本篇内容主要讲解“怎么打造高性能的 Go 缓存库”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“怎么打造高性能的 Go 缓存库”吧!
我在看一些优秀的开源库的时候看到一个有意思的缓存库 fastcache,在它的介绍主要有以下几点特点:
读写数据要快,即使在并发下;
即使在数 GB 的缓存中,也要保持很好的性能,以及尽可能减少 GC 次数;
设计尽可能简单;
本文会通过模仿它写一个简单的缓存库,从而研究其内核是如何实现这样的目标的。希望各位能有所收获。
在项目中,我们经常会用到 Go 缓存库比如说 patrickmn/go-cache库。但很多缓存库其实都是用一个简单的 Map 来存放数据,这些库在使用的时候,当并发低,数据量少的时候是没有问题的,但是在数据量比较大并发比较高的时候会延长 GC 时间,增加内存分配次数。
比如,我们使用一个简单的例子:
func main() { a := make(map[string]string, 1e9) for i := 0; i < 10; i++ { runtime.GC() } runtime.KeepAlive(a) }在这个例子中,预分配了大小是10亿(1e9) 的 map,然后我们通过 gctrace 输出一下 GC 情况:
做实验的环境是 Linux,机器配置是 16C 8G ,想要更深入理解 GC,可以看这篇:《 Go 语言 GC 实现原理及源码分析 https://www.luozhiyun.com/archives/475 》
[root@localhost gotest]# GODEBUG=gctrace=1 go run main.go ... gc 6 @13.736s 17%: 0.010+1815+0.004 ms clock, 0.17+0/7254/21744+0.067 ms cpu, 73984->73984->73984 MB, 147968 MB goal, 16 P (forced) gc 7 @15.551s 18%: 0.012+1796+0.005 ms clock, 0.20+0/7184/21537+0.082 ms cpu, 73984->73984->73984 MB, 147968 MB goal, 16 P (forced) gc 8 @17.348s 19%: 0.008+1794+0.004 ms clock, 0.14+0/7176/21512+0.070 ms cpu, 73984->73984->73984 MB, 147968 MB goal, 16 P (forced) gc 9 @19.143s 19%: 0.010+1819+0.005 ms clock, 0.16+0/7275/21745+0.085 ms cpu, 73984->73984->73984 MB, 147968 MB goal, 16 P (forced) gc 10 @20.963s 19%: 0.011+1844+0.004 ms clock, 0.18+0/7373/22057+0.076 ms cpu, 73984->73984->73984 MB, 147968 MB goal, 16 P (forced)上面展示了最后 5 次 GC 的情况,下面我们看看具体的含义是什么:
gc 1 @0.004s 4%: 0.22+1.4+0.021 ms clock, 1.7+0.009/0.40/0.073+0.16 ms cpu, 4->5->1 MB, 5 MB goal, 8 P gc 10 @20.963s 19%: 0.011+1844+0.004 ms clock, 0.18+0/7373/22057+0.076 ms cpu, 73984->73984->73984 MB, 147968 MB goal, 16 P (forced) gc 10 :程序启动以来第10次GC @20.963s:距离程序启动到现在的时间 19%:当目前为止,GC 的标记工作所用的CPU时间占总CPU的百分比垃圾回收的时间
gc 1 @0.004s 4%: 0.22+1.4+0.021 ms clock, 1.7+0.009/0.40/0.073+0.16 ms cpu, 4->5->1 MB, 5 MB goal, 8 P gc 10 @20.963s 19%: 0.011+1844+0.004 ms clock, 0.18+0/7373/22057+0.076 ms cpu, 73984->73984->73984 MB, 147968 MB goal, 16 P (forced) gc 10 :程序启动以来第10次GC @20.963s:距离程序启动到现在的时间 19%:当目前为止,GC 的标记工作所用的CPU时间占总CPU的百分比 垃圾回收的时间 0.011 ms:标记开始 STW 时间 1844 ms:并发标记时间 0.004 ms:标记终止 STW 时间 垃圾回收占用cpu时间 0.18 ms:标记开始 STW 时间 0 ms:mutator assists占用的时间 7373 ms:标记线程占用的时间 22057 ms:idle mark workers占用的时间 0.076 ms:标记终止 STW 时间 内存 73984 MB:标记开始前堆占用大小 73984 MB:标记结束后堆占用大小 73984 MB:标记完成后存活堆的大小 147968 MB goal:标记完成后正在使用的堆内存的目标大小 16 P:使用了多少处理器可以从上面的输出看到每次 GC 处理的时间非常的长,占用的 CPU 资源也非常多。那么造成这样的原因是什么呢?
