本篇内容主要讲解“python os.walk()方法的应用”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“python os.walk()方法的应用”吧!
os.walk方法是python中帮助我们高效管理文件、目录的工具,在深度学习中数据整理应用的很频繁,如数据集的名称格式化、将数据集的按一定比例划分训练集train_set、测试集test_set。
1.导入文件(使用os.walk方法前需要导入以下包)
import os import random # 后续用来将数据随机打乱和生成确定随机种子,保证每次生成的随机数据一样便于测试模型精准度
2.os.walk()参数解释
os.walk(top, topdown=True, οnerrοr=None, followlinks=False)(后两个参数我几乎没用过)
参数
--top 我们需要遍历的文件夹的地址(最好使用绝对地址,相对地址有时会出现未知错误) --topdown 该参数为True时,会优先遍历top目录,否则优先遍历top的子目录(默认值为 True) --onerror 需要一个 callable 对象,当walk需要异常时会调用 --followlinks 如果为真,则会遍历目录下的快捷方式(linux 下是 symbolic link)实际所指的目录(默认关闭)
os.walk 的返回值是一个生成器(generator),也就是说我们可以用循环去不遍历它,来获得其内容。每次遍历的对象都是返回的是一个三元组(root,dirs,files)
--root 指的是当前正在遍历的这个文件夹的本身的地址 --dirs 返回的是一个列表list,表中数据是该文件夹中所有的目录的名称(但不包括子目录名称) --files 返回的也是一个列表list , 表中数据是该文件夹中所有的文件名称(但不包括子目录名称)
3.用于测试文件夹组织结构
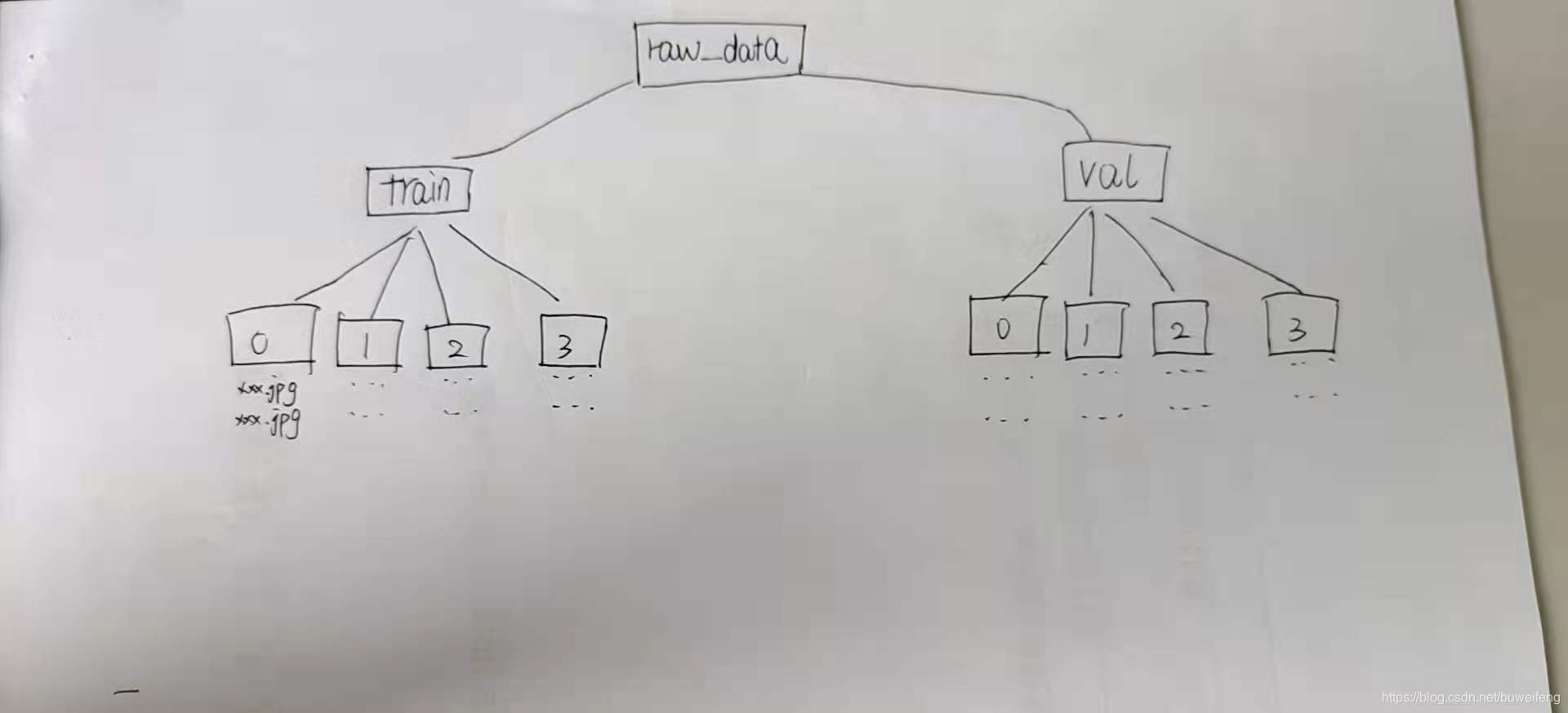 4.
