这篇文章主要讲解了“RabbitMQ的高级特性是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“RabbitMQ的高级特性是什么”吧!
方式1:消息落库,对消息状态进行打标 1)发送方将业务数据进行入库到BIZ_DB,将消息入库到MSG_DB,status置为0,只要有一步操作失败,就不进行下一步操作,如果该步骤失败, 进行快速失败的机制 2)发送方给MQ发送消息 3)MQ接收到消息后给发送方确认 4)发送方监听到该确认消息后将消息status置为1,这是正常成功的逻辑 5)发送方有一个分布式的定时任务,扫描表中超时的status为0的消息,超时时间比如说可以设置为2min 6)对于status为0的消息,进行重新发送 7)设置最大重试次数,如Retry_count > 3时将该消息status置为2 注意: 1)业务数据和消息可以落到一个库里.对于落到两个库里,对于小规模的设计应用,可以开启事务,保证数据源都是一致的.对于大规模、高并 发情况下,没听说有大的互联网公司有开启事务,采用补偿机制. 2)不好的地方:步骤1需要对数据库持久化2次 3)分布式定时任务,保证同一时间点只有一个任务去抓取DB 第一个可靠性投递,在高并发场景下是否适合?第一种方式需要入库两次,高并发情况下对数据库压力大.
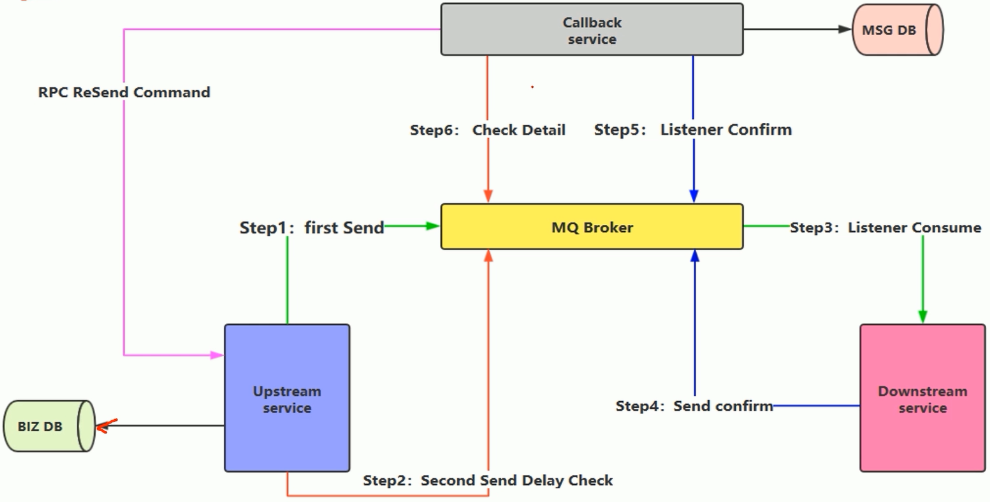
方式2:消息的延迟投递,做二次确认,回调检查(接收海量的数据) 方案2目的是为了减少数据库持久化操作次数,如订单场景. 关键点不是100%成功,关键点是性能,扛得住高并发。不能100%成功, 人工或定时任务补偿,对于核心链路,减少数据库操作,UpStream上游服务生产端,DownStream下游服务消费端,Callback回调服务 1)业务数据落库,仅做一次入库,一次性生成两条消息,然后发送第一条MQ消息到消息中间件. 注意:一定是业务数据落库以后,再发消息.互联网大厂不加事务,事务严重影响性能 2)第二条MQ消息延迟一段时间再发,延迟投递,如2min之后再发 3)消费者进行监听并消费消息 4)消费完成之后消费端在发送确认消息到MQ,该确认消息是消费端自己生成的 5)Callback服务监听该确认消息,Callback知道下游成功处理了,Callback对该消息进行入库 6)Callback监听延迟投递的消息,检查MSG DB数据库,发现该消息已经成功处理 7)如果之前出现异常,MSG DB中没有该消息,Callback会RPC调用UpStream重新发送MQ消息 注意: 1)一定是业务数据落库以后,再发送消息 2)不加事务,事务会造成严重的性能瓶颈 3)Callback只是一个补偿服务,它不是核心链路上的
幂等性:一个幂等操作的特点是其任意执行多次执行所产生的影响均与一次执行的影响相同 我们可以借鉴数据库的乐观锁机制,如执行一个更新库存的SQL语句: 使用版本号来控制,比如elaticsearch update t_reps set count = count - 1, version = version + 1 where version = 1
消费端的幂等性保障 在海量订单产生的业务高峰期,如何避免消息的重复消费问题?消费端实现幂等性,就意味着,我们的消息永远不会消费多次, 即使我们收到了多条一样的消息 业界主流的幂等性操作: 1)唯一ID + 指纹码机制,利用数据库主键去重 唯一ID + 指纹码机制,指纹码可以是根据业务生成的字段,如时间戳或者银行返回的字段等,利用数据库主键去重 select count(1) from t_order where id = 唯一ID + 指纹码,如果为1说明之前已经消费过了 好处:实现简单 坏处:高并发下有数据库写入的性能瓶颈 解决方案:跟进ID进行分库分表进行算法路由 2)利用Redis的原子特性实现 使用Redis进行幂等,需要考虑的问题,使用redis的setnx命令 1、我们是否需要进行数据落库,如果落库的话,关键解决的问题是数据库和缓存如何做到一致性? 2、如果不进行落库,那么都存储到缓存中,如何设置定时同步的策略?
