本篇内容介绍了“BeautifulSoup的介绍及作用有哪些”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
from bs4 import BeautifulSoup html = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="story">Once upon a time there were three little sisters; and their names were </p> """ soup = BeautifulSoup(html, 'html.parser') print(soup.prettify())
from bs4 import BeautifulSoup with open(r"F:\tmp\etree.html") as fp: soup = BeautifulSoup(fp,"lxml") print(soup.prettify())
如果一个节点只包含文本节点,可以通过string直接访问文本节点
如果不止包含文本节点,那么string为None
如果不止包含文本节点,可以通过strings、stripped_strings获取文本节点内容,strings、stripped_strings获取的都是生成器。
只获取文本节点
soup.get_text()
#可以指定不同节点之间的文本使用|分割。
soup.get_text("|")
# 可以指定去除空格
soup.get_text("|", strip=True)tag.attrs是一个字典类型,可以通过tag['id']这样的方式获取值。下标访问的方式可能会抛出异常KeyError,所以可以使用tag.get('id')方式,如果id属性不存在,返回None。
都是节点的子节点,不过: contents是列表 children是生成器
contents、children只包含直接子节点,descendants也是一个生成器,不过包含节点的子孙节点
parent:父节点 parents:递归父节点
next_sibling:后一个兄弟节点 previous_sibling:前一个兄弟节点
next_element:后一个节点 previous_element:前一个节点
next_element与next_sibling的区别是:
next_sibling从当前tag的结束标签开始解析
next_element从当前tag的开始标签开始解析
find_parent:查找父节点 find_parents:递归查找父节点 find_next_siblings:查找后面的兄弟节点 find_next_sibling:查找后面满足条件的第一个兄弟节点 find_all_next:查找后面所有节点 find_next:查找后面第一个满足条件的节点 find_all_previous:查找前面所有满足条件的节点 find_previous:查找前面第一个满足条件的节点
# 查找所有p节点
soup.find_all('p')
# 查找title节点,不递归
soup.find_all("title", recursive=False)
# 查找p节点和span节点
soup.find_all(["p", "span"])
# 查找第一个a节点,和下面一个find等价
soup.find_all("a", limit=1)
soup.find('a')# 查找id为id1的节点
soup.find_all(id='id1')
# 查找name属性为tim的节点
soup.find_all(name="tim")
soup.find_all(attrs={"name": "tim"})
#查找class为clazz的p节点
soup.find_all("p", "clazz")
soup.find_all("p", class_="clazz")
soup.find_all("p", class_="body strikeout")import re
# 查找与p开头的节点
soup.find_all(class_=re.compile("^p"))# 查找有class属性并且没有id属性的节点
soup.find_all(hasClassNoId)
def hasClassNoId(tag):
