KafkaеҰӮдҪ•иҝӣиЎҢи·ЁAZйғЁзҪІжңҖдҪіе®һи·ө
KafkaеҰӮдҪ•иҝӣиЎҢи·ЁAZйғЁзҪІжңҖдҪіе®һи·өпјҢеҫҲеӨҡж–°жүӢеҜ№жӯӨдёҚжҳҜеҫҲжё…жҘҡпјҢдёәдәҶеё®еҠ©еӨ§е®¶и§ЈеҶіиҝҷдёӘйҡҫйўҳпјҢдёӢйқўе°Ҹзј–е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§ЈпјҢжңүиҝҷж–№йқўйңҖжұӮзҡ„дәәеҸҜд»ҘжқҘеӯҰд№ дёӢпјҢеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
и·ЁAZйғЁзҪІжңҖдҪіе®һи·өд№ӢKafka
и·ЁAZйғЁзҪІжҳҜе®һзҺ°жңҚеҠЎй«ҳеҸҜз”Ёиҫғдёәжңүж•Ҳзҡ„ж–№жі•пјҢеҗҢж—¶д№ҹжһҒе…·жҖ§д»·жҜ”гҖӮеҰӮжһңе®һзҺ°дәҶи·ЁAZйғЁзҪІпјҢдёҚд»…еҸҜд»Ҙж¶ҲйҷӨжңҚеҠЎдёӯзҡ„еҚ•зӮ№пјҢеҗҢж—¶иҝҳеҸҜд»ҘйҖҗжӯҘе»әи®ҫеҰӮдёӢиғҪеҠӣпјҡжңҚеҠЎйҡ”зҰ»пјҢзҒ°еәҰеҸ‘еёғпјҢN+1еҶ—дҪҷпјҢеҸҜи°“дёҖдёҫеӨҡеҫ—гҖӮдёҠдёҖзҜҮд»Ӣз»ҚдәҶESзҡ„и·ЁAZйғЁзҪІе®һи·өпјҢжң¬ж–Ү继з»ӯд»Ӣз»ҚKafkaеҰӮдҪ•е®һзҺ°и·ЁAZйғЁзҪІгҖӮ
е®һзҺ°ж–№ејҸ
вҖңbroker.rackвҖқжҳҜжңҚеҠЎз«ҜBrokerй…ҚзҪ®ж–Ү件дёӯзҡ„дёҖдёӘеҸӮж•°пјҢзұ»дјјдәҺESдёӯзҡ„RackжҲ–ZoneпјҢйҖҡиҝҮTagзҡ„ж–№ејҸпјҢе°ҶйӣҶзҫӨдёӯзҡ„BrokerиҝӣиЎҢвҖңеҲҶз»„вҖқпјҢеңЁеҲҶй…ҚеҲҶеҢәеүҜжң¬ж—¶е®һзҺ°и·ЁRackе®№й”ҷгҖӮжӯӨеҸӮж•°жҺҘеҸ—дёҖдёӘвҖңstringвҖқзұ»еһӢзҡ„еҖјпјҢй»ҳи®ӨдёәnullпјӣжӯӨеӨ–вҖңbroker.rackвҖқдёҚж”ҜжҢҒеҠЁжҖҒжӣҙж–°пјҢжҳҜеҸӘиҜ»зҡ„пјҢиҝҷж„Ҹе‘ізқҖпјҡ
жӣҙж–°Brokerзҡ„broker.rack йңҖиҰҒйҮҚеҗҜbrokerпјӣ
и·ЁAZйғЁзҪІзҡ„йӣҶзҫӨпјҢжү©зј©е®№дёҚйңҖиҰҒеҜ№йӣҶзҫӨе…¶д»–BrokerиҝӣиЎҢйҮҚеҗҜ
з”ҹдә§зҺҜеўғзҡ„KafkaйӣҶзҫӨиӢҘиҰҒеўһеҠ жӯӨй…ҚзҪ®е®һзҺ°и·ЁAZйғЁзҪІпјҢйңҖиҰҒеҜ№йӣҶзҫӨжүҖжңүBrokerиҝӣиЎҢйҮҚеҗҜгҖӮ
е…·дҪ“й…ҚзҪ®зӨәдҫӢеҰӮдёӢпјҡ
broker.rack=my-rack-id
еҪ“еҲӣе»әTopicж—¶дјҡеҸ—еҲ°broker.rackеҸӮж•°зҡ„зәҰжқҹпјҢд»ҘзЎ®дҝқеҲҶеҢәеүҜжң¬иғҪеӨҹе°ҪеҸҜиғҪеӨҡзҡ„и·ЁRackпјҢеҚіn = min(#racks, replication-factor)пјҢnжҢҮзҡ„жҳҜеҲҶеҢәзҡ„еүҜжң¬е°ҶдјҡеҲҶеёғеңЁnдёӘRackгҖӮ
