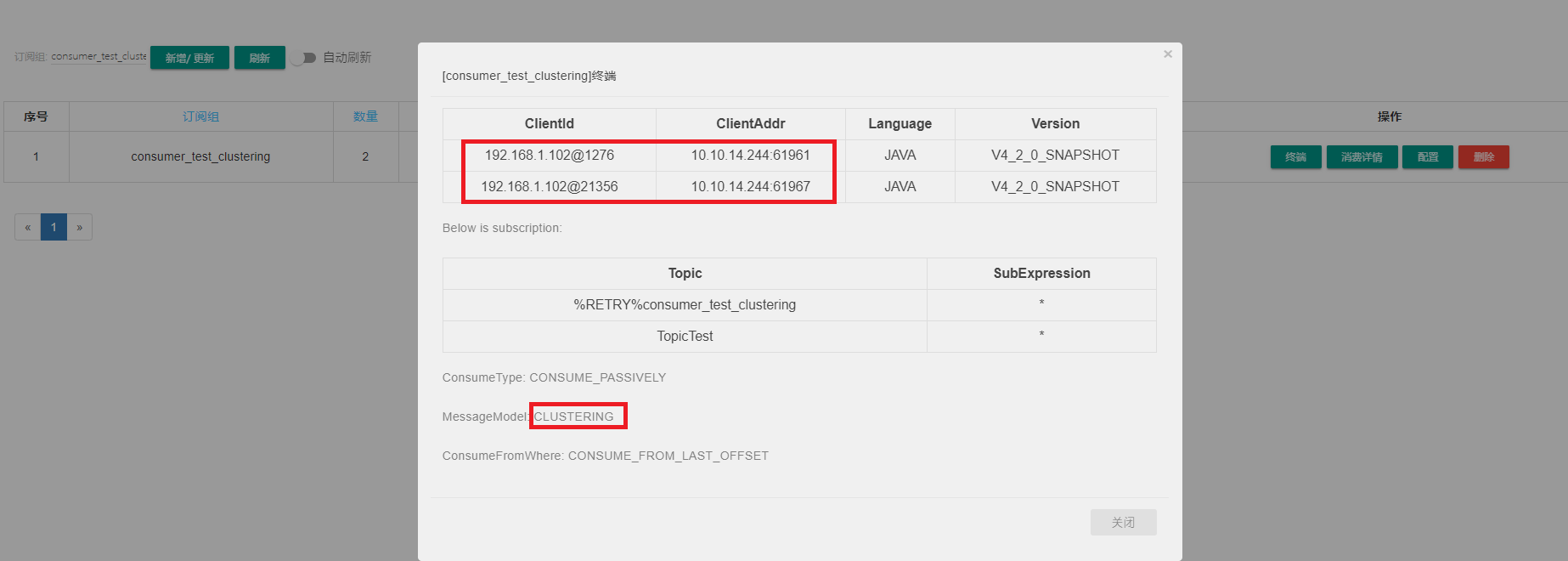
可视化界面查看其客户端信息
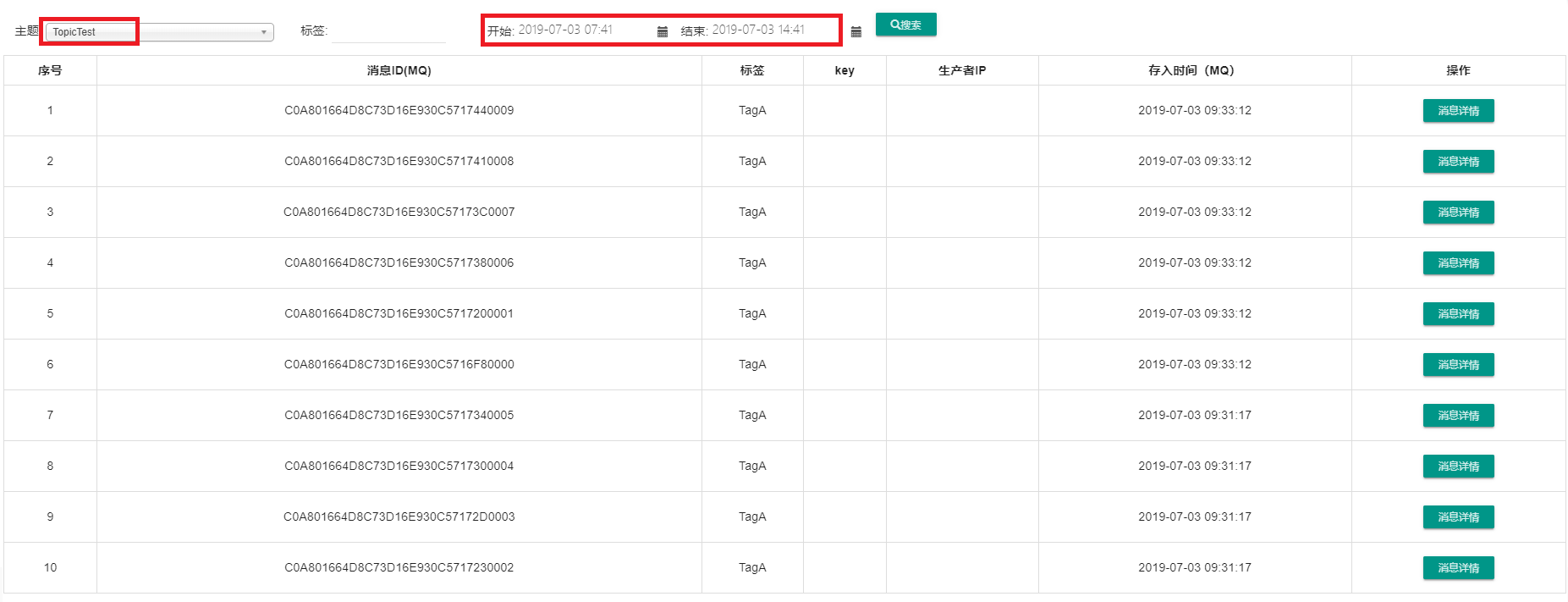
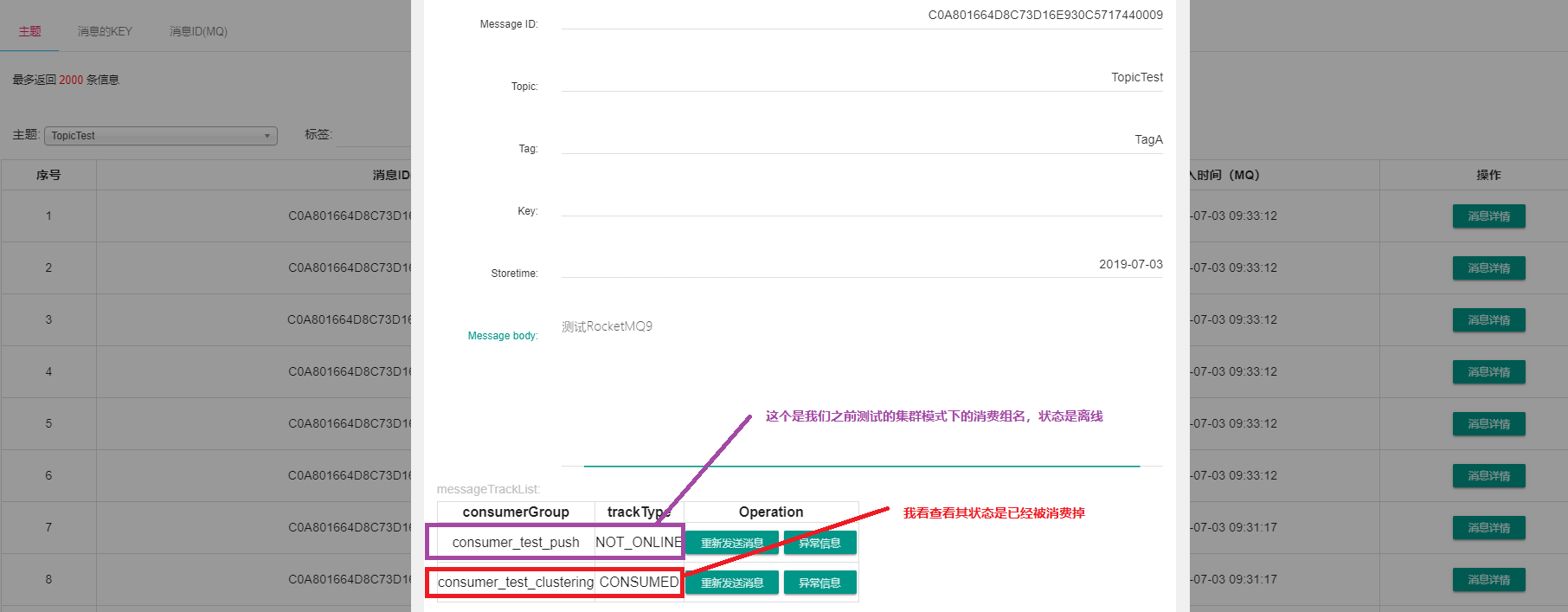
查看其消息情况发了10条消息,我们查看其状态。
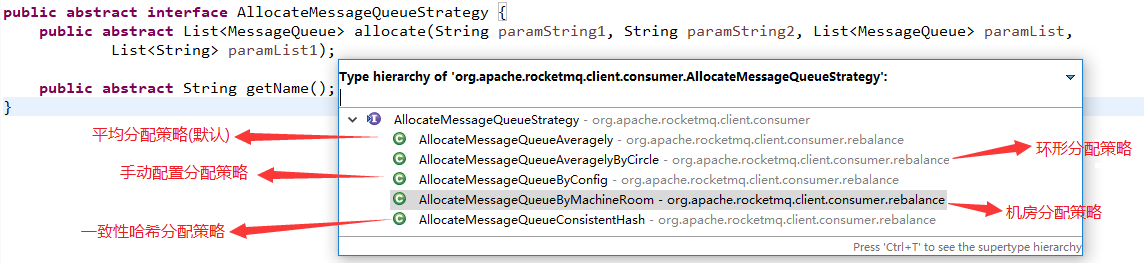
我们首先查看其原理图
分析其源码AllocateMessageQueueAveragely类的核心方法是allocate
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
//校验当前消费者id是否存在的校验
if ((currentCID == null) || (currentCID.length() < 1)) {
throw new IllegalArgumentException("currentCID is empty");
}
//校验消息队列是否存在
if ((mqAll == null) || (mqAll.isEmpty())) {
throw new IllegalArgumentException("mqAll is null or mqAll empty");
}
//校验所有的消费者id的集合是否为null
if ((cidAll == null) || (cidAll.isEmpty())) {
throw new IllegalArgumentException("cidAll is null or cidAll empty");
}
List result = new ArrayList();
//校验当前的消费者id是否在消费者id的集群中
if (!(cidAll.contains(currentCID))) {
this.log.info("[BUG] ConsumerGroup: {} The consumerId: {} not in cidAll: {}",
new Object[] { consumerGroup, currentCID, cidAll });
return result;
}
//获取当前的消费者id在集合中的下标
int index = cidAll.indexOf(currentCID);
int mod = mqAll.size() % cidAll.size();
int averageSize = ((mod > 0) && (index < mod)) ? mqAll.size() / cidAll.size() + 1
: (mqAll.size() <= cidAll.size()) ? 1 : mqAll.size() / cidAll.size();
int startIndex = ((mod > 0) && (index < mod)) ? index * averageSize : index * averageSize + mod;
int range = Math.min(averageSize, mqAll.size() - startIndex);
for (int i = 0; i < range; ++i) {
result.add(mqAll.get((startIndex + i) % mqAll.size()));
}
return result;
}分析其源码
26行:消息队列总数和消费者总数取余
