[TOC]
在编写MapReduce程序时,我们会发现,对于MapReduce的输入输出数据(key-value),我们只能使用Hadoop提供的数据类型,而不能使用Java本身的基本数据类型,比如,如果数据类型为long,那么在编写MR程序时,对应Hadoop的数据类型则为LongWritable。关于原因,简单说明如下:
hadoop在节点间的内部通讯使用的是RPC,RPC协议把消息翻译成二进制字节流发送到远程节点,
远程节点再通过反序列化把二进制流转成原始的信息。也就是说,传递的消息内容是需要经过hadoop特定的序列化与反序列化操作的,因此,才需要使用hadoop提供的数据类型,当然,如果想要自定义MR程序中key-value的数据类型,则需要实现相应的接口,如Writable、WritableComparable接口。
也就是说,如果需要自定义key-value的数据类型,必须要遵循如下的原则:
/**
* MapReduce的任意的key和value都必须要实现Writable接口
* MapReduce的任意key必须实现WritableComparable接口,WritableComparable是Writable的增强版
* key还需要实现Comparable的原因在于,对key排序是MapReduce模型中的基本功能
*/其实前面写的很多Netty的文章,到了后面写编解码技术时,需要实现的功能与Hadoop是一样的,因为到最后的目的,我也是希望自己写一个RPC框架(模仿阿里的dubbo)。
关于Writable接口,源代码中的解释就非常好了:
/**
* A serializable object which implements a simple, efficient, serialization
* protocol, based on {@link DataInput} and {@link DataOutput}.
*
* <p>Any <code>key</code> or <code>value</code> type in the Hadoop Map-Reduce
* framework implements this interface.</p>
*
* <p>Implementations typically implement a static <code>read(DataInput)</code>
* method which constructs a new instance, calls {@link #readFields(DataInput)}
* and returns the instance.</p>
*
* <p>Example:</p>
* <p><blockquote><pre>
* public class MyWritable implements Writable {
* // Some data
* private int counter;
* private long timestamp;
*
* public void write(DataOutput out) throws IOException {
* out.writeInt(counter);
* out.writeLong(timestamp);
* }
*
* public void readFields(DataInput in) throws IOException {
* counter = in.readInt();
* timestamp = in.readLong();
* }
*
* public static MyWritable read(DataInput in) throws IOException {
* MyWritable w = new MyWritable();
* w.readFields(in);
* return w;
* }
* }
* </pre></blockquote></p>
*/直接给出官方源码中的解释:
/**
* A {@link Writable} which is also {@link Comparable}.
*
* <p><code>WritableComparable</code>s can be compared to each other, typically
* via <code>Comparator</code>s. Any type which is to be used as a
* <code>key</code> in the Hadoop Map-Reduce framework should implement this
* interface.</p>
*
* <p>Note that <code>hashCode()</code> is frequently used in Hadoop to partition
* keys. It's important that your implementation of hashCode() returns the same
* result across different instances of the JVM. Note also that the default
* <code>hashCode()</code> implementation in <code>Object</code> does <b>not</b>
* satisfy this property.</p>
*
* <p>Example:</p>
* <p><blockquote><pre>
* public class MyWritableComparable implements WritableComparable<MyWritableComparable> {
* // Some data
* private int counter;
* private long timestamp;
*
* public void write(DataOutput out) throws IOException {
* out.writeInt(counter);
* out.writeLong(timestamp);
* }
*
* public void readFields(DataInput in) throws IOException {
* counter = in.readInt();
* timestamp = in.readLong();
* }
*
* public int compareTo(MyWritableComparable o) {
* int thisValue = this.value;
* int thatValue = o.value;
* return (thisValue < thatValue ? -1 : (thisValue==thatValue ? 0 : 1));
* }
*
* public int hashCode() {
* final int prime = 31;
* int result = 1;
* result = prime * result + counter;
* result = prime * result + (int) (timestamp ^ (timestamp >>> 32));
* return result
* }
* }
* </pre></blockquote></p>
*/下图是电信一段日志记录的表结构,现需要统计每一个手机号码的upPackNum、downPackNum、upPayLoad、downPayLoad的总和。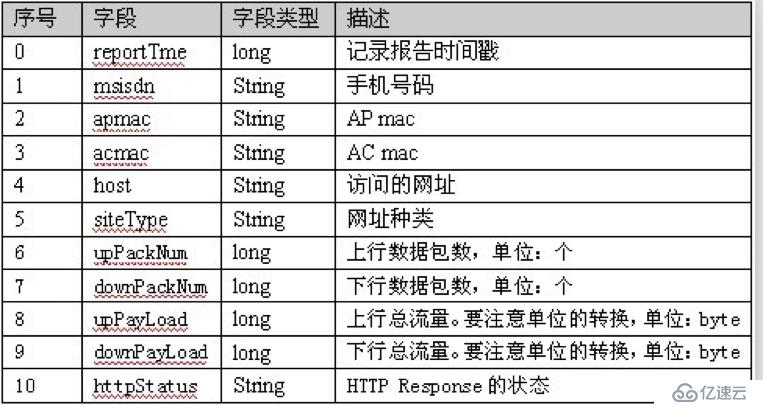
要求:使用自定义Writable完成。
提供的文本数据如下:
1363157985066,13726230503,00-FD-07-A4-72-B8:CMCC,120.196.100.82,i02.c.aliimg.com,,24,27,2481,24681,200
1363157995052,13826544101,5C-0E-8B-C7-F1-E0:CMCC,120.197.40.4,,,4,0,264,0,200