йӮЈд»Җд№ҲжҳҜе°ҪеҸҜиғҪе‘ўпјҹ
иҝҷдёӘжҳҜеҹәдәҺKafkaеҲҶеҢәеҲҶй…Қз®—жі•пјҢе…·дҪ“е®һзҺ°еҸҜеҸӮиҖғжәҗз Ғдёӯзҡ„еҮҪж•°(assignReplicasToBrokers)гҖӮ
иҝҷйҮҢиҰҒиҜҙзҡ„жҳҜпјҢKafkaеңЁдёәTopicеҲҶй…ҚеҲҶеҢәж—¶дјҡж №жҚ®еҰӮдёӢеҮ дёӘеҸӮж•°пјҡreplication-factorпјҢpartitionsпјҢдёӨдёӘйҡҸжңәеҸӮж•°(startIndexпјҢfixedStartIndex)пјҢеҗ„BrokerдёҠеҲҶеҢәж•°йҮҸд»ҘеҸҠbroker.rackе°ҶжүҖжңүеҸҜз”Ёзҡ„Broker IDз”ҹжҲҗдёҖдёӘжңүеәҸеҲ—иЎЁпјҢеҲ—иЎЁдјҡжҢүз…§иҪ®иҜўbroker.rackзҡ„Brokerдә§з”ҹзҡ„гҖӮеҒҮи®ҫпјҡ
rack1: 0 1
rack2: 2 3
еҲҷз”ҹжҲҗзҡ„еҲ—иЎЁдјҡеҸҳжҲҗ:[0, 2, 1, 3]гҖӮеңЁеҲҶзүҮеҲҶеҢәж—¶пјҢеҪ“Brokerж»Ўи¶іеҰӮдёӢдёӨдёӘжқЎд»¶дёӯзҡ„д»»ж„ҸдёҖдёӘпјҢеүҜжң¬е°ҶдёҚдјҡеҲҶй…ҚеҲ°иҜҘиҠӮзӮ№пјҡ
жӯӨBrokerжүҖеңЁзҡ„broker.rackе·Із»ҸеӯҳеңЁиҜҘеҲҶеҢәзҡ„еүҜжң¬пјҢдё”еӯҳеңЁbroker.rackдёӯжІЎжңүиҜҘеҲҶеҢәеүҜжң¬гҖӮ
жӯӨBrokerдёӯе·Із»ҸеӯҳеңЁиҜҘеҲҶеҢәеүҜжң¬пјҢ并且иҝҳжңүе…¶д»–BrokerдёӯжІЎжңүиҜҘеҲҶеҢәзҡ„еүҜжң¬гҖӮ
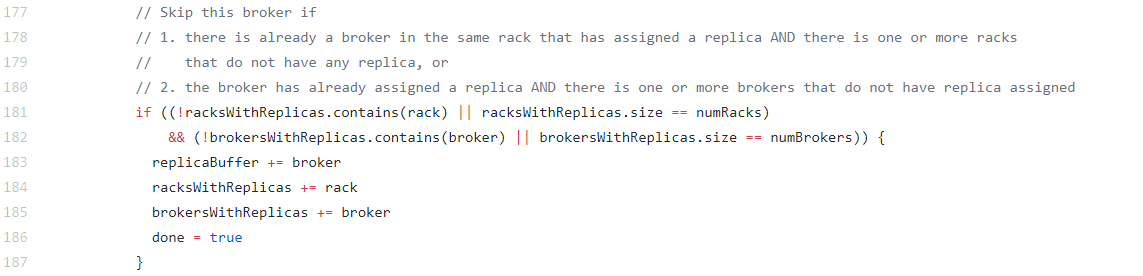
еӣҫ1 broker.rackеҸӮж•°еҲҶй…ҚжңәеҲ¶йғЁеҲҶжәҗз Ғ
йҖҡиҝҮдёҠж–Үзҡ„и§ЈйҮҠпјҢеӨ§е®¶еә”иҜҘеҜ№Kafkaзҡ„еүҜжң¬еҲҶй…ҚжңәеҲ¶жңүжүҖдәҶи§ЈпјҢжҖ»зҡ„жқҘиҜҙпјҡ
еҪ“replication-factor<#broker.rackж—¶пјҢTopicзҡ„жүҖжңүеҲҶеҢәдјҡдјҳе…ҲиҰҶзӣ–еҲ°жүҖжңүзҡ„broke.rackпјӣ
еҪ“replication-factor=#broker.rackж—¶пјҢжҜҸдёӘbroke.rackе°ҶеӯҳеңЁдёҖеҘ—е®Ңж•ҙзҡ„еҲҶеҢәеүҜжң¬пјӣ
еҪ“replication-factor>#broker.rackж—¶пјҢиҮіе°‘дёҖдёӘbroke.rackеӯҳеңЁдёҖеҘ—е®Ңж•ҙзҡ„еҲҶеҢәеүҜжң¬пјӣ
зү№еҲ«зҡ„пјҢеҪ“replication-factor=2#broker.rackж—¶пјҢTopicзҡ„еҲҶеҢәдјҡеқҮеҢҖеҲҶй…ҚеңЁдёӨдёӘAZгҖӮ
иҝҳжңүеҖјеҫ—жіЁж„Ҹзҡ„жҳҜпјҡ
KafkaеңЁиҝӣиЎҢLeaderйҖүдёҫжҲ–LeaderйҮҚе№іиЎЎж—¶пјҢдёҚе…іжіЁbroker.rackпјҢеҚій»ҳи®Өжғ…еҶөдёӢпјҢLeaderдјҡеҲҶеёғеңЁеӨҡдёӘAZгҖӮ