string 实际上底层数据结构是由两部分组成,其中包含指向字节数组的指针和数组的大小:
type StringHeader struct { Data uintptr Len int }由于 StringHeader中包含指针,所以每次 GC 的时候都会扫描每个指针,那么在这个巨大的 map中是包含了非常多的指针的,所以造成了巨大的资源消耗。
在上面的例子 map a 中数据大概是这样存储:
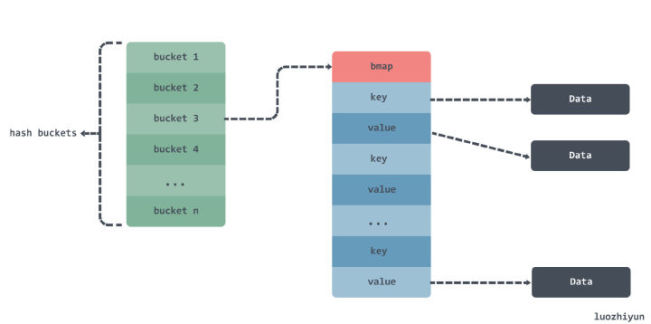
一个 map 中里面有多个 bucket ,bucket 里面有一个 bmap 数组用来存放数据,但是由于 key 和 value 都是 string 类型的,所以在 GC 的时候还需要根据 StringHeader中的 Data指针扫描 string 数据。
对于这种情况,如果所有的 string 字节都在一个单一内存片段中,我们就可以通过偏移来追踪某个字符串在这段内存中的开始和结束位置。通过追踪偏移,我们不在需要在我们大数组中存储指针,GC 也不在会被困扰。如下:
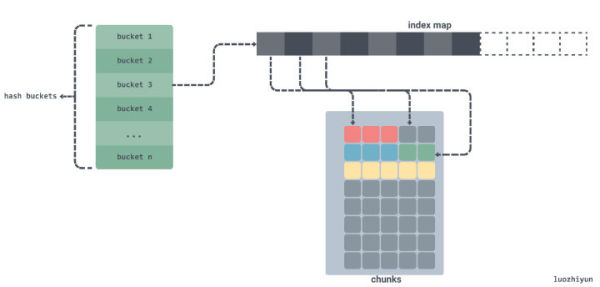
如同上面所示,如果我们将字符串中的字节数据拷贝到一个连续的字节数组 chunks 中,并为这个字节数组提前分配好内存,并且仅存储字符串在数组中的偏移而不是指针。
除了上面所说的优化内容以外,还有其他的方法吗?