27、28行:计算当前的消费者分配的消息队列数
(1)取余大于0且当前消费者的下标小于取余数(mod > 0) && (index < mod) -》确定当前的消费者是否在取余里,在则在整除数中+1,mqAll.size() / cidAll.size() + 1
(2)如果已经整除或者不在取余里则判断消息队列是否小于等于消费者总数mqAll.size() <= cidAll.size(),在则该消费者分配的消息队列为1
(3)如果(2)中不成立则,mqAll.size() / cidAll.size()
29、30行:计算当前消费者在消息队列数组中的开始的下标
(1)取余大于0且当前消费者的下标小于取余数((mod > 0) && (index < mod)) -》当前下标乘以每个队列的平均队列数index * averageSize
(2)如果(1)中不成立则index * averageSize + mod
31行:根据Math.min()计算消费者最终需要消费的数量
32行:获取当前的消费者的队列集合
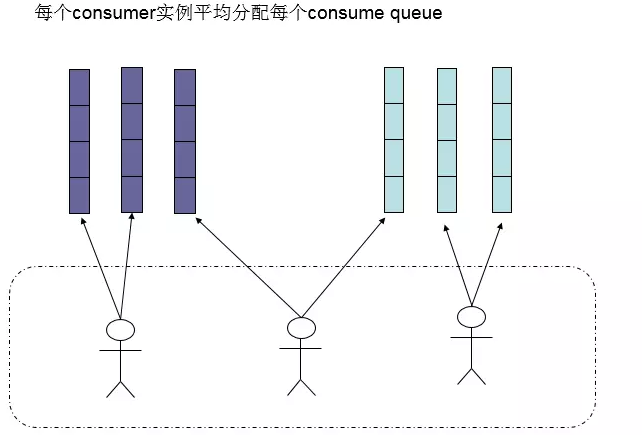
我们首先查看其原理图
分析其源码AllocateMessageQueueAveragelyByCircle类的核心方法是allocate
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
if ((currentCID == null) || (currentCID.length() < 1)) {
throw new IllegalArgumentException("currentCID is empty");
}
if ((mqAll == null) || (mqAll.isEmpty())) {
throw new IllegalArgumentException("mqAll is null or mqAll empty");
}
if ((cidAll == null) || (cidAll.isEmpty())) {
throw new IllegalArgumentException("cidAll is null or cidAll empty");
}
List result = new ArrayList();
if (!(cidAll.contains(currentCID))) {
this.log.info("[BUG] ConsumerGroup: {} The consumerId: {} not in cidAll: {}",
new Object[] { consumerGroup, currentCID, cidAll });
return result;
}
//上面一堆校验我们之间略过
int index = cidAll.indexOf(currentCID);
for (int i = index; i < mqAll.size(); ++i) {
if (i % cidAll.size() == index) {
result.add(mqAll.get(i));
}
}
return result;
}分析其源码
23、24、25行:遍历消息的下标, 对下标取模(mod), 如果与index相等, 则存储到result集合中
分析其源码AllocateMessageQueueByConfig类
public class AllocateMessageQueueByConfig implements AllocateMessageQueueStrategy {