KafkaдёҚеғҸESпјҢе®ғдёҚе…·еӨҮеүҜжң¬иҮӘеҠЁиҪ¬з§»brokerжҒўеӨҚзҡ„иғҪеҠӣ
йӮЈд№ҲпјҢеҰӮдҪ•еңЁдёҖдёӘAZеҶ…йғЁпјҢе®һзҺ°brokerзҡ„й«ҳеҸҜз”ЁйғЁзҪІе‘ўпјҹжң¬иә«з»ҙжҠӨзңҹжӯЈж„Ҹд№үдёҠзҡ„жңәжһ¶еҲҶеёғйҡҫеәҰеҫҲеӨ§пјҢеҠ дёҠеңЁиҷҡжӢҹеҢ–еңәжҷҜдёӢпјҢжңәжһ¶е’ҢиҷҡжӢҹжңә/dockerдёӯй—ҙиҝҳеӯҳеңЁе®ҝдё»жңәеұӮпјҢз»ҙжҠӨжҲҗжң¬жӣҙй«ҳпјҢжүҖд»Ҙе»әи®®дҪҝз”Ёдә‘еҺӮе•ҶжҸҗдҫӣзҡ„й«ҳеҸҜз”Ёз»„/зҪ®ж”ҫзҫӨз»„жқҘе®һзҺ°гҖӮ
еңәжҷҜйӘҢиҜҒ
жўізҗҶдёҠж–ҮдёӯжҸҗеҲ°еҪұе“ҚеҪұе“ҚеҲҶеҢәеҲҶй…Қзҡ„еӣ зҙ пјҢжҺ’йҷӨдёӨдёӘйҡҸжңәеҸӮж•°(еҪұе“Қзҡ„д»…д»…жҳҜbroker listзҡ„иө·е§ӢID)е’ҢBrokerдёҠеҲҶеҢәж•°йҮҸжғ…еҶө(иҝҷдёӘеҸӮж•°еҪұе“Қзҡ„жҳҜAZеҶ…йғЁзҡ„еҶҚе№іиЎЎпјҢжң¬ж–Үзҡ„еңәжҷҜйӘҢиҜҒдёҚе…іеҝғAZеҶ…йғЁзҡ„еҲҶеҢәеҲҶй…Қжғ…еҶө)гҖӮ
жҜҸдёӘAZзҡ„brokerж•°йҮҸжҳҜеҗҰдёҖиҮҙпјҢд№ҹд»…д»…еҪұе“ҚеҲ°зҡ„жҳҜAZеҶ…йғЁзҡ„еҲҶеҢәжғ…еҶөпјҢдёәдәҶз®ҖеҢ–йӘҢиҜҒеңәжҷҜпјҢжҲ‘们жҡӮдёҚиҖғиҷ‘жҜҸдёӘAZ brokerдёҚдёҖиҮҙзҡ„жғ…еҶөпјҢжүҖжңүеҸҜз”Ёзҡ„Broker ID иҝҷдёӘеҸӮж•°еҸҜд»Ҙз®ҖеҢ–дёәвҖңеҚ•AZ brokerж•°йҮҸвҖқиҝҷдёӘеҸӮж•°д»ЈжӣҝгҖӮ
еү©дҪҷеҮ дёӘеӣ зҙ е’ҢйңҖиҰҒйӘҢиҜҒзҡ„еҖјеҰӮдёӢиЎЁжүҖзӨәпјҡ
иЎЁ1 еҸӮж•°еҲ—иЎЁ
еҸӮж•° | йӘҢиҜҒеҖј | еӨҮжіЁ |
TopicеҲҶеҢәж•° | 1,2,3 | иҖғиҷ‘1дёӘеҲҶеҢәе’ҢеҘҮеҒ¶еҲҶеҢәзҡ„еңәжҷҜ |
TopicеүҜжң¬ж•° | 1,2,3 | иҖғиҷ‘1еүҜжң¬е’ҢеҘҮеҒ¶еүҜжң¬ж•°зҡ„еңәжҷҜ |
йӣҶзҫӨAZж•°йҮҸ | 1,2,3 | иҖғиҷ‘1дёӘAZпјҲжІЎжңүAZпјүе’ҢеҘҮеҒ¶AZзҡ„еңәжҷҜ |
еҚ•AZ brokerж•°йҮҸ | 1,2,3 | иҖғиҷ‘еҲҶеҢәж•°жҲ–еүҜжң¬ж•°е°ҸдәҺпјҢзӯүдәҺпјҢеӨ§дәҺеҚ•AZзҡ„brokerзҡ„еҗ„з§ҚеңәжҷҜ |
иҰҒз©·е°ҪдёҠиЎЁдёӯзҡ„еҗ„з§Қз»„еҗҲпјҢе…ұйңҖиҰҒйӘҢиҜҒ3*3*3*3=81з§ҚеңәжҷҜпјҢдёәдәҶжҺ’йҷӨеҒ¶з„¶еӣ зҙ зҡ„еҪұе“ҚпјҢжҜҸз§ҚеңәжҷҜиҝҳйңҖиҰҒйҮҚеӨҚеӨҡж¬ЎиҜ•йӘҢпјҢиҝҷж ·еҒҡдјҡйқһеёёз№ҒзҗҗгҖҒдё”ж•ҲзҺҮдёҚй«ҳгҖӮ
