[TOC]
1、Spark 1.0版本以后,Spark官方推出了Spark SQL。其实最早使用的,都是Hadoop自己的Hive查询引擎;比如MR2,我们底层都是运行的MR2模型,底层都是基于Hive的查询引擎。
2、后来Spark提供了Shark;再后来Shark被淘汰(Shark制约了Spark SQL的整体发展),推出了Spark SQL。Shark的性能比Hive就要高出一个数量级,而Spark SQL的性能又比Shark高出一个数量级。
3、SparkSQL的前身是Shark,给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,Hive应运而生,它是当时唯一运行在Hadoop上的SQL-on-Hadoop工具。但是MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,降低的运行效率,为了提高SQL-on-Hadoop的效率,大量的SQL-on-Hadoop工具开始产生,其中表现较为突出的是:
MapR的Drill
Cloudera的Impala
Shark4、但是Hive有个致命的缺陷,就是它的底层基于MR2,而MR2的shuffle又是基于磁盘的,因此导致Hive的性能异常低下。经常出现复杂的SQL ETL,要运行数个小时,甚至数十个小时的情况。
5、Spark推出了Shark,Shark与Hive实际上还是紧密关联的,Shark底层很多东西还是依赖于Hive,但是修改了内存管理、物理计划、执行三个模块,底层使用Spark的基于内存的计算模型,从而让性能比Hive提升了数倍到上百倍。
1、但是,随着Spark的发展,对于野心勃勃的Spark团队来说,Shark对于Hive的太多依赖(如采用Hive的语法解析器、查询优化器等等),制约了Spark的One Stack Rule Them All的既定方针,制约了Spark各个组件的相互集成,所以提出了SparkSQL项目。SparkSQL抛弃原有Shark的代码,汲取了Shark的一些优点,如内存列存储(In-Memory Columnar Storage)、Hive兼容性等,重新开发了SparkSQL代码;由于摆脱了对Hive的依赖性,SparkSQL无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便,真可谓“退一步,海阔天空”。