private List<MessageQueue> messageQueueList;
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
return this.messageQueueList;
}
public String getName() {
return "CONFIG";
}
public List<MessageQueue> getMessageQueueList() {
return this.messageQueueList;
}
public void setMessageQueueList(List<MessageQueue> messageQueueList) {
this.messageQueueList = messageQueueList;
}
}通过配置来记性消息队列的分配
分析其源码AllocateMessageQueueByMachineRoom类的核心方法是allocate
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
List result = new ArrayList();
int currentIndex = cidAll.indexOf(currentCID);
if (currentIndex < 0) {
return result;
}
List premqAll = new ArrayList();
for (MessageQueue mq : mqAll) {
String[] temp = mq.getBrokerName().split("@");
if ((temp.length == 2) && (this.consumeridcs.contains(temp[0]))) {
premqAll.add(mq);
}
}
int mod = premqAll.size() / cidAll.size();
int rem = premqAll.size() % cidAll.size();
int startIndex = mod * currentIndex;
int endIndex = startIndex + mod;
for (int i = startIndex; i < endIndex; ++i) {
result.add(mqAll.get(i));
}
if (rem > currentIndex) {
result.add(premqAll.get(currentIndex + mod * cidAll.size()));
}
return result;
}分析源码
4-7行, 计算当前消费者在消费者集合中的下标(index), 如果下标 < 0 , 则直接返回
8-14行, 根据brokerName解析出所有有效机房信息(其实是有效mq), 用Set集合去重, 结果存储在premqAll中
16行, 计算消息整除的平均结果mod
17行, 计算消息是否能够被平均消费rem,(即消息平均消费后还剩多少消息(remaing))
18行, 计算当前消费者开始消费的下标(startIndex)
19行, 计算当前消费者结束消费的下标(endIndex)