return tag.has_attr('class') and not tag.has_attr('id')soup.find_all(string="tim")
soup.find_all(string=["alice", "tim", "allen"])
soup.find_all(string=re.compile("tim"))
def onlyTextTag(s):
return (s == s.parent.string)
# 查找只有文本节点的节点
soup.find_all(string=onlyTextTag)
# 查找文本节点为tim的a节点
soup.find_all("a", string="tim")相比于find,select方法就少了很多,就2个,一个是select,另一个是select_one,区别是select_one只选择满足条件的第一个元素。
select的重点在于选择器上,所以接下来我们重点通过介绍示例介绍一些常用的选择器。如果对应css选择器不熟悉的朋友,可以先看一下后面CSS选择器的介绍。
# 选择title节点
soup.select("title")
# 选择body节点下的所有a节点
soup.select("body a")
# 选择html节点下的head节点下的title节点
soup.select("html head title")通过tag选择非常简单,就是按层级,通过tag的名称使用空格分割就可以了。
# 选择类名为article的节点
soup.select(".article")
# 选择id为id1的a节点
soup.select("a#id1")
# 选择id为id1的节点
soup.select("#id1")
# 选择id为id1、id2的节点
soup.select("#id1,#id2")id和类选择器也比较简单,类选择器使用.开头,id选择器使用#开头。
# 选择有href属性的a节点
soup.select('a[href]')
# 选择href属性为http://mycollege.vip/tim的a节点
soup.select('a[href="http://mycollege.vip/tim"]')
# 选择href以http://mycollege.vip/开头的a节点
soup.select('a[href^="http://mycollege.vip/"]')
# 选择href以png结尾的a节点
soup.select('a[href$="png"]')
# 选择href属性包含china的a节点
soup.select('a[href*="china"]')
# 选择href属性包含china的a节点
soup.select("a[href~=china]")# 父节点为div节点的p节点
soup.select("div > p")
# 节点之前有div节点的p节点
soup.select("div + p")
# p节点之后的ul节点(p和ul有共同父节点)
soup.select("p~ul")
# 父节点中的第3个p节点
soup.select("p:nth-of-type(3)")最后我们还是通过一个小例子,来看一下BeautifulSoup的使用。
from bs4 import BeautifulSoup
text = '''
<li class="subject-item">
<div class="pic">
<a class="nbg" href="https://mycollege.vip/subject/25862578/">
<img class="" src="https://mycollege.vip/s27264181.jpg" width="90">
</a>
</div>
<div class="info">
<h3 class=""><a href="https://mycollege.vip/subject/25862578/" title="解忧杂货店">解忧杂货店</a></h3>
<div class="pub">[日] 东野圭吾 / 李盈春 / 南海出版公司 / 2014-5 / 39.50元</div>
<div class="star clearfix">
<span class="allstar45"></span>
<span class="rating_nums">8.5</span>
