这篇文章主要讲解了“lucene倒排索引的存储方式介绍”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“lucene倒排索引的存储方式介绍”吧!
在谈谈lucene倒排索引的存储方式中只说明了倒排索引位置相关信息的存储,并没有详细说明如果需要对位置信息进行随机访问,那么它的索引该如何设计。lucene采用的是多级跳跃链表的方式,先说说跳跃链表基本思想(其实在前面文中也提过),假设给定一堆排过序的数字,并且数据量很大以至于在内存中放不下,如果要快速随机访问其中的某个数值,一种方法是对这些数字每隔一定的条数如1000条就记录相应的数值以及对应的文件指针,然后把这些数值以及对应的文件指针加载到内存中采用二分查找法找到欲查找数值所在数据块的起始地址,然后将1000条记录依次遍历比较或者加载到内存中采用二分查找都可以,这些数值和文件指针又叫一级跳跃表。
如果说一级跳跃表的数据量依然很大,那么又要在此基础上再建立一层跳跃表,依此类推就会有多级跳跃表了。值得一提的是级数并不是越多越好,因为层级越多,查找的次数也越多,lucene默认最大层级为10。
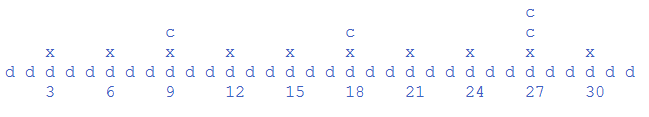
上图是lucene官方给出的示图(一个词代表的倒排位置索引),d代表文档,x代表每隔128个文档进行压缩的文件指针也是第一层级的索引记录了相应的文档ID和所在文件的指针,c分别为第二层级和第三层级。这样感觉在代码实现上较复杂的索引结构确在lucene实现的时候显得非常讨巧,因为总的层级可以预先算出来,然后可以边写边计算出文档所在层级。有兴趣滴还是看代码吧。
感谢各位的阅读,以上就是“lucene倒排索引的存储方式介绍”的内容了,经过本文的学习后,相信大家对lucene倒排索引的存储方式介绍这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/1268334/blog/3072516



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