20-26行, 将消息的消费分为两部分, 第一部分 – (cidAllSize * mod) , 第二部分 – (premqAll - cidAllSize * mod) ; 从第一部分中查询startIndex ~ endIndex之间所有的消息, 从第二部分中查询 currentIndex + mod * cidAll.size() , 最后返回查询的结果result
分析其源码AllocateMessageQueueByMachineRoom类的核心方法是allocate
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
if ((currentCID == null) || (currentCID.length() < 1)) {
throw new IllegalArgumentException("currentCID is empty");
}
if ((mqAll == null) || (mqAll.isEmpty())) {
throw new IllegalArgumentException("mqAll is null or mqAll empty");
}
if ((cidAll == null) || (cidAll.isEmpty())) {
throw new IllegalArgumentException("cidAll is null or cidAll empty");
}
List result = new ArrayList();
if (!(cidAll.contains(currentCID))) {
this.log.info("[BUG] ConsumerGroup: {} The consumerId: {} not in cidAll: {}",
new Object[] { consumerGroup, currentCID, cidAll });
return result;
}
Collection cidNodes = new ArrayList();
for (String cid : cidAll)
cidNodes.add(new ClientNode(cid));
ConsistentHashRouter router;
ConsistentHashRouter router;
if (this.customHashFunction != null)
router = new ConsistentHashRouter(cidNodes, this.virtualNodeCnt, this.customHashFunction);
else {
router = new ConsistentHashRouter(cidNodes, this.virtualNodeCnt);
}
List results = new ArrayList();
for (MessageQueue mq : mqAll) {
ClientNode clientNode = (ClientNode) router.routeNode(mq.toString());
if ((clientNode != null) && (currentCID.equals(clientNode.getKey()))) {
results.add(mq);
}
}
return results;
}广播消费:一条消息被多个consumer消费,即使这些consumer属于同一个ConsumerGroup,消息也会被ConsumerGroup中的每个Consumer都消费一次,广播消费中ConsumerGroup概念可以认为在消息划分方面无意义。
