今天就跟大家聊聊有关如何自定义ForkJoinPool提升并行流 ParallelStream执行速度,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
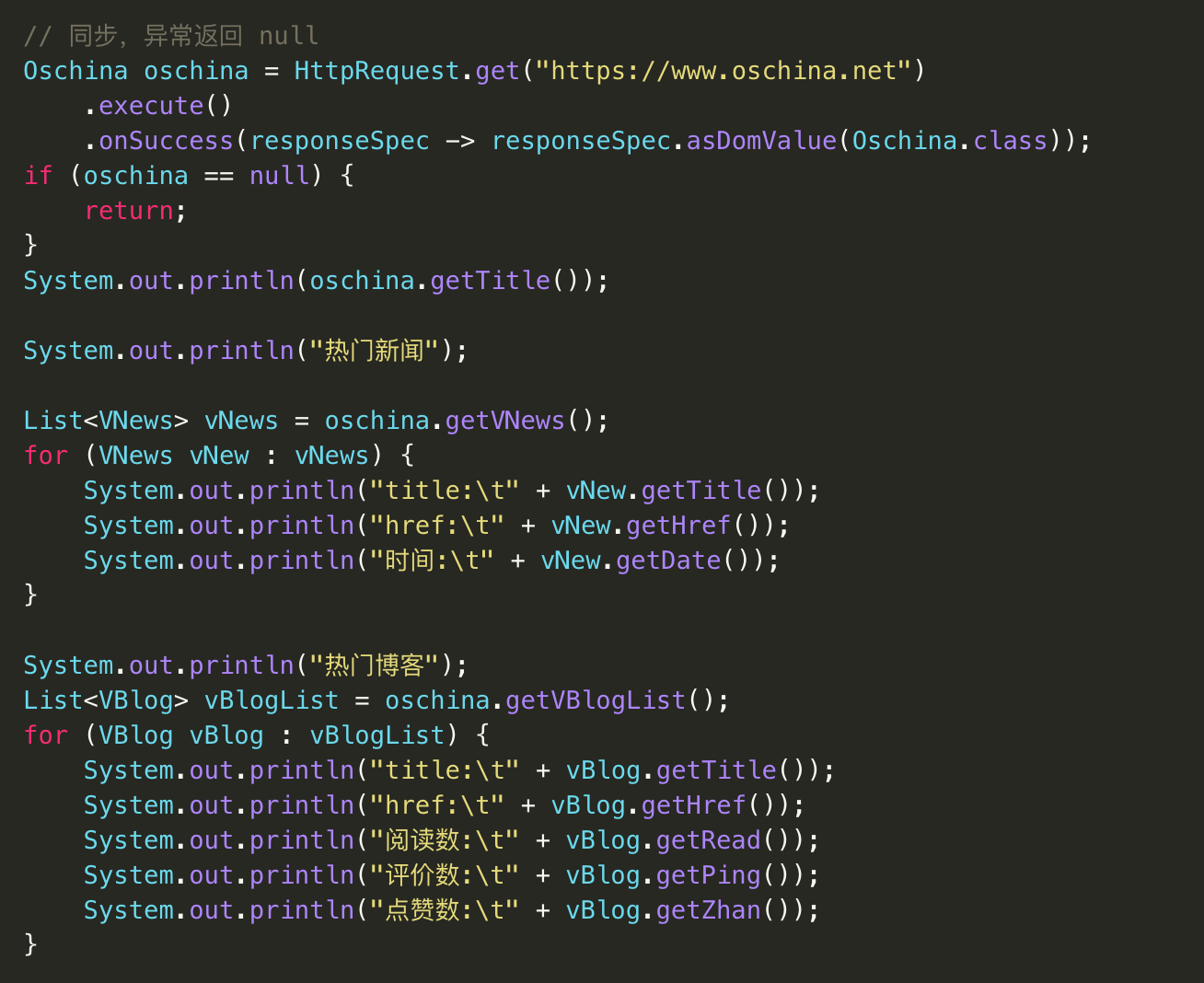
在 java8 中 添加了流Stream,可以让你以一种声明的方式处理数据。使用起来非常简单优雅。ParallelStream 则是一个并行执行的流,采用 ForkJoinPool 并行执行任务,提高执行速度。<br> <br> 下面我们看看2个简单的示例:
Arrays.asList(1,2,3,4,5,6)
.parallelStream()
.forEach((value) -> {
String name = Thread.currentThread().getName();
System.out.println("示例1 Thread:" + name + " value:" + value);
});<a name="951e1e2c"></a>
Stream.of(1,2,3,4,5,6)
.parallel()
.forEach((value) -> {
String name = Thread.currentThread().getName();
System.out.println("示例2 Thread:" + name + " value:" + value);
});笔者最近在做一些爬虫相关的业务,其核心工具已开源 mica-http:https://gitee.com/596392912/mica/tree/master/mica-http ,经过2个版本的迭代已经发展成了一个强大非账号爬虫利器,赶紧来试试吧。

我们采集了大量的代理 ip 用来供爬虫使用,其中有个定时任务每 5 分钟去检测代理是否失效,代理 ip 检测比较费时,我们给每个检测的请求 设定了 2s 的超时,这样单线程的话 1000 个 ip 就得消耗半个多小时,当然笔者在校验的时候采用的 parallel Stream 简化开发。
然后发现效果并不明显,代理 ip 数量上来之后 5 分钟完全检测不完,导致任务堆积。明明用了并发流为什么没有明显的提高执行速度呢?
下面我们来看看刚刚的“示例”打印出的信息:
示例1 Thread:main value:4 示例1 Thread:ForkJoinPool.commonPool-worker-2 value:1 示例1 Thread:main value:6 示例1 Thread:ForkJoinPool.commonPool-worker-2 value:5 示例1 Thread:main value:3 示例1 Thread:ForkJoinPool.commonPool-worker-1 value:2 示例2 Thread:main value:4 示例2 Thread:ForkJoinPool.commonPool-worker-3 value:3 示例2 Thread:ForkJoinPool.commonPool-worker-2 value:5 示例2 Thread:ForkJoinPool.commonPool-worker-4 value:1 示例2 Thread:ForkJoinPool.commonPool-worker-5 value:2 示例2 Thread:ForkJoinPool.commonPool-worker-1 value:6
我们可以看到 Parallel Stream,默认采用的是一个 ForkJoinPool.commonPool 的线程池,这样我们就算使用了 Parallel Stream, 整个 jvm 共用一个 common pool 线程池,一不小心就任务堆积了,在校验代理 ip 的时候我们还有采集代理等其他的任务中也大量使用了并发流, 这样也就印证了为什么会任务堆积了。
使用自定义 ForkJoinPool 执行速度。示例代码如下:
// 示例:自定义线程池 ForkJoinPool forkJoinPool = new ForkJoinPool(8); // 这里是从数据库里查出来的一批代理 ip List<proxylist> records = new ArrayList<>(); // 找出失效的代理 ip List<string> needDeleteList = forkJoinPool.submit(() -> records.parallelStream() .map(ProxyList::getIpPort) .filter(IProxyListTask::isFailed) .collect(Collectors.toList()) ).join(); // 删除失效的代理
整个代码依然比较优雅,在使用自定义的 ForkJoin 线程池之后,执行速度有了明显的提升。以前 5 分钟执行不完的任务现在 2 分钟之内就能全部执行完毕。
java8 的并发流在大批量数据处理时可简化多线程的使用,在遇到耗时业务或者重度使用并发流不妨根据业务情况采用自定义线程池来提示处理速度。
看完上述内容,你们对如何自定义ForkJoinPool提升并行流 ParallelStream执行速度有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