жҲ‘们еҸҜд»Ҙе°ҶеҸӮж•°зңӢдҪңвҖңеӣ зҙ вҖқпјҢйӘҢиҜҒеҖјзңӢвҖңж°ҙе№івҖқпјҢжҜҸдёӘеӣ зҙ еҸ–д»Җд№ҲеҖјжҳҜдёҺе…¶д»–еӣ зҙ ж— е…ігҖӮиҝҷжӯЈеҸҜд»ҘйҮҮз”ЁвҖңжӯЈдәӨиҜ•йӘҢвҖқзҡ„жҖқи·ҜпјҲж №жҚ®жӯЈдәӨжҖ§д»Һе…ЁйқўиҜ•йӘҢдёӯжҢ‘йҖүеҮәйғЁеҲҶжңүд»ЈиЎЁжҖ§зҡ„зӮ№иҝӣиЎҢиҜ•йӘҢпјҢжҳҜдёҖз§Қй«ҳж•ҲзҺҮгҖҒеҝ«йҖҹгҖҒз»ҸжөҺзҡ„е®һйӘҢи®ҫи®Ўж–№жі•пјүгҖӮйӘҢиҜҒдёҠиЎЁдёӯзҡ„еңәжҷҜеҲҡеҘҪеҸҜд»Ҙз”ЁжңҖеёёз”Ёзҡ„L9(3^4)еһӢжӯЈдәӨиЎЁ(3ж°ҙе№і4еӣ зҙ дёҖиҲ¬йғҪз”ЁжӯӨиЎЁ)пјҢе…ұйңҖиҰҒйӘҢиҜҒ9з§ҚеңәжҷҜеҚіеҸҜпјҢжҜҸз§ҚеңәжҷҜиҝӣиЎҢ10ж¬ЎйӘҢиҜҒпјҢд»ҘжҺ’жҹҘеҒ¶з„¶еӣ зҙ гҖӮ
е®һйҷ…дёҠеҸӘйңҖйӘҢиҜҒ7з§ҚеңәжҷҜеҚіеҸҜпјҢеӣ дёәе…¶дёӯдёӨз§ҚеңәжҷҜдёҚз¬ҰеҗҲKafkaеҲӣе»әTopicзҡ„иҰҒжұӮгҖӮйҖҡиҝҮKafka Managerзҡ„еҸҜи§ҶеҢ–з•Ңйқўжё…жҷ°зҡ„зңӢеҲ°еҲҶеҢәеүҜжң¬зҡ„еҲҶеёғжғ…еҶөпјҢзұ»дјјиҝҷж ·зҡ„пјҡ
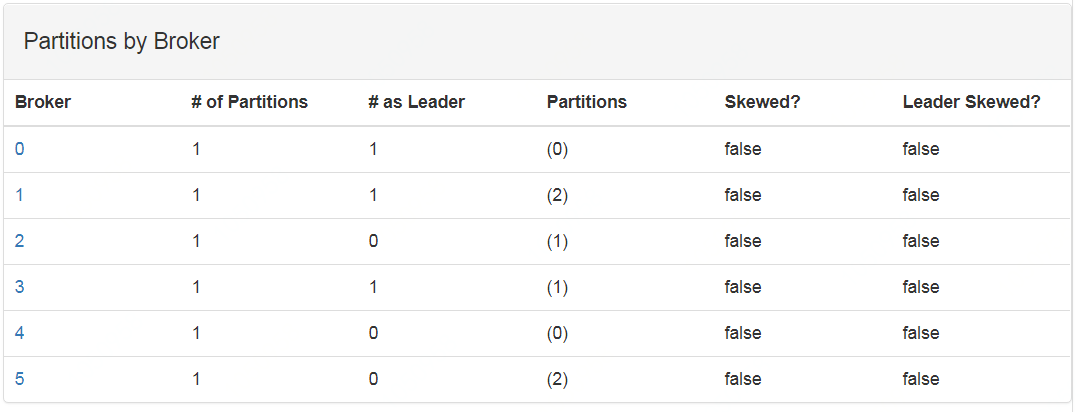
еӣҫ2 дёүеҲҶеҢәдёӨеүҜжң¬2AZж—¶зҡ„еҲҶеёғжғ…еҶөпјҢе…¶дёӯ broker idдёә0,1,2дёҖдёӘAZпјҢ3,4,5дёҖдёӘAZ
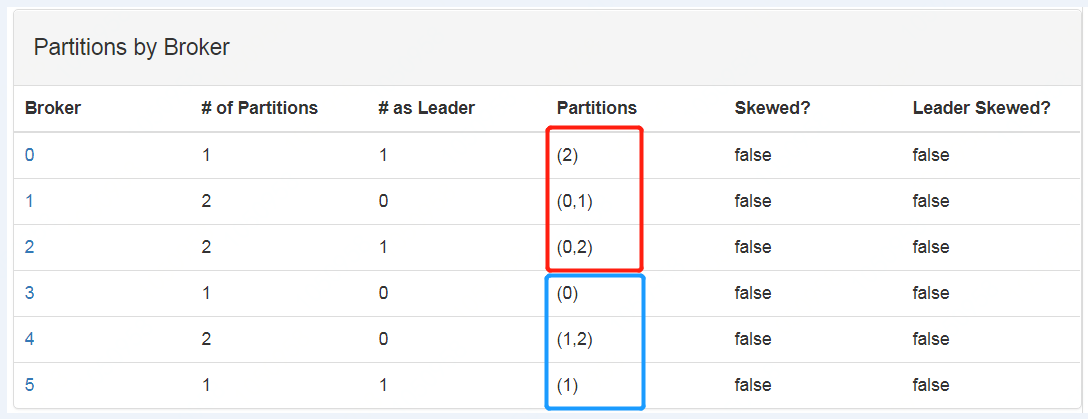
еӣҫ3 дёүеҲҶеҢәдёүеүҜжң¬2AZж—¶зҡ„еҲҶеёғжғ…еҶөпјҢе…¶дёӯ broker idдёә0,1,2дёҖдёӘAZпјҢ3,4,5дёҖдёӘAZ
йҮҮз”ЁL9(34)еһӢзҡ„жӯЈдәӨиЎЁпјҢеңәжҷҜд»ҘеҸҠз»“и®әеҰӮдёӢпјҡ
иЎЁ2 жӯЈдәӨеңәжҷҜиЎЁ
еңәжҷҜ | еҲҶеҢәж•° | еүҜжң¬ж•° | AZж•°йҮҸ | еҚ•AZ brokerж•°йҮҸ | еҲҶеҢәеҲҶеёғ | LeaderеҲҶеёғ | еӨҮжіЁ |
1 | 1 | 1 | 1 | 1 | жҜҸдёӘAZе…·еӨҮдёҖеҘ—еҲҶеҢә | дёҖдёӘAZ | replication-factor=#broker.rack |
2 | 1 | 2 | 2 | 2 | жҜҸдёӘAZе…·еӨҮдёҖеҘ—еҲҶеҢә | дёӨдёӘAZйҡҸжңә | replication-factor=#broker.rack |
3 | 1 | 3 | 3 | 3 | жҜҸдёӘAZе…·еӨҮдёҖеҘ—еҲҶеҢә | дёӨдёӘAZйҡҸжңә | replication-factor=#broker.rack |
4 | 2 | 1 | 2 | 3 | 2дёӘAZе…ұжңүдёҖеҘ—еҲҶеҢә | дёӨдёӘAZйҡҸжңә | replication-factor<#broker.rack |