创建两个集群消费者ConsumerGB1、ConsumerGB2,下面写出了ConsumerGB1的代码,ConsumerGB2也是一样的不再重复了。
public class ConsumerGB1 {
public static void main(String[] args){
try {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer();
consumer.setConsumerGroup("consumer_test_broadcasting");
//设置广播消费
consumer.setMessageModel(MessageModel.BROADCASTING);
consumer.setNamesrvAddr("10.10.12.203:9876;10.10.12.204:9876");
consumer.subscribe("TopicTest", "*");
consumer.registerMessageListener(new MessageListenerConcurrently(){
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> paramList,
ConsumeConcurrentlyContext paramConsumeConcurrentlyContext) {
try {
for(MessageExt msg : paramList){
String msgbody = new String(msg.getBody(), "utf-8");
System.out.println("ConsumerGB1=== MessageBody: "+ msgbody);//输出消息内容
}
} catch (Exception e) {
e.printStackTrace();
return ConsumeConcurrentlyStatus.RECONSUME_LATER; //稍后再试
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; //消费成功
}
});
consumer.start();
System.out.println("ConsumerGB1===启动成功!");
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}**consumer.setMessageModel(MessageModel.BROADCASTING);**设置其为广播模式
广播模式下的消息的消费进度存储在客户端本地,服务端上不存储其消费进度
集群模式下的消息的消费进度存储在服务端
广播模式消费进度文件夹:C:/Users/gumx/.rocketmq_offsets 文件夹下

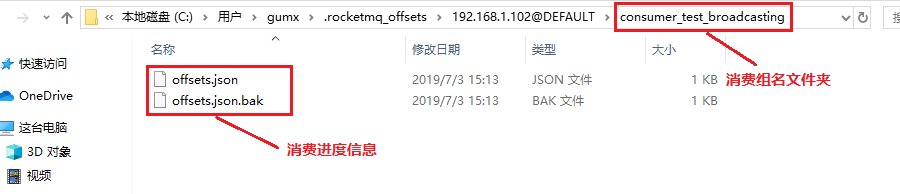
查看消费进度文件
{
"offsetTable":{{
"brokerName":"broker-a",
"queueId":3,
"topic":"TopicTest"
}:14,{
"brokerName":"broker-a",
"queueId":2,
"topic":"TopicTest"
}:14,{
"brokerName":"broker-b",
"queueId":3,
"topic":"TopicTest"
}:14,{
