今天就跟大家聊聊有关Raft 中怎么利用共识算法选举领导者,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
Raft 是一种强领导者模型,即一切以领导者为准,实现一系列的共识和各个节点日志一致性的一种共识算法。
Raft 一共有三种成员身份,分别是:领导者(Leader)、跟随者(Follower)、候选人(Candidate)。
跟随者:在 Raft 中只有领导者才会与客户端交互,因此在不发生选举时,跟随者仅默默地处理来自领导者发送的消息,充当数据冗余的作用,当领导者心跳超时,跟随者就会主动推荐自己当选候选人。
候选人:成为候选人之后,就会向其他节点发送请求投票消息,以获取其他节点的投票,如果获得了大多数选票,则当选领导者。
领导者:数据一切以领导者为准,它也是与客户端交互的唯一角色,处理请求,管理日志的复制,同时还不断地发送心跳信息给跟随者,不断刷新跟随者节点的超时时间,以防跟随者发起新的选举。
下面我以一个刚初始化的 Raft 集群为例:
1、初始状态
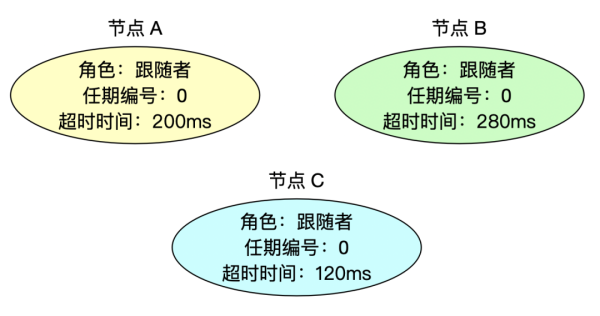
Raft 每个节点初始化后的心跳超时时间都是随机的,如上所示,节点 C 的超时时间最短(120ms),任期编号都为 0,角色都是跟随者。
2、请求投票
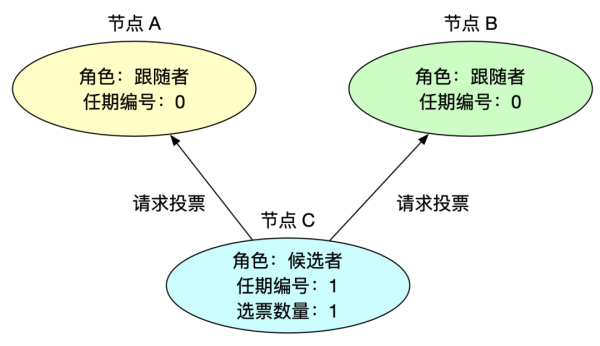
此时没有一个节点是领导者,节点等待心跳超时后,会推荐自己为候选人,向集群其他节点发起请求投票信息,此时任期编号 +1,自荐会获得自己的一票选票。
3、跟随者投票
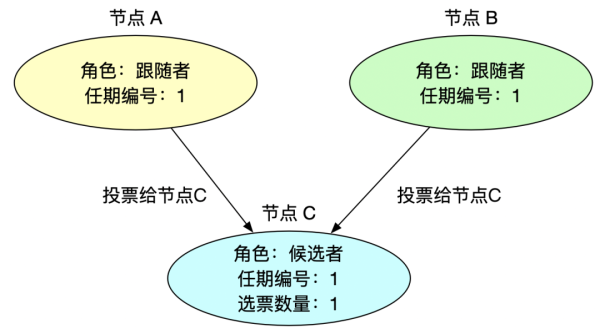
跟随者收到请求投票信息后,如果该候选人符合投票要求后,则将自己宝贵(因为每个任期内跟随者只能投给先来的候选人一票,后面来的候选人则不能在投票给它了)的一票投给该候选人,同时更新任期编号。
4、当选领导者
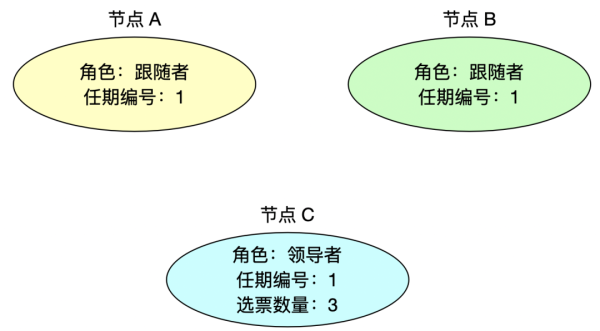
当节点 C 赢得大多数选票后,它会成为本次任期的领导者。
5、领导者与跟随者保持心跳
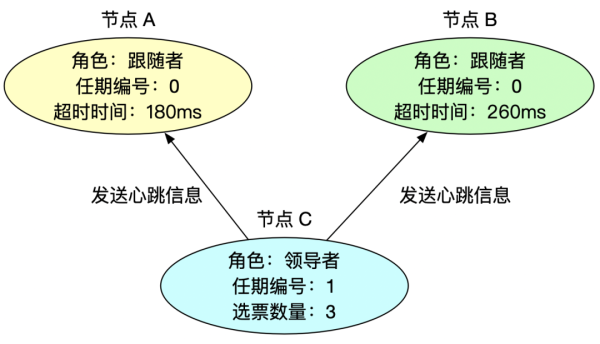
领导者周期性发送心跳消息给其他节点,告知自己是领导者,同时刷新跟随者的超时时间,防止跟随者发起新的领导者选举。
从以上的选举过程看,我们知道在 Raft 中的选举中是有任期机制的,顾名思义,每一任领导者,都有它专属的任期,当领导者更换后,任期也会增加,Raft 中的任期还要注意以下个细节:
如果某个节点,发现自己的任期编号比其他节点小,则会将自己的任期编号更新比自己更大的值;
从上面的选举过程看出,每次推荐自己成为候选人,都会得到自身的那一票;
如果候选人或者领导者发现自己的任期编号比其它节点好要小,则会立即更新自己为跟随者,这点很重要,按照我的理解,这个机制能够解决同一时间内有多个领导者的情况,比如领导者 A 挂了之后,集群其他节点会选举出一个新的领导者 B,在节点 B 恢复之后,会接收来自新领导者的心跳消息,此时节点 A 会立即恢复成跟随者状态;
如果某个节点接收到比自己任期号小的请求,则会拒绝这个请求。
看完上述内容,你们对Raft 中怎么利用共识算法选举领导者有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