2、Spark SQL的特点
1)、支持多种数据源:Hive、RDD、Parquet、JSON、JDBC等。
2)、多种性能优化技术:in-memory columnar storage、byte-code generation、cost model动态评估等。
3)、组件扩展性:对于SQL的语法解析器、分析器以及优化器,用户都可以自己重新开发,并且动态扩展。
数据兼容方面 不但兼容Hive,还可以从RDD、parquet文件、JSON文件中获取数据,未来版本甚至支持获取RDBMS数据以及cassandra等NOSQL数据;
性能优化方面 除了采取In-Memory Columnar Storage、byte-code generation等优化技术外、将会引进Cost Model对查询进行动态评估、获取最佳物理计划等等;
组件扩展方面 无论是SQL的语法解析器、分析器还是优化器都可以重新定义,进行扩展。
2014年6月1日Shark项目和SparkSQL项目的主持人Reynold Xin宣布:停止对Shark的开发,团队将所有资源放SparkSQL项目上,至此,Shark的发展画上了句话,但也因此发展出两个直线:SparkSQL和Hive on Spark。
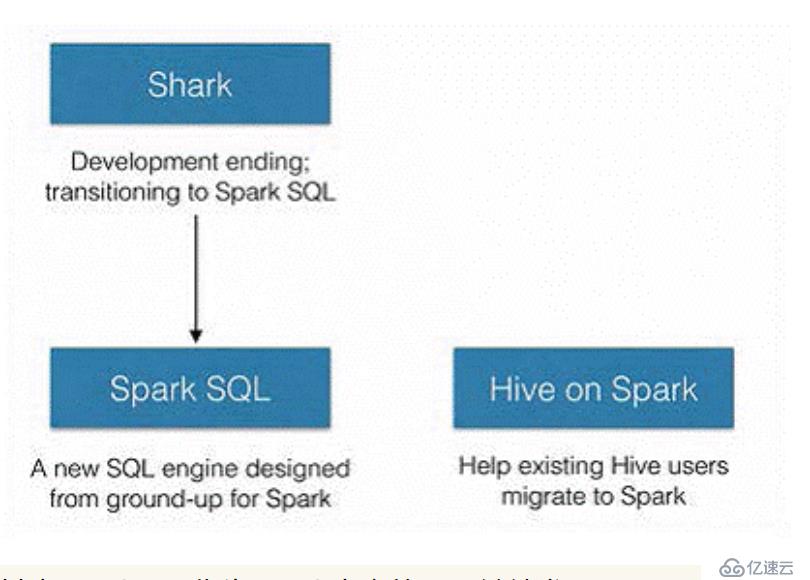
其中SparkSQL作为Spark生态的一员继续发展,而不再受限于Hive,只是兼容Hive;而Hive on Spark是一个Hive的发展计划,该计划将Spark作为Hive的底层引擎之一,也就是说,Hive将不再受限于一个引擎,可以采用Map-Reduce、Tez、Spark等引擎。
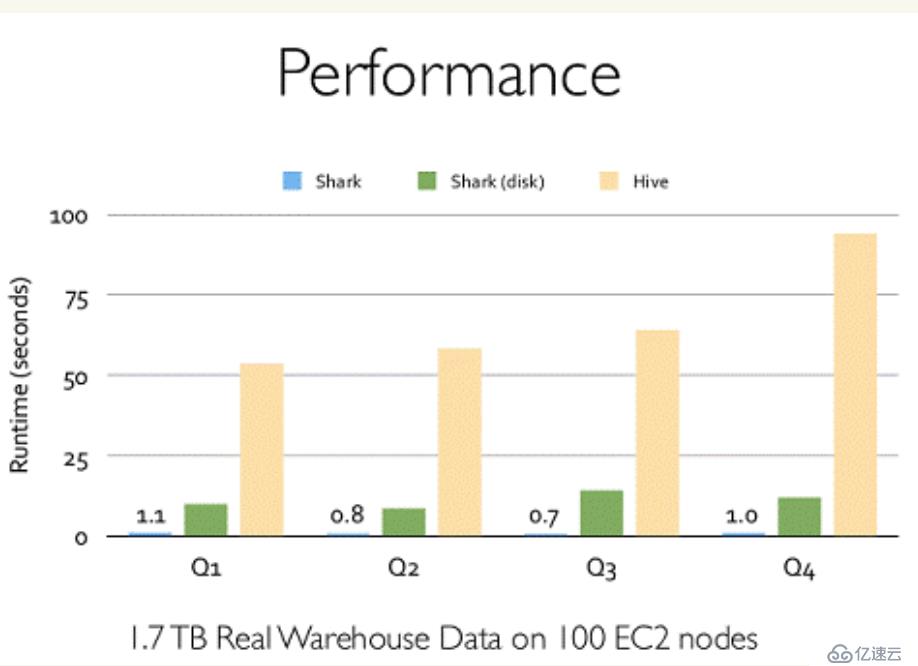
Shark的出现,使得SQL-on-Hadoop的性能比Hive有了10-100倍的提高:
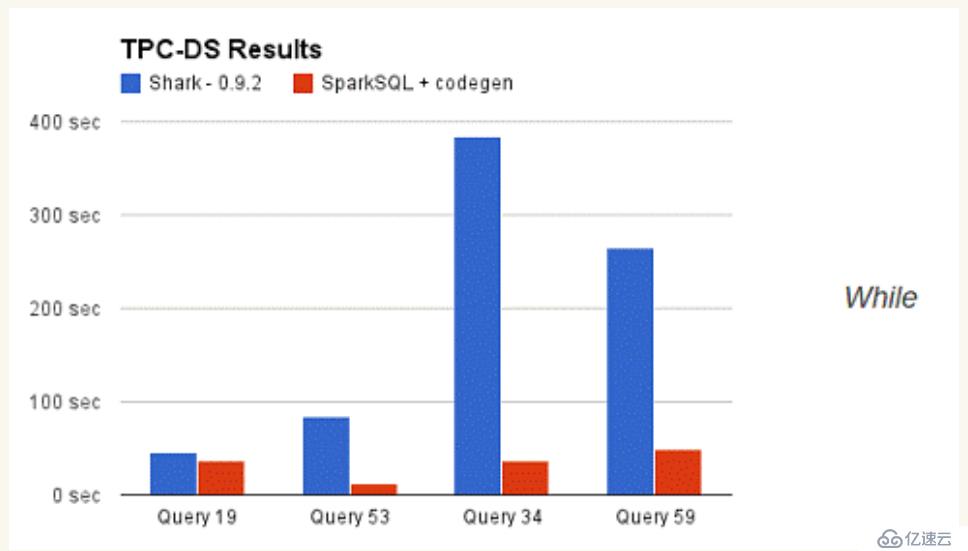