5 | 2 | 2 | 3 | 1 | дёҖдёӘAZе…·еӨҮдёҖеҘ—еҲҶеҢәпјҢе…¶д»–еҲҶеҢәе…ұжңүдёҖеҘ—еҲҶеҢә | дёүдёӘAZйҡҸжңә | replication-factor<#broker.rack |
6 | 2 | 3 | 1 | 2 | -- | -- | еүҜжң¬ж•°>еҲҶеҢәж•°ж— жі•еҲӣе»ә |
7 | 3 | 1 | 3 | 2 | 3дёӘAZе…ұжңүдёҖеҘ—еҲҶеҢә | дёүдёӘAZйҡҸжңә | replication-factor<#broker.rack |
8 | 3 | 2 | 1 | 3 | жҜҸдёӘAZе…·еӨҮдёӨеҘ—еҲҶеҢә | | replication-factor>#broker.rack |
9 | 3 | 3 | 2 | 1 | -- | -- | еүҜжң¬ж•°>еҲҶеҢәж•°ж— жі•еҲӣе»ә |
еҸҜи§ҒпјҢи·ЁAZйғЁзҪІзҡ„йӣҶзҫӨпјҢиӢҘйҮҮеҸ–4еүҜжң¬еҸҜд»ҘеҒҡеҲ°AZеҶ…йғЁд»ҘеҸҠи·ЁAZж•°жҚ®еӨҮд»Ҫзҡ„иғҪеҠӣгҖӮиӢҘдёҖдёӘAZдё»иҰҒжҳҜдёәдәҶе®№зҒҫзҡ„иҜқпјҢеҸҜд»ҘйҖҡиҝҮKafkaзҡ„APIпјҲkafka-reassign-partitions.shпјүе°ҶжүҖжңүзҡ„LeaderйӣҶдёӯеңЁдёҖдёӘAZпјҢд»ҺиҖҢйҷҚдҪҺи·ЁAZеҶҷж•°жҚ®зҡ„延иҝҹгҖӮдёҚиҝҮпјҢдёҖиҲ¬зҡ„пјҢAZд№Ӣй—ҙзҡ„延иҝҹеҫҖеҫҖеҫҲдҪҺжҳҜеҸҜжҺҘеҸ—зҡ„гҖӮ
жҲҗжң¬дёҺзҪ‘з»ң延иҝҹ
еӨҡAZзҡ„йғЁзҪІжһ¶жһ„пјҢдё»иҰҒжҳҜ硬件жҲҗжң¬пјҢиҖҢиҖғиҷ‘жҲҗжң¬пјҢйңҖиҰҒз»“еҗҲж•°жҚ®йҮҚиҰҒжҖ§гҖӮиӢҘж•°жҚ®йҮҚиҰҒжҖ§иҫғй«ҳпјҢеӣӣеүҜжң¬зҡ„Topicй…ҚзҪ®жҳҜйңҖиҰҒзҡ„пјҢ并且KafkaдҪңдёәж¶ҲжҒҜйҳҹеҲ—пјҢMessagesзҡ„еӯҳеӮЁжң¬иә«е№¶дёҚйҮҚиҰҒпјҢжүҖд»ҘжҲҗжң¬зҡ„еҪұе“ҚдёҚеӨ§гҖӮ
第дәҢдёӘй—®йўҳе°ұжҳҜзҪ‘и·Ҝ延иҝҹпјҢжҲ‘们йҖҡиҝҮеҺӢжөӢжқҘйӘҢиҜҒзҪ‘з»ң延иҝҹдјҡеҜ№KafkaеёҰжқҘд»Җд№ҲгҖӮеңЁеҸҜз”ЁеҢәAе’ҢеҸҜз”ЁеҢәBеҲӣе»әдёҖеҘ—йӣҶзҫӨпјҡ
еҹәеҮҶйӣҶзҫӨдёә:еңЁеҚҺеҢ—еҸҜз”ЁеҢәAйғЁзҪІзҡ„2еҸ°жңәеҷЁз»„жҲҗзҡ„йӣҶзҫӨ
и·ЁAZйӣҶзҫӨдёәеңЁеҚҺеҢ—еҸҜз”ЁеҢәAе’ҢеҸҜз”ЁеҢәBйғЁзҪІзҡ„2еҸ°жңәеҷЁз»„жҲҗзҡ„йӣҶзҫӨ
дёӨдёӘAZзӣҙжҺҘзҡ„ping延иҝҹе’ҢAZеҶ…йғЁзҡ„ping延иҝҹеқҮеҖјеҲҶеҲ«дёә:0.070msе’Ң1.171msгҖӮд»ҺдёүдёӘи§’еәҰйӘҢиҜҒзҪ‘з»ң延иҝҹзҡ„еҪұе“ҚгҖӮ
еҜ№ж¶ҲжҒҜеҶҷе…Ҙзҡ„еҪұе“Қ
з”ҹдә§иҖ…еҗ‘KafkaйӣҶзҫӨеҸ‘йҖҒж¶ҲжҒҜпјҢеҸҲеҸҜеҲҶдёәеҗҢжӯҘ(acks=all)е’ҢејӮжӯҘ(acks=1)дёӨз§Қж–№ејҸпјҢжҲ‘们йҮҮз”ЁkafkaиҮӘеёҰзҡ„еҺӢжөӢе·Ҙе…·(/kafka-producer-perf-test.sh)еҜ№дёӨдёӘйӣҶзҫӨиҝӣиЎҢеҺӢжөӢгҖӮ