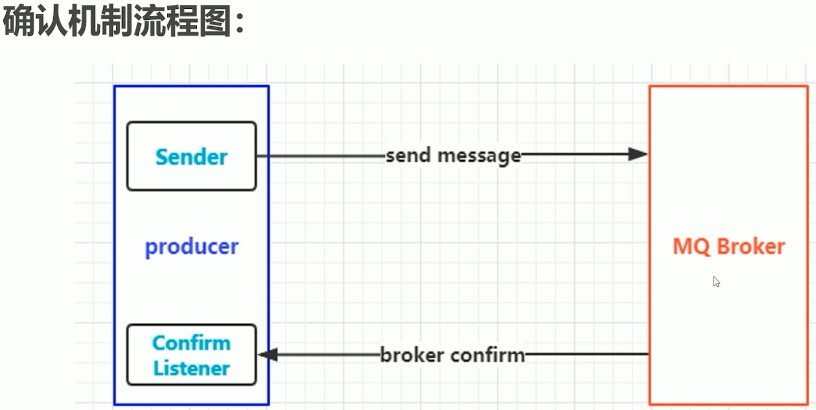
理解Confirm消息确认机制: 消息的确认,是指生产者投递消息之后,如果Broker收到消息,则会给我们生产者一个应答. 生产者接收应答,用来确定这条消息是否正常 的发送到Broker,这种方式也是消息的可靠投递的核心保障! 如何实现Confirm确认消息: 1) 在channel上开启确认模式,channel.confirmSelect() 2) 在channel上添加监听,addConfirmListener,监听成功或失败的返回结果,根据具体的结果对消息进行重新发送、或记录日志等后续处理.
Return Listener用于处理一些不可路由的消息. 我们的消息生产者,通过指定一个Exchange和Routing Key,把消息送达到某一个队列中去,然后我们的消费者监听队列,进行消费 处理操作! 但是在某些情况下,如果我们在发送消息的时候,当前的Exchange不存在或者指定的路由key路由不到,这个时候我们需要监听这种 不可达的消息,就要使用Return Listener 在基础API中有一个属性Mandatory,如果为true,则监听器会接收到路由不可达的消息,然后进行后续处理,如果为false,那么 broker端自动删除该消息.
public class MyConsumer extends DefaultConsumer {
public MyConsumer(Channel channel) {
super(channel);
}
@Override
public void handleDelivery(String consumerTag, Envelope envelope,
AMQP.BasicProperties properties, byte[] body) throws IOException {
System.err.println("-----------consume message----------");
System.err.println("consumerTag: " + consumerTag);
System.err.println("envelope: " + envelope);
System.err.println("properties: " + properties);
System.err.println("body: " + new String(body));
}
}什么是消费端限流? 假设RabbitMQ服务器有上万条未处理的消息,巨量的消息瞬间全部推送过来,但是我们单个客户端无法同时处理这么多数据! RabbitMQ消费端有两种消费消息后签收模式:自动签收、手动签收(推荐) RabbitMQ提供了一种QoS服务质量保证功能,即在非自动确认消息的前提下(设置非自动签收),如果一定数目的消息(通过基于consume 或者channel设置Qos的值)未被确认前,不进行消费新的消息. 消费端限流实现该方法channel.basicQos(0, 1, false); void BasicQos(uint prefetchSize,ushort prefetchCount,bool global) prefetchSize:设置监听消息的大小,一般设置为0,不限制 prefetchCount:会告诉RabbitMQ不要同时给一个消费者推送过多于N个消息,即一旦有N个消息还没有ack,则该consumer将block掉,直到 有消息ackglobal:true\false,是否将上面设置应用于channel,简单来说,就是上面限制是channel级别还是consumer级别
//1 限流方式第一件事就是autoAck设置为false
channel.basicQos(0, 1, false);
channel.basicConsume(queueName, false, new MyConsumer(channel));
public class MyConsumer extends DefaultConsumer {
private Channel channel ;
public MyConsumer(Channel channel) {
super(channel);
this.channel = channel;
}
@Override
public void handleDelivery(String consumerTag, Envelope envelope,
AMQP.BasicProperties properties, byte[] body) throws IOException {
System.err.println("-----------consume message----------");
System.err.println("consumerTag: " + consumerTag);
System.err.println("envelope: " + envelope);
System.err.println("properties: " + properties);
System.err.println("body: " + new String(body));
//核心代码,ack,false不支持批量签收
channel.basicAck(envelope.getDeliveryTag(), false);
}
}消费端的手工ACK和NACK 消费端重回队列是为了对没有处理成功的消息,把消息重新投递给Broker!一般我们在实际应用中,都会关闭重回队列,也就是设置 为false.
TTL是Time To Live的缩写,也就是生存时间 RabbitMQ支持消息的过期时间,在消息发送的时候可以指定 RabbitMQ支持队列的过期时间,从消息入队列开始计算,只要超过了队列的超时时间配置,那么消息就自动的清除
私信队列:DLX,Dead Letter Exchange 利用DLX,当消息在一个队列中变成死信(dead message)之后,它能被重新publish到另外一个Exchange,这个Exchange就是死信队列. 消息变成死信的几种情况 1) 消息被拒绝 2) 消息TTL过期 3) 队列达到最大长度 DLX也是一个正常的Exchange,和一般的Exchange没有区别,它能在任何的队列上被指定,实际上就是设置某个队列的属性. 当这个队列 中有死信时,RabbitMQ就会自动的将这个消息重新发布到设置的Exchange上去,进而被路由到另一个队列,可以监听这个队列中消息做相应的 处理.
感谢各位的阅读,以上就是“RabbitMQ的高级特性是什么”的内容了,经过本文的学习后,相信大家对RabbitMQ的高级特性是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