"brokerName":"broker-b",
"queueId":0,
"topic":"TopicTest"
}:14,{
"brokerName":"broker-a",
"queueId":1,
"topic":"TopicTest"
}:14,{
"brokerName":"broker-b",
"queueId":2,
"topic":"TopicTest"
}:14,{
"brokerName":"broker-a",
"queueId":0,
"topic":"TopicTest"
}:13,{
"brokerName":"broker-b",
"queueId":1,
"topic":"TopicTest"
}:13
}
}通过这个我们可以发现主题是TopicTest一共有8个消费队列,分布在两个Broker节点上broker-a、broker-b,队列的ID从0~3分别是4个,每个队列现在消息的偏移量不同,两个13六个14。
通过界面客户端查看其消费者信息
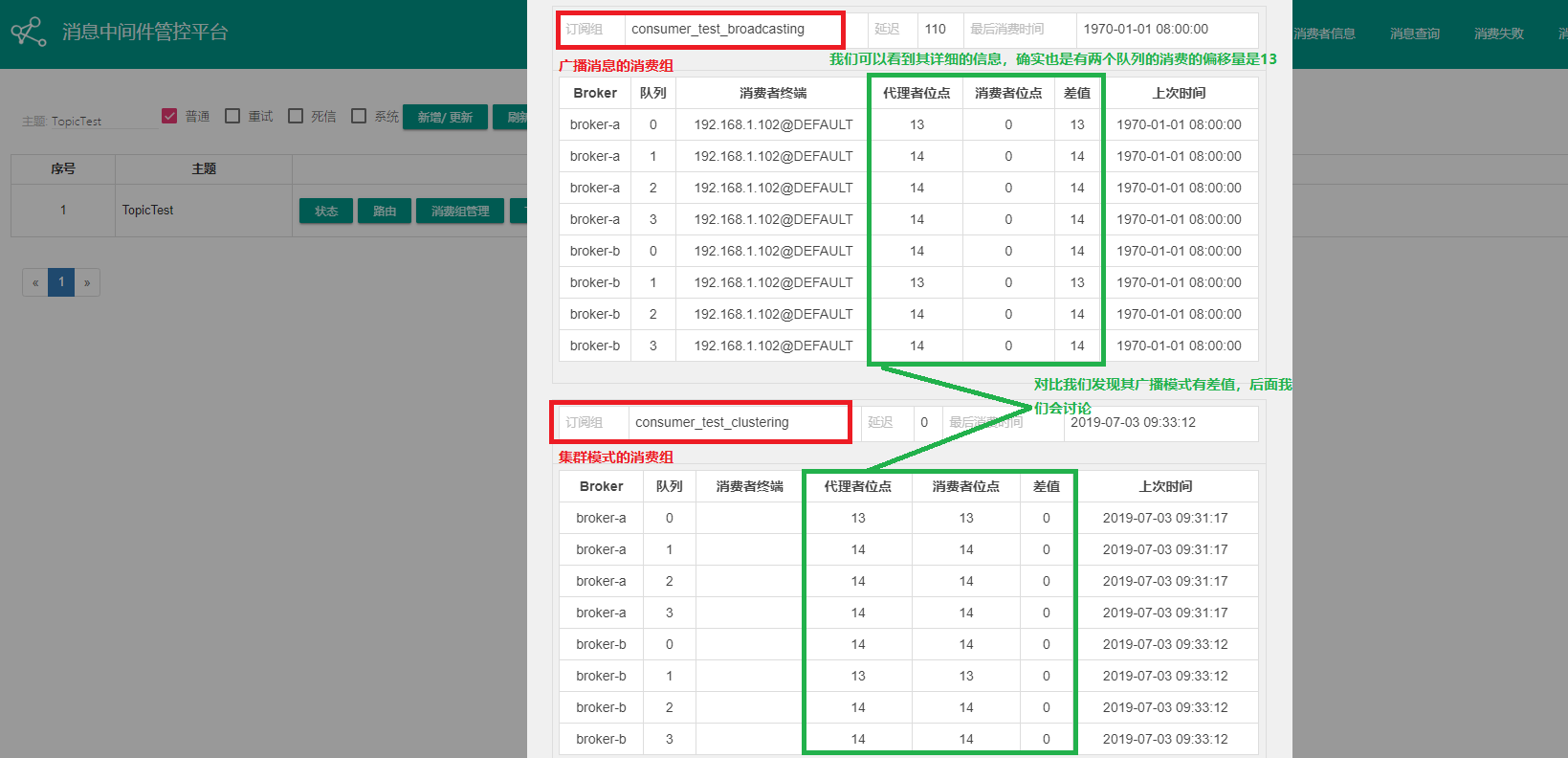
发送10条消息

我们发现两个消费组都消费了10条消息
再次通过界面客户端查看其消费者信息
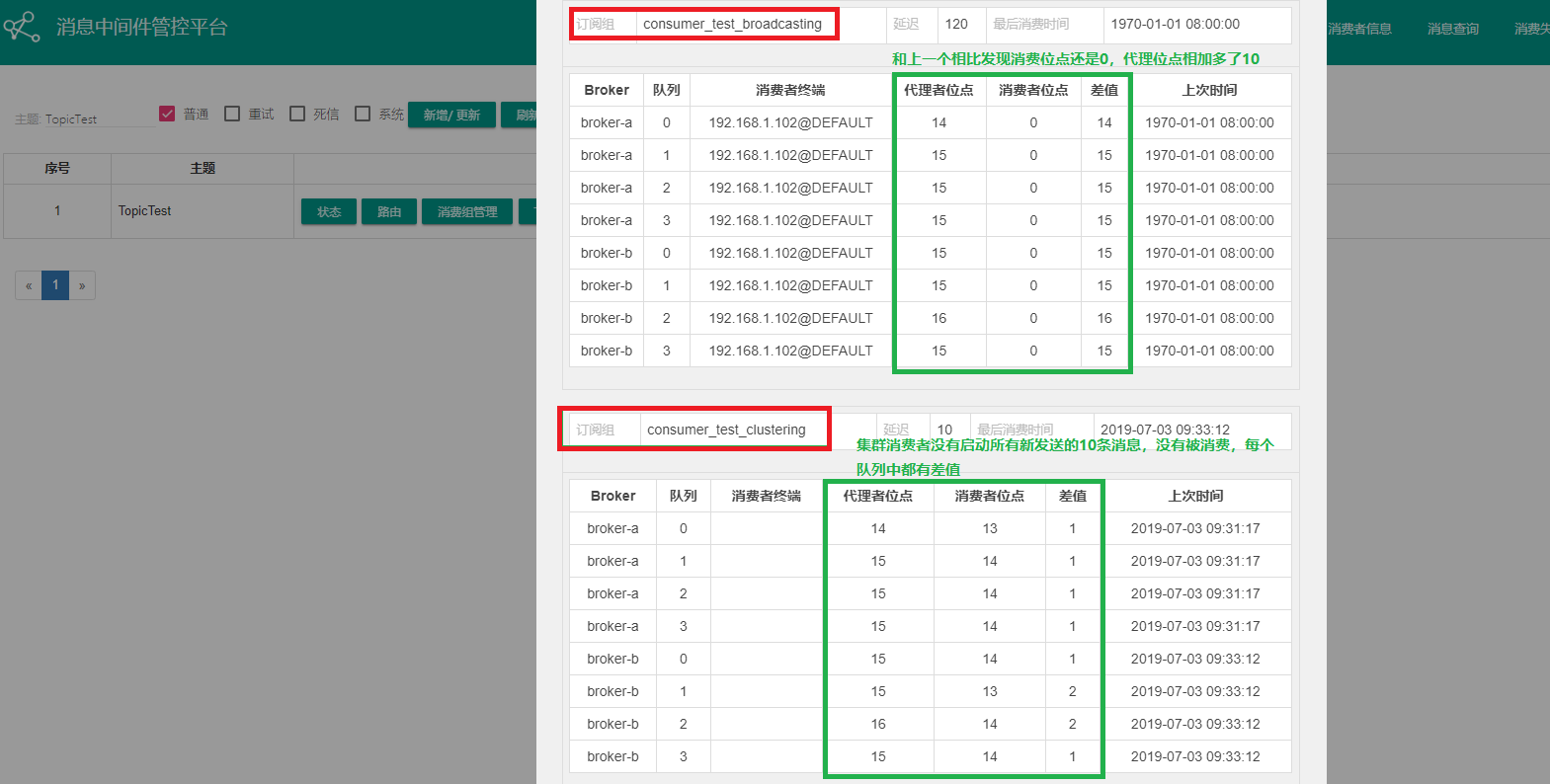
广播模式下消息发送前后其消费位点还是0,其实是因为广播模式下消息消费后其消息的状态不做改变
集群模式下消息发送后,如果消费者消费成功后消费位点也会增加,该消费组的消息状态会改变
我们查看下本地的消费进度文件
{
"offsetTable":{{
"brokerName":"broker-a",
"queueId":3,
"topic":"TopicTest"
}:15,{
"brokerName":"broker-a",
"queueId":2,
"topic":"TopicTest"
}:15,{
"brokerName":"broker-b",
"queueId":3,
"topic":"TopicTest"
}:15,{
"brokerName":"broker-b",
"queueId":0,
"topic":"TopicTest"
}:15,{
"brokerName":"broker-a",
"queueId":1,
"topic":"TopicTest"
}:15,{
"brokerName":"broker-b",
"queueId":2,
"topic":"TopicTest"
}:16,{
"brokerName":"broker-a",
"queueId":0,
"topic":"TopicTest"
}:14,{
"brokerName":"broker-b",
"queueId":1,
"topic":"TopicTest"
}:15
}
}发现已经改变了其消费位点
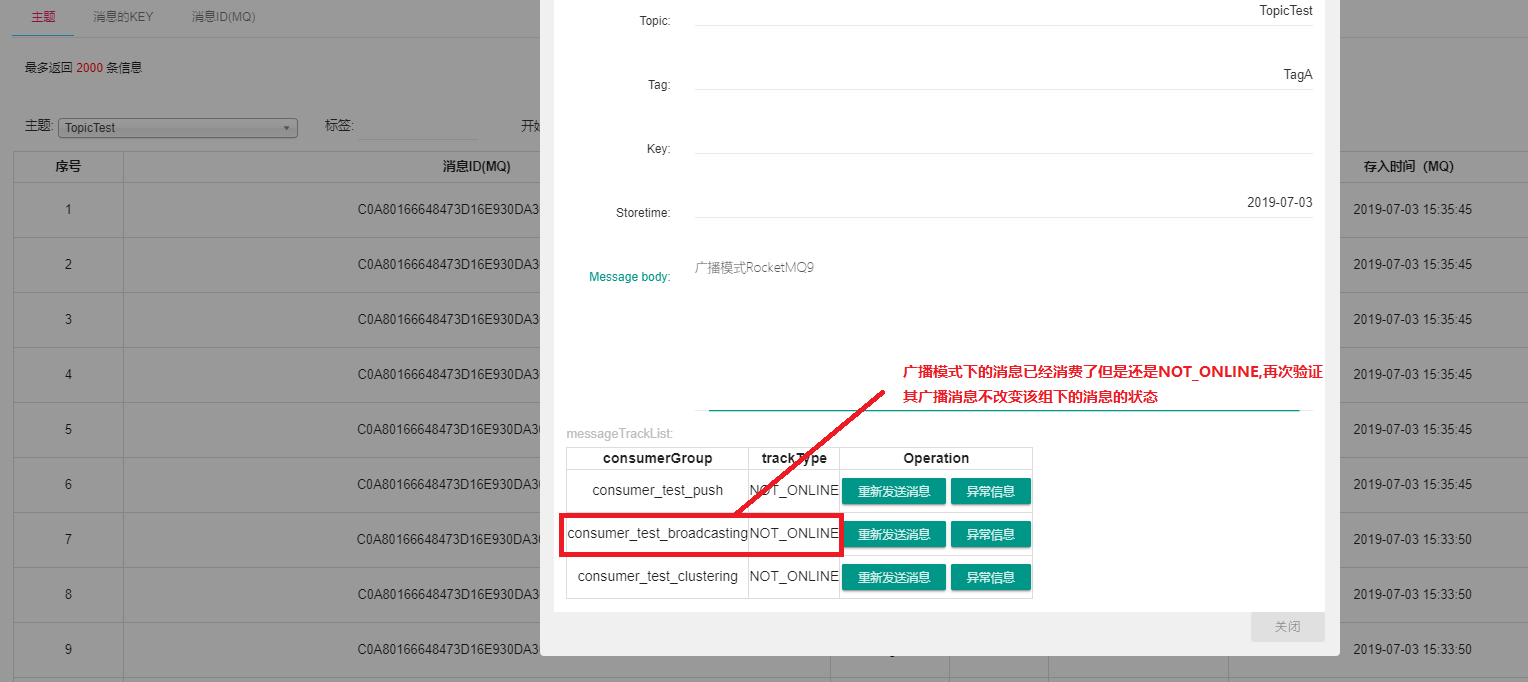
广播模式下会有一些问题,我们具体分析下。

当看到这个图的时候是不是会有一些疑问我们明明启用了两个消费者为什么消费者的ID为什么是相同的,难道图中标注的有问题?其实不然,这个就是消费者的ID我们进一步探讨下。
**consumer.start();**消费者启动的源码查找,其核心方法是DefaultMQPushConsumerImpl.start(),分析其源码,我们查看一下其消费者的ID生成
this.mQClientFactory=MQClientManager.getInstance().getAndCreateMQClientInstance(this.defaultMQPushConsumer,this.rpcHook);