еңЁдёҠиҝ°дёӨдёӘйӣҶзҫӨеҗ„еҲӣе»әдёҖдёӘtopic(--replication-factor 2 --partitions 1пјҢleaderдҪҚдәҺеҸҜз”ЁеҢәAдёҠ)
еҺӢжөӢжңәдҪҚдәҺеҚҺеҢ—еҸҜз”ЁеҢәAпјҢжҜҸжқЎж¶ҲжҒҜзҡ„еӨ§е°Ҹдёә300еӯ—иҠӮпјҲдёәдәҶдҪ“зҺ°зҪ‘з»ңзҡ„й—®йўҳпјҢејұеҢ–иҮӘиә«еӨ„зҗҶжҜҸжқЎж¶ҲжҒҜзҡ„иғҪеҠӣпјүпјҢжҜҸз§’еҸ‘йҖҒ10000жқЎж•°жҚ®гҖӮ
еҪ“ж¶ҲжҒҜз”ҹдә§иҖ…е·ІејӮжӯҘж–№ејҸеҶҷе…Ҙж—¶пјҢеҚіacks=1ж—¶пјҢдёӨдёӘйӣҶзҫӨзҡ„е№іеқҮ延иҝҹеҮ д№ҺжІЎжңүе·®еҲ«пјҢеҺӢжөӢз»“жһңдёӨиҖ…еҲҶеҲ«жҳҜ0.42 ms avg latencyе’Ң0.51 ms avg latencyгҖӮ
еҺӢжөӢеҸӮж•°пјҡ
./kafka-producer-perf-test.sh --topic pressure1 --num-records 500000 --record-size 300 \
--throughput 10000 --producer-props bootstrap.servers=10.160.109.68:9092
еҹәеҮҶйӣҶзҫӨеҺӢжөӢз»“жһңпјҡ
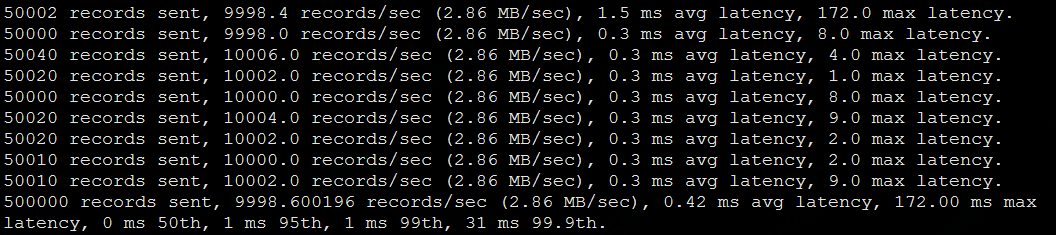
и·ЁAZйӣҶзҫӨеҺӢжөӢз»“жһңпјҡ
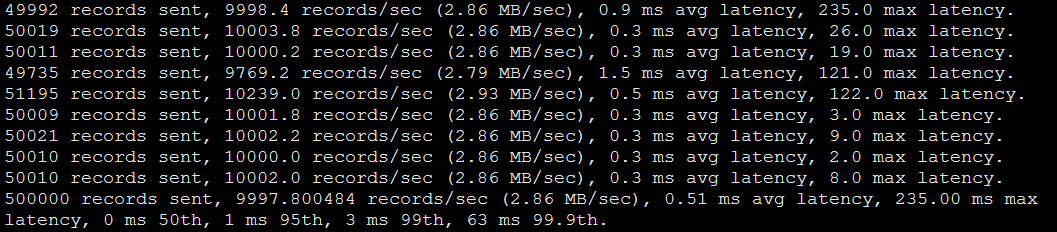
еҪ“ж¶ҲжҒҜйҮҮз”ЁеҗҢжӯҘжңәеҲ¶ж—¶пјҢж¶ҲжҒҜзҡ„еҶҷе…ҘжңүеҪұе“ҚгҖӮеҪұе“ҚиҝҳжҳҜжңүдәӣеӨ§зҡ„пјҢеҹәеҮҶйӣҶзҫӨдёә1.09 ms avg latency,и·ЁAZйӣҶзҫӨдёә8.17 ms avg latencyпјҡ
еҺӢжөӢеҸӮж•°пјҡ
./kafka-producer-perf-test.sh --topic pressure --num-records 500000 --record-size 300 \
--throughput 10000 --producer-props acks=all bootstrap.servers=10.160.109.68:9092
еҹәеҮҶйӣҶзҫӨеҺӢжөӢз»“жһңпјҡ
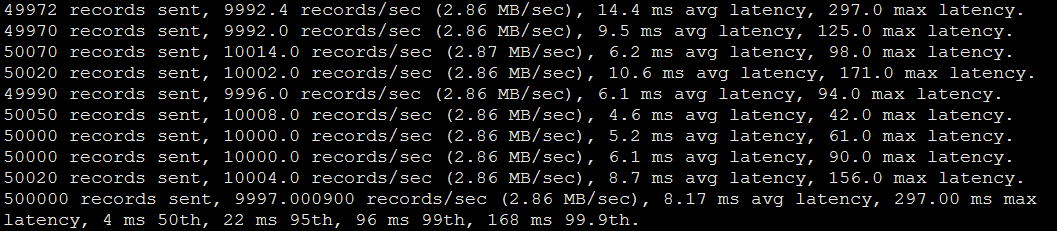
дёӢиЎЁжҳҜеҜ№жҜ”дәҶеҪ“ж¶ҲжҒҜеӨ§е°Ҹдёә10,50вҖҰ300ж—¶пјҢеҗҢжӯҘеҶҷж—¶зҡ„е№іеқҮ延иҝҹпјҢеҸ‘зҺ°пјҢи·ЁAZйӣҶзҫӨ/еҹәеҮҶйӣҶзҫӨеӨ§жҰӮиғҪдҝқжҢҒ7еҖҚзҡ„延иҝҹе·®гҖӮ

иЎЁ4 жӯҘеҶҷе…Ҙж—¶зҡ„ж•°жҚ®еҜ№жҜ”
ж¶ҲжҒҜдҪ“еӨ§е°Ҹ | 10 | 50 | 100 | 150 | 200 | 300 |
еҹәеҮҶ-е№іеқҮ延иҝҹ/ms | 0.91 | 0.83 | 0.65 | 0.75 | 0.72 | 1.09 |
