本篇内容介绍了“pandas实现按行选择的方法”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
1.自定义行索引
2. 按普通索引选择数据
2.1 按普通索引选择单行数据
2.2 按行索引选择多行数据
3.按位置索引选择数据
3.2 按位置索引选择多行数据
4.选择连续多行数据
5.选择满足条件的行
5.1单个条件选择
5.2 多个条件选择
5.2.1 多个条件是且的关系
5.2.2 多个条件是或的关系
本文所用到的Excel表格内容如下:
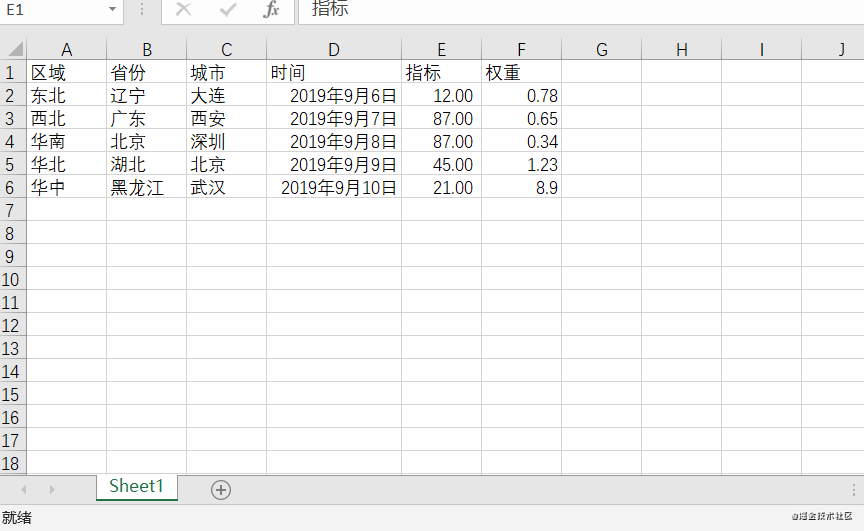
dataframe读取Excel表格时是由自定义行索引的。这里为了展示效果,先进行自定义行索引的操作
import pandas as pd
df = pd.read_excel(r'C:\Users\admin\Desktop\data_test.xlsx')
print('设置索引前:')
print(df)
print('设置索引后:')
df.index = ['一', '二', '三', '四', '五']
print(df)result:
设置索引前:
区域 省份 城市 时间 指标 地址 权重 字符
0 东北 辽宁 大连 2019-09-06 12 “123“ 0.78 u"123"
1 西北 广东 西安 2019-09-07 87 “124“ 0.65 u"124"
2 华南 北京 深圳 2019-09-08 87 “125“ 0.34 u"125"
3 华北 湖北 北京 2019-09-09 45 “126“ 1.23 u"126"
4 华中 黑龙江 武汉 2019-09-10 21 “127“ 8.90 u"127"
设置索引后:
区域 省份 城市 时间 指标 地址 权重 字符
一 东北 辽宁 大连 2019-09-06 12 “123“ 0.78 u"123"
二 西北 广东 西安 2019-09-07 87 “124“ 0.65 u"124"
三 华南 北京 深圳 2019-09-08 87 “125“ 0.34 u"125"
四 华北 湖北 北京 2019-09-09 45 “126“ 1.23 u"126"
五 华中 黑龙江 武汉 2019-09-10 21 “127“ 8.90 u"127"
这里说一下,行普通索引实际上就是行名。为了行文方便,后续一律称普通索引。
df = pd.read_excel(r'C:\Users\admin\Desktop\data_test.xlsx')
df.index = ['一', '二', '三', '四', '五']
print(df.loc['一'])result:
区域 东北
省份 辽宁
城市 大连
时间 2019-09-06 00:00:00
指标 12
地址 “123“
权重 0.78
字符 u"123"
Name: 一, dtype: object
df = pd.read_excel(r'C:\Users\admin\Desktop\data_test.xlsx')
df.index = ['一', '二', '三', '四', '五']
print(df.loc[['一', '三', '四']])result:
区域 省份 城市 时间 指标 地址 权重 字符
一 东北 辽宁 大连 2019-09-06 12 “123“ 0.78 u"123"
三 华南 北京 深圳 2019-09-08 87 “125“ 0.34 u"125"
四 华北 湖北 北京 2019-09-09 45 “126“ 1.23 u"126"
注:选择单列数据是参数为字符串类型,多列数据时参数为列表类型
3.1 按位置索引选择单行数据
df = pd.read_excel(r'C:\Users\admin\Desktop\data_test.xlsx')
df.index = ['一', '二', '三', '四', '五']
print(df.iloc[0])result:
区域 东北
省份 辽宁
城市 大连
时间 2019-09-06 00:00:00
指标 12
地址 “123“
权重 0.78
字符 u"123"
Name: 一, dtype: object
df = pd.read_excel(r'C:\Users\admin\Desktop\data_test.xlsx')
df.index = ['一', '二', '三', '四', '五']
print(df.iloc[[0, 1]])result:
区域 省份 城市 时间 指标 地址 权重 字符
一 东北 辽宁 大连 2019-09-06 12 “123“ 0.78 u"123"
二 西北 广东 西安 2019-09-07 87 “124“ 0.65 u"124"
df = pd.read_excel(r'C:\Users\admin\Desktop\data_test.xlsx')
df.index = ['一', '二', '三', '四', '五']
print(df.iloc[0:2])result:
区域 省份 城市 时间 指标 地址 权重 字符
一 东北 辽宁 大连 2019-09-06 12 “123“ 0.78 u"123"
二 西北 广东 西安 2019-09-07 87 “124“ 0.65 u"124"
表示获取所有行第1列到第3列的数据。选择连续多列数据时语法类似于切片语法,所以也称之为切片索引。
df = pd.read_excel(r'C:\Users\admin\Desktop\data_test.xlsx')
print(df[df['指标'] < 50])result:
区域 省份 城市 时间 指标 权重
0 东北 辽宁 大连 2019-09-06 12 0.78
3 华北 湖北 北京 2019-09-09 45 1.23
4 华中 黑龙江 武汉 2019-09-10 21 8.90
df = pd.read_excel(r'C:\Users\admin\Desktop\data_test.xlsx')
print(df[(df['指标'] < 50) & (df['权重'] < 1)])result:
区域 省份 城市 时间 指标 权重
0 东北 辽宁 大连 2019-09-06 12 0.78
df = pd.read_excel(r'C:\Users\admin\Desktop\data_test.xlsx')
print(df[(df['指标'] < 50) | (df['权重'] < 1)])result:
区域 省份 城市 时间 指标 权重
0 东北 辽宁 大连 2019-09-06 12 0.78
1 西北 广东 西安 2019-09-07 87 0.65
2 华南 北京 深圳 2019-09-08 87 0.34
3 华北 湖北 北京 2019-09-09 45 1.23
4 华中 黑龙江 武汉 2019-09-10 21 8.90
“pandas实现按行选择的方法”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