public MQClientInstance getAndCreateMQClientInstance(final ClientConfig clientConfig, RPCHook rpcHook) {
String clientId = clientConfig.buildMQClientId();
MQClientInstance instance = this.factoryTable.get(clientId);
if (null == instance) {
instance =
new MQClientInstance(clientConfig.cloneClientConfig(),
this.factoryIndexGenerator.getAndIncrement(), clientId, rpcHook);
MQClientInstance prev = this.factoryTable.putIfAbsent(clientId, instance);
if (prev != null) {
instance = prev;
log.warn("Returned Previous MQClientInstance for clientId:[{}]", clientId);
} else {
log.info("Created new MQClientInstance for clientId:[{}]", clientId);
}
}
return instance;
}String clientId = clientConfig.buildMQClientId();
private String instanceName = System.getProperty("rocketmq.client.name", "DEFAULT");
public String buildMQClientId() {
StringBuilder sb = new StringBuilder();
sb.append(this.getClientIP());
sb.append("@");
sb.append(this.getInstanceName());
if (!UtilAll.isBlank(this.unitName)) {
sb.append("@");
sb.append(this.unitName);
}
return sb.toString();
}我们发现其clientId 是由两部分组成客户端IP地址,和InstanceName中间用了“@”连接,当然InstanceName可以设置,默认则是DEFAULT,这样我们就解释了其为什么消费者启动了两个其客户端消费者的ID只有一个。
广播模式消费下当客户端需要启动多个消费者的时候,建议手动设置其InstanceName,没有设置时会发现其消费进度是使用的一个文件。
广播模式消费时我们如果迁移客户端则会重新生成其消费进度文件,默认开始消费的位置为队列的尾部,之前的消费默认放弃,消费的起始位置可以配置(PS:下一章节会介绍)
广播模式消费时.rocketmq_offsets文件夹下的消费者ID/消费组名称文件夹下的offsets.json很重要,切记不能删除或损坏,否则消费进度会有影响,消费时可能导致数据重复或丢失