и·ЁAZ-е№іеқҮ延иҝҹ/ms | 5.39 | 4.48 | 5.23 | 5.23 | 5.14 | 8.17 |
жҜ”еҖј(и·ЁAZ/еҹәеҮҶ) | 5.92 | 5.40 | 8.05 | 6.97 | 7.14 | 7.50 |
еҜ№йӣҶзҫӨиҮӘиә«зҡ„еҪұе“Қ
йҖүжӢ©ж¶ҲжҒҜдҪ“еӨ§е°Ҹдёә1000еӯ—иҠӮе……еҲҶйӘҢиҜҒи·ЁAZеңәжҷҜдёӢпјҢзҪ‘з»ңдј иҫ“еҜ№йӣҶзҫӨж•°жҚ®еҗҢжӯҘзҡ„еҪұе“ҚгҖӮеҜ№дәҺеҹәеҮҶйӣҶзҫӨпјҢжҲ‘们е°ҶдёҖеҸ°BrokerеҒңжҺүпјҢдҪҝз”ЁеҺӢжөӢе·Ҙе…·ејӮжӯҘеҶҷе…Ҙ5000000жқЎж•°жҚ®пјҢ然еҗҺеҗҜеҠЁеҒңжҺүзҡ„BrokerпјҢиҺ·еҫ—еүҜжң¬еҲҶеҢәдёҺleaderе®ҢжҲҗеҗҢжӯҘзҡ„ж—¶й—ҙпјӣеҗҢж ·зҡ„пјҢеҜ№и·ЁAZйӣҶзҫӨпјҢеҒңжҺүеҸҜз”ЁеҢәB дёӯзҡ„BrokerпјҢд№ҹеҗ‘leaderеҶҷе…ҘеҗҢж ·зҡ„ж•°жҚ®пјҢиҺ·еҫ—еүҜжң¬еҲҶеҢәдёҺleaderе®ҢжҲҗеҗҢжӯҘзҡ„ж—¶й—ҙпјҢ并еҜ№дёӨиҖ…иҝӣиЎҢжҜ”иҫғгҖӮ
еҹәеҮҶйӣҶзҫӨеңЁ26sе®ҢжҲҗдәҶеүҜжң¬еҗҢжӯҘпјҡ

и·ЁAZйӣҶзҫӨеңЁ142sе®ҢжҲҗдәҶеүҜжң¬еҗҢжӯҘпјҢиҖҢдё”еңЁеҗҢжӯҘжңҹй—ҙпјҢеҮәзҺ°дәҶдёҺZKиҝһжҺҘи¶…ж—¶зҡ„WARNгҖӮ

еҸҜи§ҒпјҢи·ЁAZйӣҶзҫӨеңЁping延иҝҹдёӢпјҢеҜ№дәҺж¶ҲжҒҜдҪ“иҫғеӨ§ж—¶пјҢдјҡеҮәзҺ°дёҖдәӣжҪңеңЁзҡ„й—®йўҳгҖӮ
еҜ№Topicж¶Ҳиҙ№зҡ„еҪұе“Қ
ж¶Ҳиҙ№зҡ„延иҝҹд№ҹдё»иҰҒйӣҶдёӯеңЁи·ЁAZзҡ„и·қзҰ»дёҠпјҢдёҚиҝҮжҳҜеҸҜи§Јзҡ„пјҢж¶Ҳиҙ№иҖ…з»„ж”ҜжҢҒеҰӮдёӢеҸӮж•°пјҡ
client.rack #жӯӨеҸӮж•°жҺҘеҸ—дёҖдёӘstringзұ»еһӢзҡ„еҖјпјҢ 并дёҺbroker.rackзҡ„еҖјдҝқжҢҒдёҖиҮҙгҖӮ
жңҖдҪіе®һи·ө--з”ҹдә§зҺҜеўғеҚҮзә§дёәеӨҡAZйғЁзҪІ
еҪ“дҪ зҡ„йӣҶзҫӨе·Із»ҸиҝҗиЎҢеңЁз”ҹдә§зҺҜеўғдёҠдәҶпјҢзҺ°еңЁйңҖиҰҒеҚҮзә§дёәи·ЁAZйғЁзҪІпјҢйӮЈд№Ҳеә”иҜҘеҰӮдҪ•еҜ№зҺ°жңүйӣҶзҫӨиҝӣиЎҢй…ҚзҪ®еҚҮзә§е‘ўпјҹ
еҪ“йӣҶзҫӨдёӯеӯҳеңЁжңүbrocker.rackеҸӮж•°дёәnullзҡ„иҠӮзӮ№ж—¶пјҢе“ӘжҖ•еҸӘжңүдёҖеҸ°жңәеҷЁпјҢй»ҳи®ӨеҸӮж•°дёӢеҲӣе»әtopicдјҡеӨұиҙҘпјҢдјҡеҮәзҺ°еҰӮдёӢжҠҘй”ҷпјҡ

йҖҡиҝҮеҸӮж•°--disable-rack-aware еҸҜд»ҘеҝҪз•Ҙbroker.rackеҸӮж•°иҝӣиЎҢеҲҶеҢәеҲҶй…ҚгҖӮз”ҹдә§зҺҜеўғзҡ„еҚҮзә§йңҖиҰҒдҝ®ж”№еҲӣе»әtopicзҡ„ж–№ејҸпјҢеҚҮзә§иҝҮзЁӢдёӯеҜ№ж•°жҚ®еҶҷе…Ҙе’Ңж¶Ҳиҙ№жІЎжңүеҪұе“ҚпјҲеҜ№е·Із»ҸеӯҳеңЁзҡ„topicпјҢKafkaд№ҹдёҚдјҡиҮӘеҠЁзҡ„е°ҶеҲҶеҢәйҮҚе№іиЎЎпјүгҖӮ