那么,摆脱了Hive的限制,SparkSQL的性能又有怎么样的表现呢?虽然没有Shark相对于Hive那样瞩目地性能提升,但也表现得非常优异:
SparkSQL的表数据在内存中存储不是采用原生态的JVM对象存储方式,而是采用内存列存储,如下图所示:
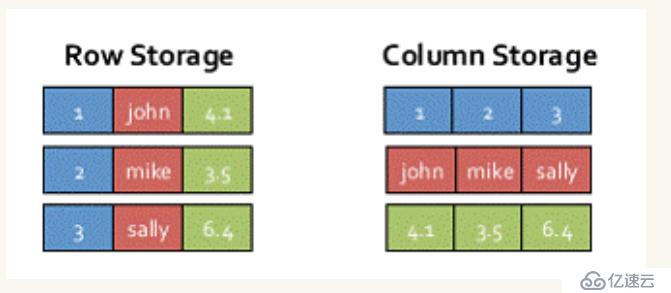
1、该存储方式无论在空间占用量和读取吞吐率上都占有很大优势。
对于原生态的JVM对象存储方式,每个对象通常要增加12-16字节的额外开销,对于一个270MB的数据,使用这种方式读入内存,要使用970MB左右的内存空间(通常是2~5倍于原生数据空间);另外,使用这种方式,每个数据记录产生一个JVM对象,如果是大小为200B的数据记录,32G的堆栈将产生1.6亿个对象,这么多的对象,对于GC来说,可能要消耗几分钟的时间来处理(JVM的垃圾收集时间与堆栈中的对象数量呈线性相关)。显然这种内存存储方式对于基于内存计算的Spark来说,很昂贵也负担不起。
2、对于内存列存储来说,将所有原生数据类型的列采用原生数组来存储,将Hive支持的复杂数据类型(如array、map等)先序化后并接成一个字节数组来存储。这样,每个列创建一个JVM对象,从而导致可以快速的GC和紧凑的数据存储;额外的,还可以使用低廉CPU开销的高效压缩方法(如字典编码、行长度编码等压缩方法)降低内存开销;更有趣的是,对于分析查询中频繁使用的聚合特定列,性能会得到很大的提高,原因就是这些列的数据放在一起,更容易读入内存进行计算。
在数据库查询中有一个昂贵的操作是查询语句中的表达式,主要是由于JVM的内存模型引起的。
Spark SQL在其catalyst模块的expressions中增加了codegen模块,对于SQL语句中的计算表达式,比如select num + num from t这种的sql,就可以使用动态字节码生成技术来优化其性能。
另外,SparkSQL在使用Scala编写代码的时候,尽量避免低效的、容易GC的代码;尽管增加了编写代码的难度,但对于用户来说,还是使用统一的接口,没受到使用上的困难。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