其实我们还可以直接从系统 OS 中调用 mmap syscall 进行内存分配,这样 GC 就永远不会对这块内存进行内存管理,因此也就不会扫描到它。如下:
func main() { test := "hello syscall" data, _ := syscall.Mmap(-1, 0, 13, syscall.PROT_READ|syscall.PROT_WRITE, syscall.MAP_ANON|syscall.MAP_PRIVATE) p := (*[13]byte)(unsafe.Pointer(&data[0])) for i := 0; i < 13; i++ { p[i] = test[i] } fmt.Println(string(p[:])) }通过系统调用直接向 OS 申请了 13bytes 的内存,然后将一个字符串写入到申请的内存数组中。
所以我们也可以通过提前向 OS 申请一块内存,而不是用的时候才申请内存,减少频繁的内存分配从而达到提高性能的目的。
我们在开发前先把这个库的 API 定义一下:
func New(maxBytes int) *Cache创建一个 Cache 结构体,传入预设的缓存大小,单位是字节。
func (c *Cache) Get(k []byte) []byte获取 Cache 中的值,传入的参数是 byte 数组。
func (c *Cache) Set(k, v []byte)设置键值对到缓存中,k 是键,v 是值,参数都是 byte 数组。
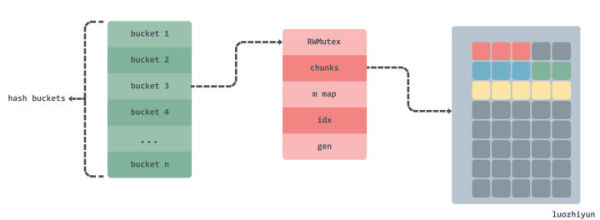
const bucketsCount = 512 type Cache struct { buckets [bucketsCount]bucket } type bucket struct { // 读写锁 mu sync.RWMutex // 二维数组,存放数据的地方,是一个环形链表 chunks [][]byte // 索引字典 m map[uint64]uint64 // 索引值 idx uint64 // chunks 被重写的次数,用来校验环形链表中数据有效性 gen uint64 }通过我们上面的分析,可以看到,实际上真正存放数据的地方是 chunks 二维数组,在实现上是通过 m 字段来映射索引路径,根据 chunks 和 gen 两个字段来构建一个环形链表,环形链表每转一圈 gen 就会加一。
func New(maxBytes int) *Cache { if maxBytes <= 0 { panic(fmt.Errorf("maxBytes must be greater than 0; got %d", maxBytes)) } var c Cache // 算出每个桶的大小 maxBucketBytes := uint64((maxBytes + bucketsCount - 1) / bucketsCount) for i := range c.buckets[:] { // 对桶进行初始化 c.buckets[i].Init(maxBucketBytes) } return &c }我们会设置一个 New 函数来初始化我们 Cache 结构体,在 Cache 结构体中会将缓存的数据大小平均分配到每个桶中,然后对每个桶进行初始化。
const bucketSizeBits = 40 const maxBucketSize uint64 = 1 << bucketSizeBits const chunkSize = 64 * 1024 func (b *bucket) Init(maxBytes uint64) { if maxBytes == 0 { panic(fmt.Errorf("maxBytes cannot be zero")) } // 我们这里限制每个桶最大的大小是 1024 GB if maxBytes >= maxBucketSize { panic(fmt.Errorf("too big maxBytes=%d; should be smaller than %d", maxBytes, maxBucketSize)) } // 初始化 Chunks 中每个 Chunk 大小为 64 KB,计算 chunk 数量 maxChunks := (maxBytes + chunkSize - 1) / chunkSize b.chunks = make([][]byte, maxChunks) b.m = make(map[uint64]uint64) // 初始化 bucket 结构体 b.Reset() }在这里会将桶里面的内存按 chunk 进行分配,每个 chunk 占用内存约为 64 KB。在最后会调用 bucket 的 Reset 方法对 bucket 结构体进行初始化。