з”ҹдә§зҺҜеўғи·ЁAZеҚҮзә§зҡ„дёҖиҲ¬жӯҘйӘӨеҰӮдёӢпјҡ
и·ЁAZеҲӣе»әжөӢиҜ•йӣҶзҫӨпјҢе……еҲҶйӘҢиҜҒи·ЁAZеҜ№йӣҶзҫӨзҡ„еҪұе“ҚпјҢйңҖиҰҒе…іжіЁеҶҷе…ҘеҗһеҗҗйҮҸзҡ„еҪұе“ҚпјҲTopicжҳҜеҗҰйңҖиҰҒеўһеҠ еҲҶеҢәпјүпјҢйӣҶзҫӨиҮӘиә«ж•°жҚ®еҗҢжӯҘзҡ„иө„жәҗж¶ҲиҖ—е’Ңж¶Ҳиҙ№зҡ„и·ЁAZ延иҝҹжғ…еҶөпјӣ
еҲ¶е®ҡе……еҲҶзҡ„еӣһж»ҡйў„жЎҲпјҢ并иҝӣиЎҢеӣһж»ҡжј”з»ғпјӣ
еўһеҠ вҖңbroker.rackвҖқеҸӮж•°пјҢеңЁж–°зҡ„еҸҜз”ЁеҢәеҜ№йӣҶзҫӨиҝӣиЎҢжү©е®№пјӣ
еҜ№йӣҶзҫӨеҺҹжңүиҠӮзӮ№пјҢеўһеҠ вҖңbroker.rackвҖқеҸӮж•°пјҢ并йңҖиҰҒж»ҡеҠЁйҮҚжүҖжңүиҠӮзӮ№;
еңЁTopicзә§еҲ«пјҢйҖҡиҝҮжүӢеҠЁжҢҮе®ҡеүҜжң¬еҲҶй…ҚпјҢеңЁеҗҲйҖӮзҡ„ж—¶й—ҙеҜ№TopicиҝӣиЎҢеҲҶеҢәеҲҶй…Қ;
жҢүз…§йңҖжұӮпјҢеҗҜеҠЁTopicзҡ„LeaderйҮҚеҲҶй…ҚгҖӮ
жіЁж„ҸдәӢйЎ№
Kafkaзҡ„и·ЁAZйғЁзҪІзҡ„еүҚжҸҗжҳҜйңҖиҰҒжңүи·ЁAZйғЁзҪІзҡ„ZookeeperпјҢдёҚ然еҪ“ZKйӣҶзҫӨжүҖеңЁзҡ„AZж•…йҡңпјҢKafkaйӣҶзҫӨд№ҹе°ҶдёҚеҸҜз”Ёпјӣ
еҜ№жӯЈеңЁдҪҝз”Ёзҡ„KafkaйӣҶзҫӨиҝӣиЎҢи·ЁAZйғЁзҪІпјҢеҪ“йӣҶзҫӨ规模иҫғеӨ§ж—¶пјҢж»ҡеҠЁйҮҚеҗҜйӣҶзҫӨж“ҚдҪңж—¶й—ҙи·ЁеәҰдјҡеҫҲй•ҝпјҢ并且йңҖиҰҒдәәе·ҘеҜ№жүҖжңүзҡ„TopicиҝӣиЎҢеҲҶеҢәиҝҒ移пјҢиӢҘйӣҶзҫӨдёӯTopicеҫҲеӨҡпјҢжӯӨж“ҚдҪңзҡ„е·ҘдҪңйҮҸдјҡеҫҲеӨ§пјӣ
з”ҹдә§зҺҜеўғзҡ„и·ЁAZеҚҮзә§йңҖиҰҒе……еҲҶзҡ„йӘҢиҜҒпјҢеҜ№з”ҹдә§зҺҜеўғж¶ҲжҒҜдҪ“зҡ„еӨ§е°ҸиҝӣиЎҢз»ҹи®ЎпјҢзү№еҲ«зҡ„йңҖиҰҒе…іжіЁж¶ҲжҒҜдҪ“еӨ§е°ҸеӨ§дәҺ80еҲҶдҪҚж•°пјҢ90еҲҶдҪҚж•°е’Ң95еҲҶдҪҚж•°дёӢзҡ„ж•°жҚ®еҗҢжӯҘеҜ№йӣҶзҫӨйҖ жҲҗзҡ„延иҝҹеҪұе“ҚпјҢд»Ҙе…ҚеңЁй«ҳ并еҸ‘еҶҷе…Ҙж—¶жӢ–еһ®йӣҶзҫӨгҖӮ
зңӢе®ҢдёҠиҝ°еҶ…е®№жҳҜеҗҰеҜ№жӮЁжңүеё®еҠ©е‘ўпјҹеҰӮжһңиҝҳжғіеҜ№зӣёе…ізҹҘиҜҶжңүиҝӣдёҖжӯҘзҡ„дәҶи§ЈжҲ–йҳ…иҜ»жӣҙеӨҡзӣёе…іж–Үз« пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўжӮЁеҜ№дәҝйҖҹдә‘зҡ„ж”ҜжҢҒгҖӮ





