Sharding-JDBC的架构以及源码的示例分析,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
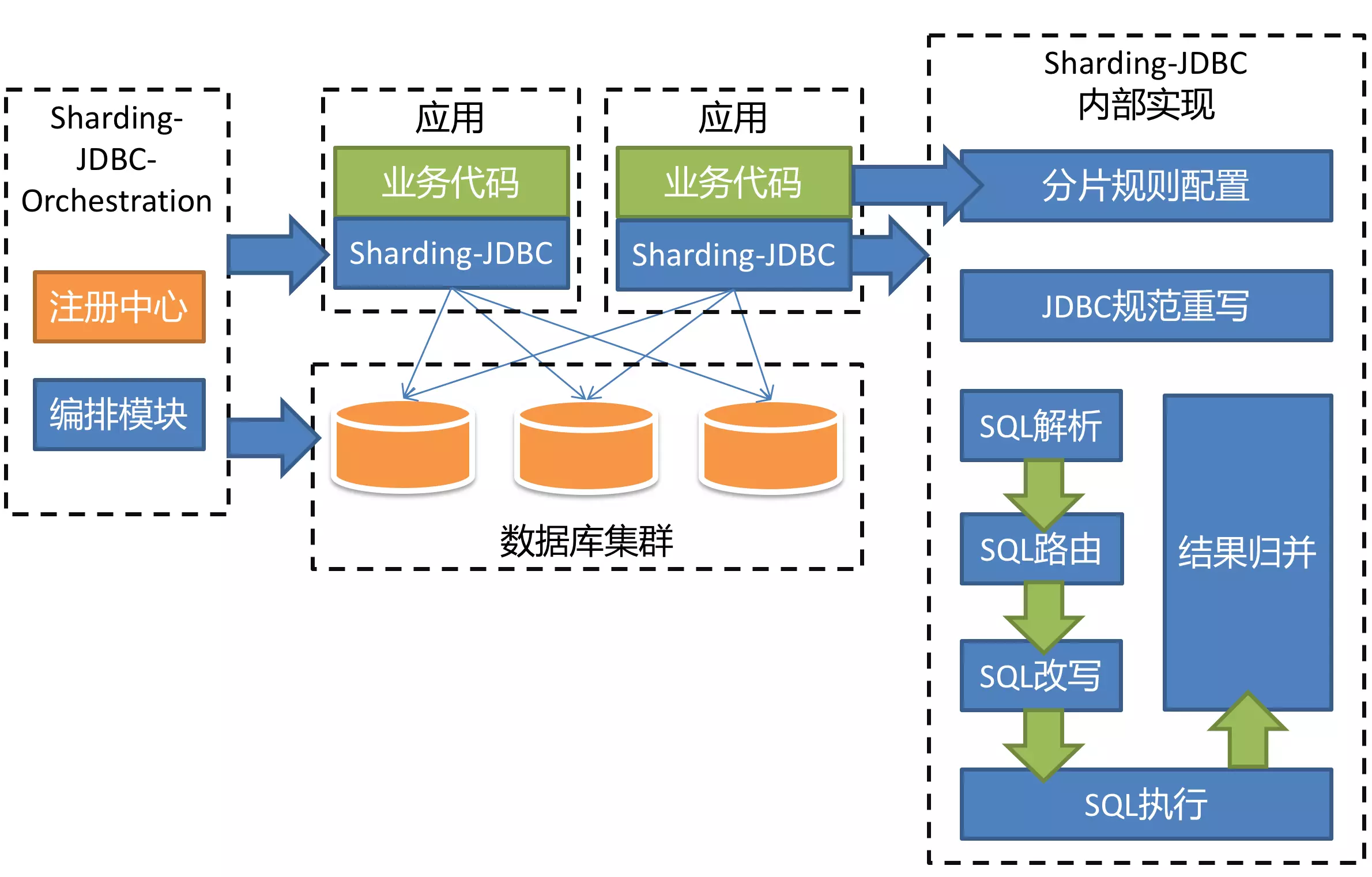
Sharding-jdbc 系统架构分成5个部分:
SQL解析
SQL路由
SQL改写
SQL执行
结果集归并
下面从上面五个部分来分析Sharding-jdbc
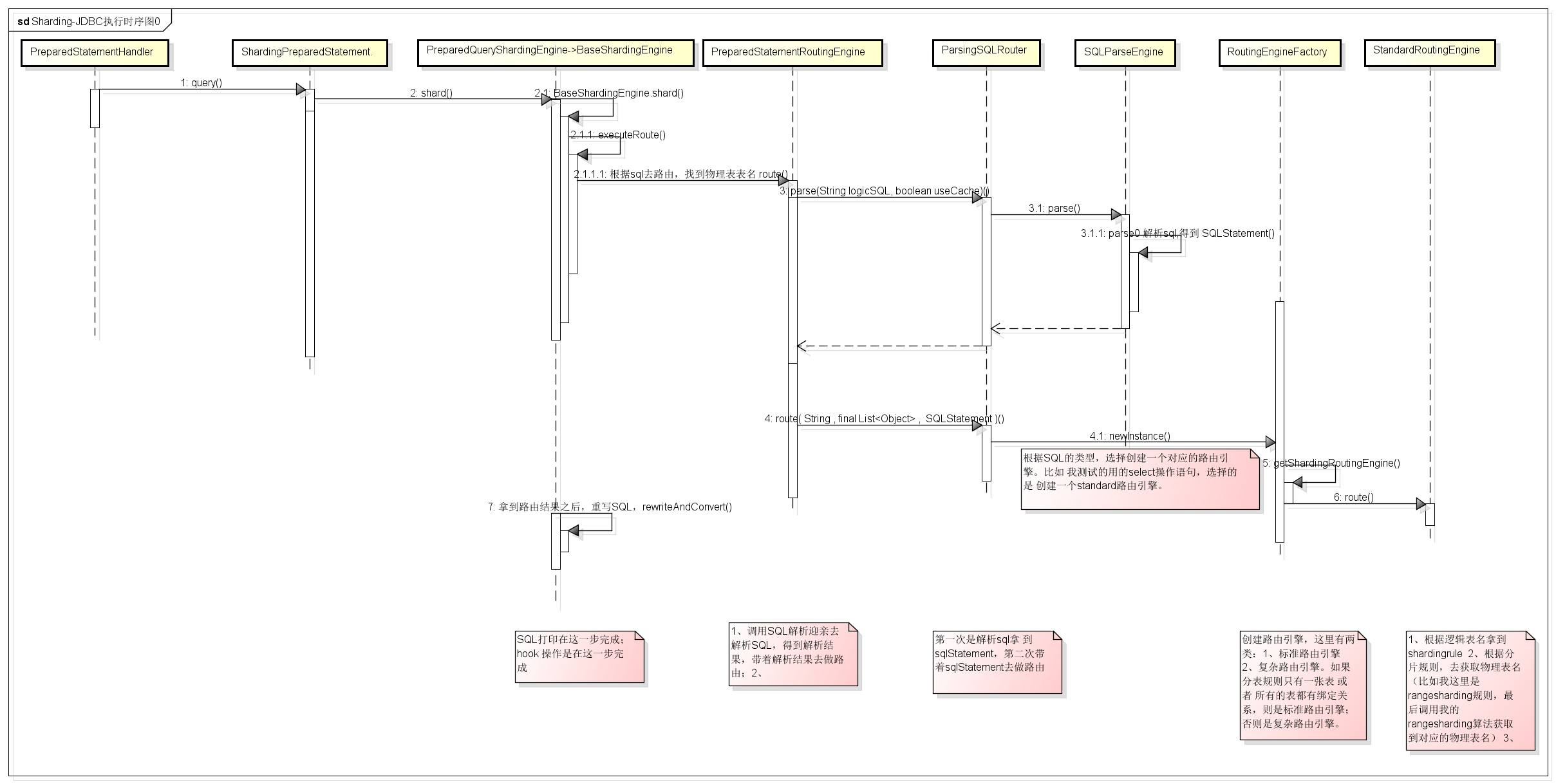
执行方法
org.apache.shardingsphere.shardingjdbc.jdbc.core.statement.ShardingPreparedStatement.execute()
方法源码
@Override
public boolean execute() throws SQLException {
try {
//本地缓存清空
clearPrevious();
/**
* 路由
*
*/
shard();
// 初始化 preparedStatement
initPreparedStatementExecutor();
// 执行sql
return preparedStatementExecutor.execute();
} finally {
clearBatch();
}
}org.apache.shardingsphere.core.BaseShardingEngine.shard(String, List<Object>)
public SQLRouteResult shard(final String sql, final List<Object> parameters) {
List<Object> clonedParameters = cloneParameters(parameters);
// 根据SQL去路由
SQLRouteResult result = executeRoute(sql, clonedParameters);
// 改写sql
result.getRouteUnits().addAll(HintManager.isDatabaseShardingOnly() ? convert(sql, clonedParameters, result) : rewriteAndConvert(sql, clonedParameters, result));
// 打印路由后的sql
if (shardingProperties.getValue(ShardingPropertiesConstant.SQL_SHOW)) {
boolean showSimple = shardingProperties.getValue(ShardingPropertiesConstant.SQL_SIMPLE);
SQLLogger.logSQL(sql, showSimple, result.getShardingStatement(), result.getRouteUnits());
}
return result;
}一些路由相关的hook在这里执行。
org.apache.shardingsphere.core.BaseShardingEngine.executeRoute(String, List<Object>)
private SQLRouteResult executeRoute(final String sql, final List<Object> clonedParameters) {
routingHook.start(sql);
try {
SQLRouteResult result = route(sql, clonedParameters);
routingHook.finishSuccess(result, metaData.getTables());
return result;
// CHECKSTYLE:OFF
} catch (final Exception ex) {
// CHECKSTYLE:ON
routingHook.finishFailure(ex);
throw ex;
}
}org.apache.shardingsphere.core.route.PreparedStatementRoutingEngine.route(List<Object>)