func (b *bucket) Reset() { b.mu.Lock() chunks := b.chunks // 遍历 chunks for i := range chunks { // 将 chunk 中的内存归还到缓存中 putChunk(chunks[i]) chunks[i] = nil } // 删除索引字典中所有的数据 bm := b.m for k := range bm { delete(bm, k) } b.idx = 0 b.gen = 1 b.mu.Unlock() }Reset 方法十分简单,主要就是清空 chunks 数组、删除索引字典中所有的数据以及重置索引 idx 和 gen 的值。
在上面这个方法中有一个 putChunk ,其实这个就是直接操作我们提前向 OS 申请好的内存,相应的还有一个 getChunk 方法。下面我们具体看看 Chunk 的操作。
const chunksPerAlloc = 1024 const chunkSize = 64 * 1024 var ( freeChunks []*[chunkSize]byte freeChunksLock sync.Mutex ) func getChunk() []byte { freeChunksLock.Lock() if len(freeChunks) == 0 { // 分配 64 * 1024 * 1024 = 64 MB 内存 data, err := syscall.Mmap(-1, 0, chunkSize*chunksPerAlloc, syscall.PROT_READ|syscall.PROT_WRITE, syscall.MAP_ANON|syscall.MAP_PRIVATE) if err != nil { panic(fmt.Errorf("cannot allocate %d bytes via mmap: %s", chunkSize*chunksPerAlloc, err)) } // 循环遍历 data 数据 for len(data) > 0 { //将从系统分配的内存分为 64 * 1024 = 64 KB 大小,存放到 freeChunks中 p := (*[chunkSize]byte)(unsafe.Pointer(&data[0])) freeChunks = append(freeChunks, p) data = data[chunkSize:] } } //从 freeChunks 获取最后一个元素 n := len(freeChunks) - 1 p := freeChunks[n] freeChunks[n] = nil freeChunks = freeChunks[:n] freeChunksLock.Unlock() return p[:] }初次调用 getChunk 函数时会使用系统调用分配 64MB 的内存,然后循环将内存切成 1024 份,每份 64KB 放入到 freeChunks 空闲列表中。然后获取每次都获取 freeChunks 空闲列表最后一个元素 64KB 内存返回。需要注意的是 getChunk 会下下面将要介绍到的 Cache 的 set 方法中使用到,所以需要考虑到并发问题,所以在这里加了锁。
func putChunk(chunk []byte) { if chunk == nil { return } chunk = chunk[:chunkSize] p := (*[chunkSize]byte)(unsafe.Pointer(&chunk[0])) freeChunksLock.Lock() freeChunks = append(freeChunks, p) freeChunksLock.Unlock() }putChunk 函数就是将内存数据还回到 freeChunks 空闲列表中,会在 bucket 的 Reset 方法中被调用。
const bucketsCount = 512 func (c *Cache) Set(k, v []byte) { h := xxhash.Sum64(k) idx := h % bucketsCount c.buckets[idx].Set(k, v, h) }Set 方法里面会根据 k 的值做一个 hash,然后取模映射到 buckets 桶中,这里用的 hash 库是 cespare/xxhash。
最主要的还是 buckets 里面的 Set 方法:
func (b *bucket) Set(k, v []byte, h uint64) { // 限定 k v 大小不能超过 2bytes if len(k) >= (1<<16) || len(v) >= (1<<16) { return } // 4个byte 设置每条数据的数据头 var kvLenBuf [4]byte kvLenBuf[0] = byte(uint16(len(k)) >> 8) kvLenBuf[1] = byte(len(k)) kvLenBuf[2] = byte(uint16(len(v)) >> 8) kvLenBuf[3] = byte(len(v)) kvLen := uint64(len(kvLenBuf) + len(k) + len(v)) // 校验一下大小 if kvLen >= chunkSize { return } b.mu.Lock() // 当前索引位置 idx := b.idx // 存放完数据后索引的位置 idxNew := idx + kvLen // 根据索引找到在 chunks 的位置 chunkIdx := idx / chunkSize chunkIdxNew := idxNew / chunkSize // 新的索引是否超过当前索引 // 因为还有chunkIdx等于chunkIdxNew情况,所以需要先判断一下 if chunkIdxNew > chunkIdx { // 校验是否新索引已到chunks数组的边界 // 已到边界,那么循环链表从头开始 if chunkIdxNew >= uint64(len(b.chunks)) { idx = 0 idxNew = kvLen chunkIdx = 0 b.gen++ // 当 gen 等于 1<<genSizeBits时,才会等于0 // 也就是用来限定 gen 的边界为1<<genSizeBits if b.gen&((1<<genSizeBits)-1) == 0 { b.gen++ } } else { // 未到 chunks数组的边界,从下一个chunk开始 idx = chunkIdxNew * chunkSize idxNew = idx + kvLen chunkIdx = chunkIdxNew } // 重置 chunks[chunkIdx] b.chunks[chunkIdx] = b.chunks[chunkIdx][:0] } chunk := b.chunks[chunkIdx] if chunk == nil { chunk = getChunk() // 清空切片 chunk = chunk[:0] } // 将数据 append 到 chunk 中 chunk = append(chunk, kvLenBuf[:]...) chunk = append(chunk, k...) chunk = append(chunk, v...) b.chunks[chunkIdx] = chunk // 因为 idx 不能超过bucketSizeBits,所以用一个 uint64 同时表示gen和idx // 所以高于bucketSizeBits位置表示gen // 低于bucketSizeBits位置表示idx b.m[h] = idx | (b.gen << bucketSizeBits) b.idx = idxNew b.mu.Unlock() }鸿蒙官方战略合作共建——HarmonyOS技术社区
在这段代码开头实际上我会限制键值的大小不能超过 2bytes;
然后将 2bytes 大小长度的键值封装到 4bytes 的 kvLenBuf 作为数据头,数据头和键值的总长度是不能超过一个 chunk 长度,也就是 64 * 1024;
然后计算出原索引 chunkIdx 和新索引 chunkIdxNew,用来判断这次添加的数据加上原来的数据有没有超过一个 chunk 长度;
根据新的索引找到对应的 chunks 中的位置,然后将键值以及 kvLenBuf 追加到 chunk 后面;
设置新的 idx 以及 m 字典对应的值,m 字典中存放的是 gen 和 idx 通过取与的放置存放。
在 Set 一个键值对会有 4bytes 的 kvLenBuf 作为数据头,后面的数据会接着 key 和 value ,在 kvLenBuf 中,前两个 byte 分别代表了 key 长度的低位和高位;后两个 byte 分别代表了 value 长度的低位和高位,数据图大致如下:
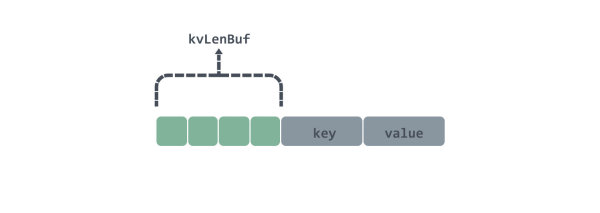
下面举个例子来看看是是如何利用 chunks 这个二维数组来实现环形链表的。
我们在 bucket 的 Init 方法中会根据传入 maxBytes 桶字节数来设置 chunks 的长度大小,由于每个 chunk 大小都是 64 * 1024bytes,那么我们设置 3 * 64 * 1024bytes 大小的桶,那么 chunks 数组长度就为 3。
如果当前算出 chunkIdx 在 chunks 数组为 1 的位置,并且在 chunks[1] 的位置中,还剩下 6bytes 未被使用,那么有如下几种情况:
现在假设放入的键值长度都是 1byte,那么在 chunks[1] 的位置中剩下的 6bytes 刚好可以放下;