<span class="pl">
(537322人评价)
</span>
</div>
<p>现代人内心流失的东西,这家杂货店能帮你找回——僻静的街道旁有一家杂货店,只要写下烦恼投进卷帘门的投信口,
第二天就会在店后的牛奶箱里得到回答。因男友身患绝... </p>
</div>
</li>
'''
soup = BeautifulSoup(text, 'lxml')
print(soup.select_one("a.nbg").get("href"))
print(soup.find("img").get("src"))
title = soup.select_one("h3 a")
print(title.get("href"))
print(title.get("title"))
print(soup.find("div", class_="pub").string)
print(soup.find("span", class_="rating_nums").string)
print(soup.find("span", class_="pl").string.strip())
print(soup.find("p").string)非常简单,如果对CSS选择器熟悉的话,很多复杂的结构也能轻松搞定。
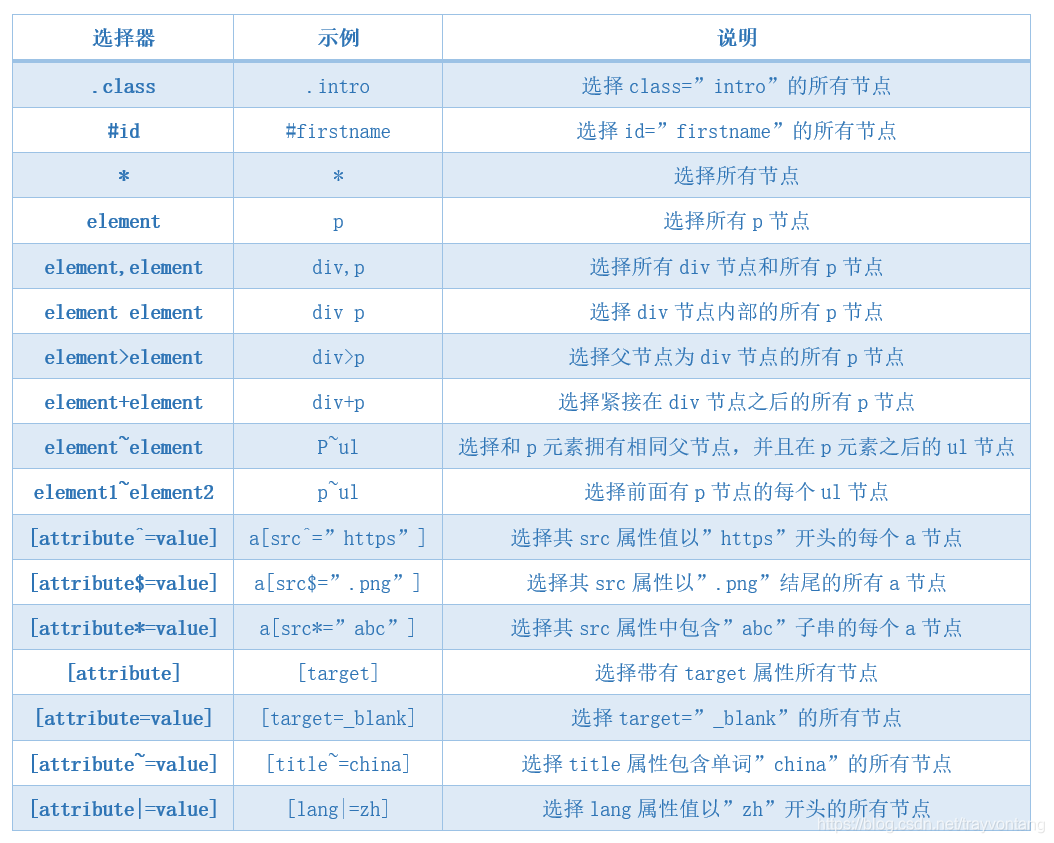
| 选择器 | 示例 | 说明 |
|---|---|---|
| .class | .intro | 选择class="intro"的所有节点 |
| #id | #firstname | 选择id="firstname"的所有节点 |
| * | * | 选择所有节点 |
| element | p | 选择所有p节点 |
| element,element | div,p | 选择所有div节点和所有p节点 |
| element element | div p | 选择div节点内部的所有p节点 |
| element>element | div>p | 选择父节点为div节点的所有p节点 |
| element+element | div+p | 选择紧接在div节点之后的所有p节点 |
| element~element | p~ul | 选择和p元素拥有相同父节点,并且在p元素之后的ul节点 |
| [attribute^=value] | a[src^="https"] | 选择其src属性值以"https"开头的每个a节点 |
| [attribute$=value] | a[src$=".png"] | 选择其src属性以".png"结尾的所有a节点 |
| [attribute*=value] | a[src*="abc"] | 选择其src属性中包含"abc"子串的每个a节点 |
| [attribute] | [target] | 选择带有target属性所有节点 |
| [attribute=value] | [target=_blank] | 选择target="_blank"的所有节点 |
| [attribute~=value] | [title~=china] | 选择title属性包含单词"china"的所有节点 |
| [attribute|=value] | [lang|=zh] | 选择lang属性值以"zh"开头的所有节点 |
div p是包含孙子节点,div > p只选择子节点
element~element选择器有点不好理解,看下面的例子:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<style>
p~ul {
background: red;
}
</style>
</head>
<body>
<div>
<ul>
<li>ul-li1</li>
<li>ul-li1</li>
<li>ul-li1</li>
</ul>
<p>p标签</p>
<ul>
<li>ul-li2</li>
<li>ul-li2</li>
<li>ul-li2</li>
</ul>
<h3>h3 tag</h3>
<ul>
<li>ul-li3</li>
<li>ul-li3</li>
<li>ul-li3</li>
</ul>
</div>
</body>
</html>