public SQLRouteResult route(final List<Object> parameters) {
if (null == sqlStatement) {
// 解析SQL
sqlStatement = shardingRouter.parse(logicSQL, true);
}
/**
* 第一步:根据上面异步解析出来的sqlStatement,结合配置的路由规则,找到对应的物理表表名
* 第二步:这里是主从(读写)路由,根据sql的类型(select、DML)决定走主库还是从库。
*/
return masterSlaveRouter.route(shardingRouter.route(logicSQL, parameters, sqlStatement));
}org.apache.shardingsphere.core.parse.SQLParseEngine.parse0(String, boolean)
private SQLStatement parse0(final String sql, final boolean useCache) {
……
// 创建一个根据数据库匹配的解析引擎,解析sql。比如mysql的sql创建mysql的数据解析引擎。
SQLStatement result = new SQLParseKernel(ParseRuleRegistry.getInstance(), databaseType, sql).parse();
if (useCache) {
cache.put(sql, result);
}
return result;
}这个是解析sql。这个方法不再深入了。
org.apache.shardingsphere.core.parse.core.SQLParseKernel.parse()
public SQLStatement parse() {
// 解析sql
SQLAST ast = parserEngine.parse();
// 抽取sql 片段
Collection<SQLSegment> sqlSegments = extractorEngine.extract(ast);
Map<ParserRuleContext, Integer> parameterMarkerIndexes = ast.getParameterMarkerIndexes();
return fillerEngine.fill(sqlSegments, parameterMarkerIndexes.size(), ast.getSqlStatementRule());
}org.apache.shardingsphere.core.route.router.sharding.ParsingSQLRouter.route(String, List<Object>, SQLStatement)
public SQLRouteResult route(final String logicSQL, final List<Object> parameters, final SQLStatement sqlStatement) {
/**
* 根据sql类型,生成不同的优化引擎。比如我这里调试用的是select语句,生成就是ShardingSelectOptimizeEngine 实例。
* 对 语句进行优化
*/
ShardingOptimizedStatement shardingStatement = ShardingOptimizeEngineFactory.newInstance(sqlStatement).optimize(shardingRule, metaData.getTables(), logicSQL, parameters, sqlStatement);
boolean needMergeShardingValues = isNeedMergeShardingValues(shardingStatement);
if (shardingStatement instanceof ShardingConditionOptimizedStatement && needMergeShardingValues) {