现在假设放入的键值长度超过了 1byte,那么在 chunks[1] 的位置中剩下的位置就放不下,只能放入到 chunks[2] 的位置中。
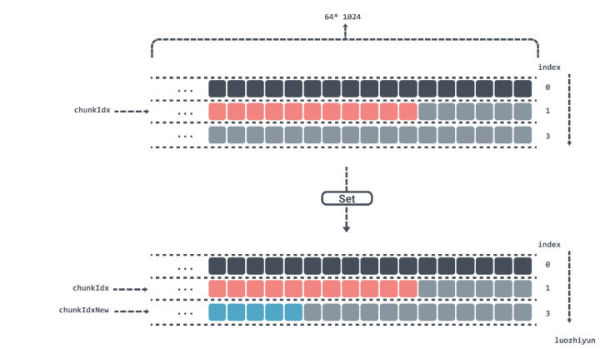
如果当前算出 chunkIdx 在 chunks 数组为 2 的位置,并且现在 Set 一个键值,经过计算 chunkIdxNew 为 3,已经超过了 chunks 数组长度,那么会将索引重置,重新将数据从 chunks[0] 开始放置,并将 gen 加一,表示已经跑完一圈了。
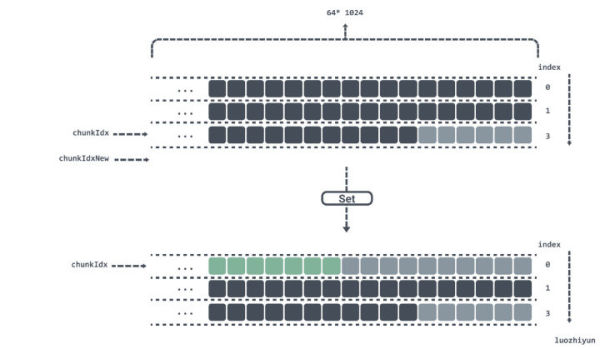
func (c *Cache) Get(dst, k []byte) []byte { h := xxhash.Sum64(k) idx := h % bucketsCount dst, _ = c.buckets[idx].Get(dst, k, h, true) return dst }这里和 Set 方法是一样的,首先是要找到对应的桶的位置,然后才去桶里面拿数据。需要注意的是,这里的 dst 可以从外部传入一个切片,以达到减少重复分配返回值。
func (b *bucket) Get(dst, k []byte, h uint64,returnDst bool) ([]byte, bool) { found := false b.mu.RLock() v := b.m[h] bGen := b.gen & ((1 << genSizeBits) - 1) if v > 0 { // 高于bucketSizeBits位置表示gen gen := v >> bucketSizeBits // 低于bucketSizeBits位置表示idx idx := v & ((1 << bucketSizeBits) - 1) // 这里说明chunks还没被写满 if gen == bGen && idx < b.idx || // 这里说明chunks已被写满,并且当前数据没有被覆盖 gen+1 == bGen && idx >= b.idx || // 这里是边界条件gen已是最大,并且chunks已被写满bGen从1开始,,并且当前数据没有被覆盖 gen == maxGen && bGen == 1 && idx >= b.idx { chunkIdx := idx / chunkSize // chunk 索引位置不能超过 chunks 数组长度 if chunkIdx >= uint64(len(b.chunks)) { goto end } // 找到数据所在的 chunk chunk := b.chunks[chunkIdx] // 通过取模找到该key 对应的数据在 chunk 中的位置 idx %= chunkSize if idx+4 >= chunkSize { goto end } // 前 4bytes 是数据头 kvLenBuf := chunk[idx : idx+4] // 通过数据头算出键值的长度 keyLen := (uint64(kvLenBuf[0]) << 8) | uint64(kvLenBuf[1]) valLen := (uint64(kvLenBuf[2]) << 8) | uint64(kvLenBuf[3]) idx += 4 if idx+keyLen+valLen >= chunkSize { goto end } // 如果键值是一致的,表示找到该数据 if string(k) == string(chunk[idx:idx+keyLen]) { idx += keyLen // 返回该键对应的值 if returnDst { dst = append(dst, chunk[idx:idx+valLen]...) } found = true } } } end: b.mu.RUnlock() return dst, found }Get 方法主要是考虑环形链表的边界问题。我们在 Set 方法中会将每一个 key 对应的 gen 和 idx 索引存放到 m 字典中,所以我们通过 hash 获取 m 字典的值之后通过位运算就可以获取到 gen 和 idx 索引。
找到 gen 和 idx 索引之后就是边界条件的判断了,用一个 if 条件来进行判断:
gen == bGen && idx < b.idx这里是判断如果是在环形链表的同一次循环中,那么 key 对应的索引应该小于当前桶的索引;
gen+1 == bGen && idx >= b.idx
这里表示当前桶已经进入到下一个循环中,所以需要判断 key 对应的索引是不是大于当前索引,以表示当前 key 对应的值没有被覆盖;