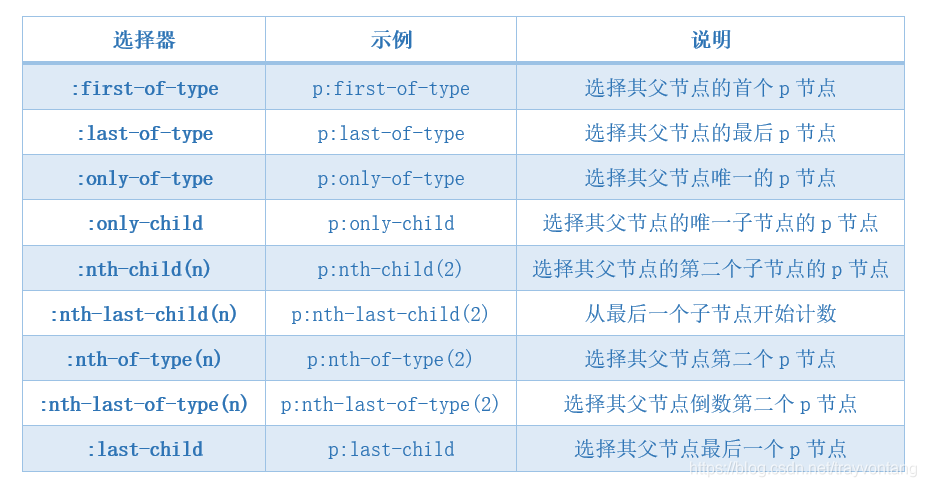
| 选择器 | 示例 | 说明 |
|---|---|---|
| :first-of-type | p:first-of-type | 选择其父节点的首个p节点 |
| :last-of-type | p:last-of-type | 选择其父节点的最后p节点 |
| :only-of-type | p:only-of-type | 选择其父节点唯一的p节点 |
| :only-child | p:only-child | 选择其父节点的唯一子节点的p节点 |
| :nth-child(n) | p:nth-child(2) | 选择其父节点的第二个子节点的p节点 |
| :nth-last-child(n) | p:nth-last-child(2) | 从最后一个子节点开始计数 |
| :nth-of-type(n) | p:nth-of-type(2) | 选择其父节点第二个p节点 |
| :nth-last-of-type(n) | p:nth-last-of-type(2) | 选择其父节点倒数第二个p节点 |
| :last-child | p:last-child | 选择其父节点最后一个p节点 |
需要主要的是tag:nth-child(n)与tag:nth-of-type(n),nth-child计算的时候不要求类型相同,nth-of-type计算的时候必须是相同的tag。
有点绕,可以看一下下面的示例。
<!DOCTYPE html>
<html>
<head>
<title>nth</title>
<style>
#wrap p:nth-of-type(3) {
background: red;
}
#wrap p:nth-child(3) {
background: yellow;
}
</style>
</head>
<body>
<div id="wrap">
<p>1-1p</p>
<div>2-1div</div>
<p>3-2p</p>
<p>4-3p</p>
<p>5-4p</p>
</div>
</body>
</html>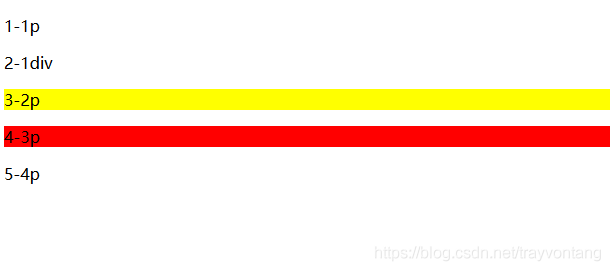
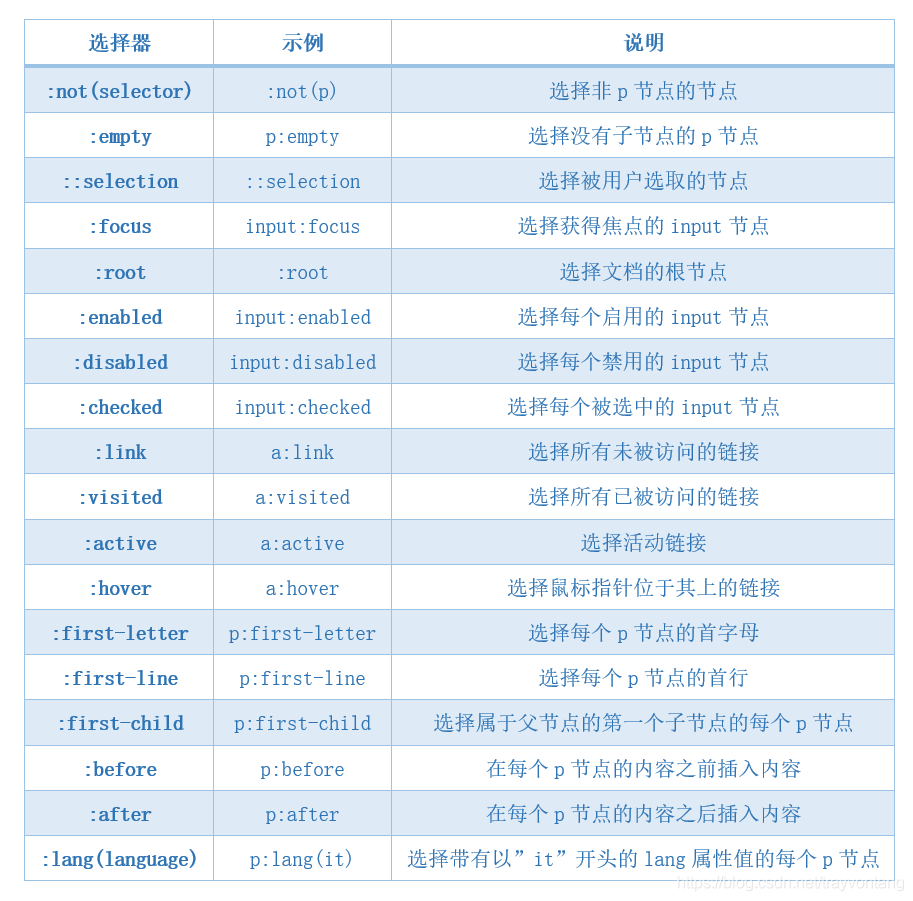
| 选择器 | 示例 | 说明 |
|---|---|---|
| :not(selector) | :not(p) | 选择非p节点的节点 |
| :empty | p:empty | 选择没有子节点的p节点 |
| ::selection | ::selection | 选择被用户选取的节点 |
| :focus | input:focus | 选择获得焦点的input节点 |
| :root | :root | 选择文档的根节点 |
| :enabled | input:enabled | 选择每个启用的input节点 |
| :disabled | input:disabled | 选择每个禁用的input节点 |
| :checked | input:checked | 选择每个被选中的input节点 |
| :link | a:link | 选择所有未被访问的链接 |
| :visited | a:visited | 选择所有已被访问的链接 |
| :active | a:active | 选择活动链接 |
| :hover | a:hover | 选择鼠标指针位于其上的链接 |
| :first-letter | p:first-letter | 选择每个p节点的首字母 |
| :first-line | p:first-line | 选择每个p节点的首行 |
| :first-child | p:first-child | 选择属于父节点的第一个子节点的每个p节点 |
| :before | p:before | 在每个p节点的内容之前插入内容 |
| :after | p:after | 在每个p节点的内容之后插入内容 |
| :lang(language) | p:lang(it) | 选择带有以"it"开头的lang属性值的每个p节点 |
“BeautifulSoup的介绍及作用有哪些”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





