本篇内容介绍了“零拷贝的原理以及java实现方式”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
零拷贝
传统I/O操作存在的性能问题
零拷贝技术原理
虚拟内存
mmap/write 方式
sendfile 方式
带有 scatter/gather 的 sendfile方式
splice 方式
总结
零拷贝(Zero-Copy)是一种 I/O 操作优化技术,可以快速高效地将数据从文件系统移动到网络接口,而不需要将其从内核空间复制到用户空间。其在 FTP 或者 HTTP 等协议中可以显著地提升性能。但是需要注意的是,并不是所有的操作系统都支持这一特性,目前只有在使用 NIO 和 Epoll 传输时才可使用该特性。
需要注意,它不能用于实现了数据加密或者压缩的文件系统上,只有传输文件的原始内容。这类原始内容也包括加密了的文件内容。
如果服务端要提供文件传输的功能,我们能想到的最简单的方式是:将磁盘上的文件读取出来,然后通过网络协议发送给客户端。
传统 I/O 的工作方式是,数据读取和写入是从用户空间到内核空间来回复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。
代码通常如下,一般会需要两个系统调用:
read(file, tmp_buf, len);
write(socket, tmp_buf, len);代码很简单,虽然就两行代码,但是这里面发生了不少的事情。
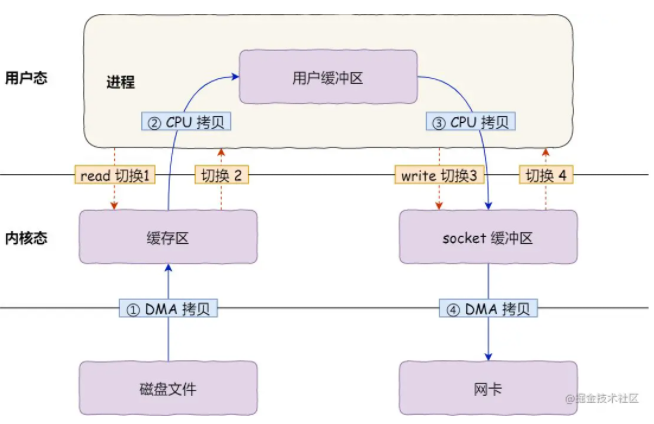
首先,期间共发生了 4 次用户态与内核态的上下文切换,因为发生了两次系统调用,一次是 read() ,一次是 write(),每次系统调用都得先从用户态切换到内核态,等内核完成任务后,再从内核态切换回用户态。
上下文切换到成本并不小,一次切换需要耗时几十纳秒到几微秒,虽然时间看上去很短,但是在高并发的场景下,这类时间容易被累积和放大,从而影响系统的性能。
其次,还发生了 4 次数据拷贝,其中两次是 DMA 的拷贝,另外两次则是通过 CPU 拷贝的,下面说一下这个过程:
第一次拷贝,把磁盘上的数据拷贝到操作系统内核的缓冲区里,这个拷贝的过程是通过 DMA 搬运的。
第二次拷贝,把内核缓冲区的数据拷贝到用户的缓冲区里,于是我们应用程序就可以使用这部分数据了,这个拷贝到过程是由 CPU 完成的。
第三次拷贝,把刚才拷贝到用户的缓冲区里的数据,再拷贝到内核的 socket 的缓冲区里,这个过程依然还是由 CPU 搬运的。
第四次拷贝,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程又是由 DMA 搬运的。
这种简单又传统的文件传输方式,存在冗余的上文切换和数据拷贝,在高并发系统里是非常糟糕的,多了很多不必要的开销,会严重影响系统性能。
所以,要想提高文件传输的性能,就需要减少「用户态与内核态的上下文切换」和「内存拷贝」的次数。
零拷贝主要是用来解决操作系统在处理 I/O 操作时,频繁复制数据的问题。关于零拷贝主要技术有 mmap+write、sendfile和splice等几种方式。
在了解零拷贝技术之前,先了解虚拟内存的概念。
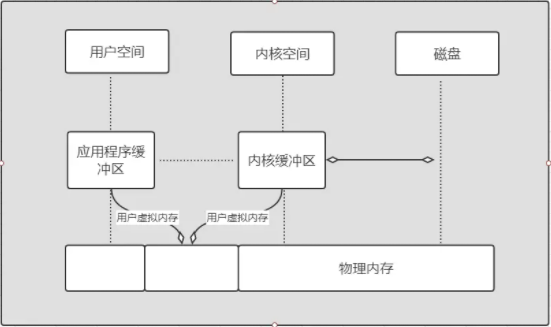
所有现代操作系统都使用虚拟内存,使用虚拟地址取代物理地址,主要有以下几点好处:
多个虚拟内存可以指向同一个物理地址。
虚拟内存空间可以远远大于物理内存空间。
利用上述的第一条特性可以优化,可以把内核空间和用户空间的虚拟地址映射到同一个物理地址,这样在 I/O 操作时就不需要来回复制了。
如下图展示了虚拟内存的原理。
使用mmap/write方式替换原来的传统I/O方式,就是利用了虚拟内存的特性。下图展示了mmap/write原理:
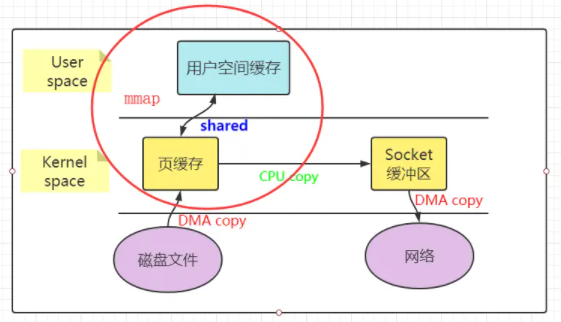