gen == maxGen && bGen == 1 && idx >= b.idx因为 gen 和 idx 索引要塞到 uint64 类型的字段中,所以留给 gen 的最大值只有 maxGen = 1<< 24 -1,超过了 maxGen 会让 gen 从 1 开始。所以这里如果 key 对应 gen 等于 maxGen ,那么当前的 bGen 应该等于 1,并且 key 对应的索引还应该大于当前 idx,这样才这个键值对才不会被覆盖。
判断完边界条件之后就会找到对应的 chunk ,然后取模后找到数据位置,通过偏移量找到并取出值。

下面我上一下过后的 Benchmark:
代码位置: https://github.com/devYun/mycache/blob/main/cache_timing_test.go
GOMAXPROCS=4 go test -bench='Set|Get' -benchtime=10s goos: linux goarch: amd64 pkg: gotest // GoCache BenchmarkGoCacheSet-4 836 14595822 ns/op 4.49 MB/s 2167340 B/op 65576 allocs/op BenchmarkGoCacheGet-4 3093 3619730 ns/op 18.11 MB/s 5194 B/op 23 allocs/op BenchmarkGoCacheSetGet-4 236 54379268 ns/op 2.41 MB/s 2345868 B/op 65679 allocs/op // BigCache BenchmarkBigCacheSet-4 1393 12763995 ns/op 5.13 MB/s 6691115 B/op 8 allocs/op BenchmarkBigCacheGet-4 2526 4342561 ns/op 15.09 MB/s 650870 B/op 131074 allocs/op BenchmarkBigCacheSetGet-4 1063 11180201 ns/op 11.72 MB/s 4778699 B/op 131081 allocs/op // standard map BenchmarkStdMapSet-4 1484 7299296 ns/op 8.98 MB/s 270603 B/op 65537 allocs/op BenchmarkStdMapGet-4 4278 2480523 ns/op 26.42 MB/s 2998 B/op 15 allocs/op BenchmarkStdMapSetGet-4 343 39367319 ns/op 3.33 MB/s 298764 B/op 65543 allocs/op // sync.map BenchmarkSyncMapSet-4 756 15951363 ns/op 4.11 MB/s 3420214 B/op 262320 allocs/op BenchmarkSyncMapGet-4 11826 1010283 ns/op 64.87 MB/s 1075 B/op 33 allocs/op BenchmarkSyncMapSetGet-4 1910 5507036 ns/op 23.80 MB/s 3412764 B/op 262213 allocs/op PASS ok gotest 215.182s上面的测试是 GoCache、BigCache、Map、sync.Map 的情况。下面是本篇文章中所开发的缓存库的测试:
// myCachce BenchmarkCacheSet-4 4371 2723208 ns/op 24.07 MB/s 1306 B/op 2 allocs/op BenchmarkCacheGet-4 6003 1884611 ns/op 34.77 MB/s 951 B/op 1 allocs/op BenchmarkCacheSetGet-4 2044 6611759 ns/op 19.82 MB/s 2797 B/op 5 allocs/op
可以看到内存分配是几乎就不存在,操作速度在上面的库中也是佼佼者的存在。
在本文中根据其他缓存库,并分析了如果用 Map 作为缓存所存在的问题,然后引出存在这个问题的原因,并提出解决方案;在我们的缓存库中,第一是通过使用索引加内存块的方式来存放缓存数据,再来是通过 OS 系统调用来进行内存分配让我们的缓存数据块脱离了 GC 的控制,从而做到降低 GC 频率提高并发的目的。
其实不只是缓存库,在我们的项目中当遇到需要使用大量的带指针的数据结构并需要长时间保持引用的时候,也是需要注意这样做可能会引发 GC 问题,从而给系统带来隐患。
到此,相信大家对“怎么打造高性能的 Go 缓存库”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://www.tuicool.com/a/1/1?lang=1



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