checkSubqueryShardingValues(shardingStatement, ((ShardingConditionOptimizedStatement) shardingStatement).getShardingConditions());
mergeShardingConditions(((ShardingConditionOptimizedStatement) shardingStatement).getShardingConditions());
}
/**
* 这里获取一个路由引擎,这里有各种引擎,常见的有 StandardRoutingEngine、ComplexRoutingEngine
* 这次获取的就是 获取一个 StandardRoutingEngine 路由引擎。(shardingtable数目为1,或者所有的表都是有绑定关系的)
* 接着执行 StandardRoutingEngine.route方法
*
*/
RoutingResult routingResult = RoutingEngineFactory.newInstance(shardingRule, metaData.getDataSources(), shardingStatement).route();
if (needMergeShardingValues) {
Preconditions.checkState(1 == routingResult.getRoutingUnits().size(), "Must have one sharding with subquery.");
}
// 分布式主键插入
if (shardingStatement instanceof ShardingInsertOptimizedStatement) {
setGeneratedValues((ShardingInsertOptimizedStatement) shardingStatement);
}
// 加密
EncryptOptimizedStatement encryptStatement = EncryptOptimizeEngineFactory.newInstance(sqlStatement)
.optimize(shardingRule.getEncryptRule(), metaData.getTables(), logicSQL, parameters, sqlStatement);
SQLRouteResult result = new SQLRouteResult(shardingStatement, encryptStatement);
result.setRoutingResult(routingResult);
return result;
}org.apache.shardingsphere.core.route.type.standard.StandardRoutingEngine.route()
public RoutingResult route() {
if (isDMLForModify(optimizedStatement.getSQLStatement()) && !optimizedStatement.getTables().isSingleTable()) {
throw new ShardingException("Cannot support Multiple-Table for '%s'.", optimizedStatement.getSQLStatement());
}
/**
* 1、根据逻辑表名去拿分表规则
* 2、根据分表规则 去拿DataNode(key 为 dataSourceName,value 为物理表表名)。
* 3、将上面的 dataNode 封装成 RoutingResult
*/
return generateRoutingResult(getDataNodes(shardingRule.getTableRule(logicTableName)));
}关于Sharding-JDBC的架构以及源码的示例分析问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