整个流程的核心区别就是,把数据读取到内核缓冲区后,应用程序进行写入操作时,直接把内核的Read Buffer的数据复制到Socket Buffer以便写入,这次内核之间的复制也是需要CPU的参与的。
上述流程就是少了一个 CPU COPY,提升了 I/O 的速度。不过发现上下文的切换还是4次并没有减少,这是因为还是要应用程序发起write操作。
那能不能减少上下文切换呢?这就需要sendfile方式来进一步优化了。
从 Linux 2.1 版本开始,Linux 引入了 sendfile来简化操作。sendfile方式可以替换上面的mmap/write方式来进一步优化。
sendfile将以下操作:
mmap();
write();替换为:
sendfile();这样就减少了上下文切换,因为少了一个应用程序发起write操作,直接发起sendfile操作。
下图展示了sendfile原理:
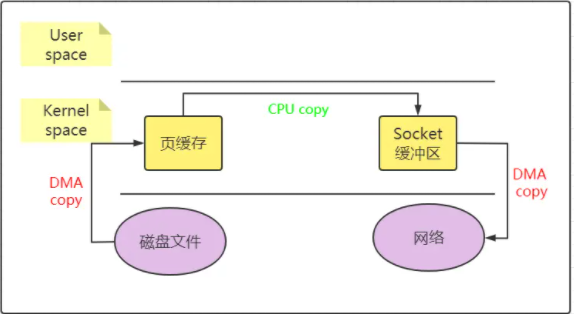
sendfile方式只有三次数据复制(其中只有一次 CPU COPY)以及2次上下文切换。
那能不能把 CPU COPY 减少到没有呢?这样需要带有 scatter/gather的sendfile方式了。
Linux 2.4 内核进行了优化,提供了带有 scatter/gather 的 sendfile 操作,这个操作可以把最后一次 CPU COPY 去除。其原理就是在内核空间 Read BUffer 和 Socket Buffer 不做数据复制,而是将 Read Buffer 的内存地址、偏移量记录到相应的 Socket Buffer 中,这样就不需要复制。其本质和虚拟内存的解决方法思路一致,就是内存地址的记录。
下图展示了scatter/gather 的 sendfile 的原理:
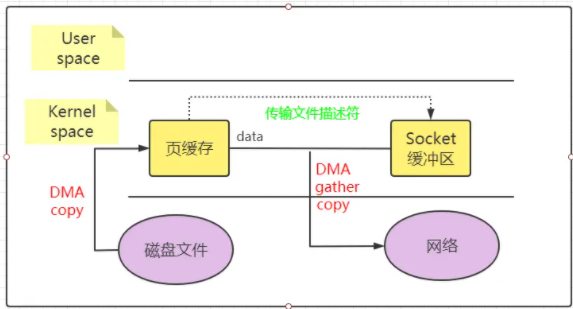
scatter/gather 的 sendfile 只有两次数据复制(都是 DMA COPY)及 2 次上下文切换。CUP COPY 已经完全没有。不过这一种收集复制功能是需要硬件及驱动程序支持的。
splice 调用和sendfile 非常相似,用户应用程序必须拥有两个已经打开的文件描述符,一个表示输入设备,一个表示输出设备。与sendfile不同的是,splice允许任意两个文件互相连接,而并不只是文件与socket进行数据传输。对于从一个文件描述符发送数据到socket这种特例来说,一直都是使用sendfile系统调用,而splice一直以来就只是一种机制,它并不仅限于sendfile的功能。也就是说 sendfile 是 splice 的一个子集。
在 Linux 2.6.17 版本引入了 splice,而在 Linux 2.6.23 版本中, sendfile 机制的实现已经没有了,但是其 API 及相应的功能还在,只不过 API 及相应的功能是利用了 splice 机制来实现的。
和 sendfile 不同的是,splice 不需要硬件支持。
无论是传统的 I/O 方式,还是引入了零拷贝之后,2 次 DMA copy是都少不了的。因为两次 DMA 都是依赖硬件完成的。所以,所谓的零拷贝,都是为了减少 CPU copy 及减少了上下文的切换。
下图展示了各种零拷贝技术的对比图:
| CPU拷贝 | DMA拷贝 | 系统调用 | 上下文切换 | |
|---|---|---|---|---|
| 传统方法 | 2 | 2 | read/write | 4 |
| 内存映射 | 1 | 2 | mmap/write | 4 |
| sendfile | 1 | 2 | sendfile | 2 |
| scatter/gather copy | 0 | 2 | sendfile | 2 |
| splice | 0 | 2 | splice | 0 |
“零拷贝的原理以及java实现方式”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