1363157991076,13926435656,20-10-7A-28-CC-0A:CMCC,120.196.100.99,,,2,4,132,1512,200
1363154400022,13926251106,5C-0E-8B-8B-B1-50:CMCC,120.197.40.4,,,4,0,240,0,200
1363157993044,18211575961,94-71-AC-CD-E6-18:CMCC-EASY,120.196.100.99,iface.qiyi.com,视频网站,15,12,1527,2106,200
1363157995074,84138413,5C-0E-8B-8C-E8-20:7DaysInn,120.197.40.4,122.72.52.12,,20,16,4116,1432,200
1363157993055,13560439658,C4-17-FE-BA-DE-D9:CMCC,120.196.100.99,,,18,15,1116,954,200
1363157995033,15920133257,5C-0E-8B-C7-BA-20:CMCC,120.197.40.4,sug.so.360.cn,信息安全,20,20,3156,2936,200
1363157983019,13719199419,68-A1-B7-03-07-B1:CMCC-EASY,120.196.100.82,,,4,0,240,0,200
1363157984041,13660577991,5C-0E-8B-92-5C-20:CMCC-EASY,120.197.40.4,s19.cnzz.com,站点统计,24,9,6960,690,200
1363157973098,15013685858,5C-0E-8B-C7-F7-90:CMCC,120.197.40.4,rank.ie.sogou.com,搜索引擎,28,27,3659,3538,200
1363157986029,15989002119,E8-99-C4-4E-93-E0:CMCC-EASY,120.196.100.99,www.umeng.com,站点统计,3,3,1938,180,200
1363157992093,13560439658,C4-17-FE-BA-DE-D9:CMCC,120.196.100.99,,,15,9,918,4938,200
1363157986041,13480253104,5C-0E-8B-C7-FC-80:CMCC-EASY,120.197.40.4,,,3,3,180,180,200
1363157984040,13602846565,5C-0E-8B-8B-B6-00:CMCC,120.197.40.4,2052.flash3-http.qq.com,综合门户,15,12,1938,2910,200
1363157995093,13922314466,00-FD-07-A2-EC-BA:CMCC,120.196.100.82,img.qfc.cn,,12,12,3008,3720,200
1363157982040,13502468823,5C-0A-5B-6A-0B-D4:CMCC-EASY,120.196.100.99,y0.ifengimg.com,综合门户,57,102,7335,110349,200
1363157986072,18320173382,84-25-DB-4F-10-1A:CMCC-EASY,120.196.100.99,input.shouji.sogou.com,搜索引擎,21,18,9531,2412,200
1363157990043,13925057413,00-1F-64-E1-E6-9A:CMCC,120.196.100.55,t3.baidu.com,搜索引擎,69,63,11058,48243,200
1363157988072,13760778710,00-FD-07-A4-7B-08:CMCC,120.196.100.82,,,2,2,120,120,200
1363157985079,13823070001,20-7C-8F-70-68-1F:CMCC,120.196.100.99,,,6,3,360,180,200
1363157985069,13600217502,00-1F-64-E2-E8-B1:CMCC,120.196.100.55,,,18,138,1080,186852,200下面就基于Writable接口写一个HttpDataWritable类,代码如下:
package com.uplooking.bigdata.mr.http;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* MapReduce的任意的key和value都必须要实现Writable接口
* MapReduce的任意key必须实现WritableComparable接口,WritableComparable是Writable的增强版
*/
public class HttpDataWritable implements Writable {
private long upPackNum;
private long downPackNum;
private long upPayLoad;
private long downPayLoad;
public HttpDataWritable() {
}
public HttpDataWritable(long upPackNum, long downPackNum, long upPayLoad, long downPayLoad) {
this.upPackNum = upPackNum;
this.downPackNum = downPackNum;
this.upPayLoad = upPayLoad;
this.downPayLoad = downPayLoad;
}
public void write(DataOutput out) throws IOException {
out.writeLong(upPackNum);
out.writeLong(downPackNum);
out.writeLong(upPayLoad);
out.writeLong(downPayLoad);
}
public void readFields(DataInput in) throws IOException {
this.upPackNum = in.readLong();
this.downPackNum = in.readLong();
this.upPayLoad = in.readLong();
this.downPayLoad = in.readLong();
}
public long getUpPackNum() {
return upPackNum;
}
public void setUpPackNum(long upPackNum) {
this.upPackNum = upPackNum;
}
public long getDownPackNum() {
return downPackNum;
}
public void setDownPackNum(long downPackNum) {
this.downPackNum = downPackNum;
}
public long getUpPayLoad() {
return upPayLoad;
}
public void setUpPayLoad(long upPayLoad) {
this.upPayLoad = upPayLoad;
}
public long getDownPayLoad() {
return downPayLoad;
}
public void setDownPayLoad(long downPayLoad) {
this.downPayLoad = downPayLoad;
}
@Override
public String toString() {
return upPackNum + "\t" + downPackNum + "\t" +
upPayLoad + "\t" + downPayLoad;
}
}
程序代码如下:
package com.uplooking.bigdata.mr.http;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class HttpDataJob {
public static void main(String[] args) throws Exception {
if (args == null || args.length < 2) {
System.err.println("Parameter Errors! Usages:<inputpath> <outputpath>");
System.exit(-1);
}
Path inputPath = new Path(args[0]);
Path outputPath = new Path(args[1]);
Configuration conf = new Configuration();
String jobName = HttpDataJob.class.getSimpleName();
Job job = Job.getInstance(conf, jobName);
//设置job运行的jar
job.setJarByClass(HttpDataJob.class);
//设置整个程序的输入
FileInputFormat.setInputPaths(job, inputPath);
job.setInputFormatClass(TextInputFormat.class);//就是设置如何将输入文件解析成一行一行内容的解析类
//设置mapper
job.setMapperClass(HttpDataMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(HttpDataWritable.class);
//设置整个程序的输出
// outputpath.getFileSystem(conf).delete(outputpath, true);//如果当前输出目录存在,删除之,以避免.FileAlreadyExistsException
FileOutputFormat.setOutputPath(job, outputPath);
job.setOutputFormatClass(TextOutputFormat.class);
//设置reducer
job.setReducerClass(HttpDataReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(HttpDataWritable.class);
//指定程序有几个reducer去运行
job.setNumReduceTasks(1);
//提交程序
job.waitForCompletion(true);
}
public static class HttpDataMapper extends Mapper<LongWritable, Text, Text, HttpDataWritable> {
@Override
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {
String line = v1.toString();
String[] items = line.split(",");
// 获取手机号码
String phoneNum = items[1];
// 获取upPackNum、downPackNum、upPayLoad、downPayLoad
long upPackNum = Long.parseLong(items[6]);
long downPackNum = Long.parseLong(items[7]);
long upPayLoad = Long.parseLong(items[8]);
long downPayLoad = Long.parseLong(items[9]);
// 构建HttpDataWritable对象
HttpDataWritable httpData = new HttpDataWritable(upPackNum, downPackNum, upPayLoad, downPayLoad);
// 写出数据到context
context.write(new Text(phoneNum), httpData);
}
}
public static class HttpDataReducer extends Reducer<Text, HttpDataWritable, Text, HttpDataWritable> {
@Override
protected void reduce(Text k2, Iterable<HttpDataWritable> v2s, Context context) throws IOException, InterruptedException {
long upPackNum = 0L;
long downPackNum = 0L;
long upPayLoad = 0L;
long downPayLoad = 0L;
// 遍历v2s,计算各个参数的总和
for(HttpDataWritable htd : v2s) {
upPackNum += htd.getUpPackNum();
downPackNum += htd.getDownPackNum();
upPayLoad += htd.getUpPayLoad();
downPayLoad += htd.getDownPayLoad();
}
// 构建HttpDataWritable对象
HttpDataWritable httpData = new HttpDataWritable(upPackNum, downPackNum, upPayLoad, downPayLoad);
// 写出数据到context
context.write(k2, httpData);
}
}
}注意,上面的程序是需要读取命令行的参数输入的,可以在本地的环境执行,也可以打包成一个jar包上传到Hadoop环境的Linux服务器上执行,这里,我使用的是本地环境(我的操作系统是Mac OS),输入的参数如下:
/Users/yeyonghao/data/input/HTTP_20160415143750.dat /Users/yeyonghao/data/output/mr/http/h-1运行程序后,查看输出结果,如下:
yeyonghao@yeyonghaodeMacBook-Pro:~/data/output/mr/http/h-1$ cat part-r-00000
13480253104 3 3 180 180
13502468823 57 102 7335 110349
13560439658 33 24 2034 5892
13600217502 18 138 1080 186852
13602846565 15 12 1938 2910
13660577991 24 9 6960 690
13719199419 4 0 240 0
13726230503 24 27 2481 24681
13760778710 2 2 120 120
13823070001 6 3 360 180
13826544101 4 0 264 0
13922314466 12 12 3008 3720
13925057413 69 63 11058 48243
13926251106 4 0 240 0
13926435656 2 4 132 1512
15013685858 28 27 3659 3538
15920133257 20 20 3156 2936
15989002119 3 3 1938 180
18211575961 15 12 1527 2106
18320173382 21 18 9531 2412
84138413 20 16 4116 1432说明我们的MapReduce程序没有问题,并且写的HttpDataWritable类也是可以正常使用的。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