4.
废话不说,看测试例子
4.1 os.walk(top, topdown=True)时打印返回的 root,dirs,files,顺便测试下topdown为真和假时的遍历顺序的区别。(这里就不展示运行后的结果了,代码拿走直接就可运行)
# topdown=True(该参数默认为真)
def _get_img_info():
#测试时将data_dir 换为自己的目标文件夹即可
data_dir = r'C:\Users\futiange\Desktop\Zero to Hero\expression_test\raw_data'
for root,dirs,files in os.walk(data_dir,topdown=True):
print('root={}'.format(root))
print('dirs={}'.format(dirs))
print('files={}'.format(files))
if __name__ == '__main__':
_get_img_info()
# topdown=False(该参数默认为假)
def _get_img_info():
data_dir = r'C:\Users\futiange\Desktop\Zero to Hero\expression_test\raw_data'
for root,dirs,files in os.walk(data_dir,topdown=False):
print('root={}'.format(root))
print('dirs={}'.format(dirs))
print('files={}'.format(files))
if __name__ == '__main__':
_get_img_info()4.2 使用案例
在深度学习中遍历数据集时,我们可以对数据集划分,这里按train :test = 9 : 1划分。
import os
import random # 后续用来将数据随机打乱和生成确定随机种子,保证每次生成的随机数据一样便于测试模型精准度
def _get_img_info(rng_seed,split_n,mode):
image_path_list = [] #用来存放图片的路径
label_path_list = [] #用来存放图片对应的标签
data_dir = r'C:\Users\futiange\Desktop\Zero to Hero\expression_test\raw_data'
for root,dirs,files in os.walk(data_dir):
for file in files:
path_file = os.path.join(root,file)
print(path_file)
if path_file.endswith(".jpg"): #判断该路径下文件是不是以.jpg结尾
#print(os.path.basename(root)) #输出图片路径
#print(os.path.basename(root)[0]) #输出该图片所在的文件夹的第一个字符,我这里文件夹的第一个字符就是图片的标签,测试时可以根据自己的文件夹名称更改
#print(int(os.path.basename(root)[0]))
image_path_list.append(path_file) #将图片路径加入列表
label_path_list.append(os.path.basename(root)[0]) #根据文件夹名称确定标签,并加入列表
data_info = [[n,l] for n,l in zip(image_path_list,label_path_list)] #将图片路径-标签 关联起来
random.seed(rng_seed) # 该方法中传入参数,确保每次生成的种子都是一样的
random.shuffle(data_info) #上一行代码生成的种子是确定的,保证了每次将列表元素打乱后的结果一样,便于测试模型性能
split_idx = int(len(data_info) * split_n) # data_len * 0.9 # split_n代表数据集划分的比例
if mode == 'train':
img_set = data_info[:split_idx]
elif mode == 'val':
img_set = data_info[split_idx:]
else:
raise Exception("mode 无法识别,仅支持(train,valid)")
return img_set #返回随机打乱后的数据集,后续在对其进行格式化即可将数据集加载进模型测试
if __name__ == '__main__':
_get_img_info(1,0.9,'train')到此,相信大家对“python os.walk()方法的应用”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