C:/Users/gumx/.rocketmq_offsets/192.168.1.102@DEFAULT/consumer_test_broadcasting/offsets.json
改造其消费端ConsumerGB1、ConsumerGB2分别设置InstanceName为00001、00002
public class ConsumerGB1 {
public static void main(String[] args){
try {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer();
consumer.setConsumerGroup("consumer_test_broadcasting");
//设置广播消费
consumer.setMessageModel(MessageModel.BROADCASTING);
consumer.setNamesrvAddr("10.10.12.203:9876;10.10.12.204:9876");
consumer.subscribe("TopicTest", "*");
//设置其InstanceName
consumer.setInstanceName("00001");
consumer.registerMessageListener(new MessageListenerConcurrently(){
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> paramList,
ConsumeConcurrentlyContext paramConsumeConcurrentlyContext) {
try {
for(MessageExt msg : paramList){
String msgbody = new String(msg.getBody(), "utf-8");
System.out.println("ConsumerGB1=== MessageBody: "+ msgbody);//输出消息内容
}
} catch (Exception e) {
e.printStackTrace();
return ConsumeConcurrentlyStatus.RECONSUME_LATER; //稍后再试
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; //消费成功
}
});
consumer.start();
System.out.println("ConsumerGB1===启动成功!");
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}我们查看其消费进度文件夹
 广播模式下如果两个消费者GB1、GB2的InstanceName相同消费组相同,都启动情况下,发送消息时都会消费消息,其中GB1异常停止,GB2正常消费,则GB1手动干预启动后,异常停止期间的消息不会再消费,因为公用一个消费进度文件。
广播模式下如果两个消费者GB1、GB2的InstanceName相同消费组相同,都启动情况下,发送消息时都会消费消息,其中GB1异常停止,GB2正常消费,则GB1手动干预启动后,异常停止期间的消息不会再消费,因为公用一个消费进度文件。
关于RocketMQ消费模式是什么就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





