一、概述
本次实验采用VMware虚拟机,linux版本为CentOS7;
因为实验所需的5台机器配置大多相同,所以采用配置其中一台,然后使用克隆功能复制另外4份再做具体修改;
其中有些步骤以前配置过,此处就说明一下不再做具体配置,具体配置可翻阅以前的博文。
二、实验环境
1.关闭selinux和firewall
2.hadoop-2.7.4.tar.gz;zookeeper-3.4.10.tar.gz;jdk-8u131-linux-x64.tar.gz
三、主机规划
| IP | Host | 进程 | |
| 192.168.100.11 | hadoop1 | NameNode ResourceManager DFSZKFailoverController | |
| 192.168.100.12 | hadoop2 | NameNode ResourceManager DFSZKFailoverController | |
| 192.168.100.13 | hadoop3 | DataNode NodeManager JournalNode QuorumPeerMain | |
| 192.168.100.14 | hadoop4 | DataNode NodeManager JournalNode QuorumPeerMain | |
| 192.168.100.15 | hadoop5 | DataNode NodeManager JournalNode QuorumPeerMain | |
四、环境准备
1.设置IP地址:192.168.100.11
2.设置主机名:hadoop1
3.设置IP和主机名的映射
[root@hadoop1 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.100.11 hadoop1 192.168.100.12 hadoop2 192.168.100.13 hadoop3 192.168.100.14 hadoop4 192.168.100.15 hadoop5
4.配置ssh分发脚本
5.解压jdk
[root@hadoop1 ~]# tar -zxf jdk-8u131-linux-x64.tar.gz [root@hadoop1 ~]# cp -r jdk1.8.0_131/ /usr/local/jdk
6.解压hadoop
[root@hadoop1 ~]# tar -zxf hadoop-2.7.4.tar.gz [root@hadoop1 ~]# cp -r hadoop-2.7.4 /usr/local/hadoop
7.解压zookeeper
[root@hadoop1 ~]# tar -zxf zookeeper-3.4.10.tar.gz [root@hadoop1 ~]# cp -r zookeeper-3.4.10 /usr/local/hadoop/zookeeper [root@hadoop1 ~]# cd /usr/local/hadoop/zookeeper/conf/ [root@hadoop1 conf]# cp zoo_sample.cfg zoo.cfg [root@hadoop1 conf]# vim zoo.cfg #修改dataDir dataDir=/usr/local/hadoop/zookeeper/data #添加下面三行 server.1=hadoop3:2888:3888 server.2=hadoop4:2888:3888 server.3=hadoop5:2888:3888 [root@hadoop1 conf]# cd .. [root@hadoop1 zookeeper]# mkdir data #此处还有操作,但是hadoop1上不部署zookeeper模块所以后面再修改
8.配置环境变量
[root@hadoop1 ~]# tail -4 /etc/profile export JAVA_HOME=/usr/local/jdk export HADOOP_HOME=/usr/local/hadoop export ZOOKEEPER_HOME=/usr/local/hadoop/zookeeper export PATH=.:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH [root@hadoop1 ~]# source /etc/profile
9.测试环境变量可用
[root@hadoop1 ~]# java -version java version "1.8.0_131" Java(TM) SE Runtime Environment (build 1.8.0_131-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode) [root@hadoop1 ~]# hadoop version Hadoop 2.7.4 Subversion Unknown -r Unknown Compiled by root on 2017-08-28T09:30Z Compiled with protoc 2.5.0 From source with checksum 50b0468318b4ce9bd24dc467b7ce1148 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-2.7.4.jar
五、配置hadoop
1.core-site.xml
<configuration> <!-- 指定hdfs的nameservice为master --> <property> <name>fs.defaultFS</name> <value>hdfs://master/</value> </property> <!-- 指定hadoop临时目录 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> </property> <!-- 指定zookeeper地址 --> <property> <name>ha.zookeeper.quorum</name> <value>hadoop3:2181,hadoop4:2181,hadoop5:2181</value> </property> </configuration>
2.hdfs-site.xml
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/usr/local/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/usr/local/hadoop/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <!--HDFS高可用配置 --> <!--指定hdfs的nameservice,需要和core-site.xml中的保持一致--> <property> <name>dfs.nameservices</name> <value>master</value> </property> <!--指定master的两个namenode的名称 --> <property> <name>dfs.ha.namenodes.master</name> <value>nn1,nn2</value> </property> <!-- nn1,nn2 rpc 通信地址 --> <property> <name>dfs.namenode.rpc-address.master.nn1</name> <value>hadoop1:9000</value> </property> <property> <name>dfs.namenode.rpc-address.master.nn2</name> <value>hadoop2:9000</value> </property> <!-- nn1.nn2 http 通信地址 --> <property> <name>dfs.namenode.http-address.master.nn1</name> <value>hadoop1:50070</value> </property> <property> <name>dfs.namenode.http-address.master.nn2</name> <value>hadoop2:50070</value> </property> <!--=========Namenode同步==========--> <!--保证数据恢复 --> <property> <name>dfs.journalnode.http-address</name> <value>0.0.0.0:8480</value> </property> <property> <name>dfs.journalnode.rpc-address</name> <value>0.0.0.0:8485</value> </property> <property> <!--指定NameNode的元数据在JournalNode上的存放位置 --> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop3:8485;hadoop4:8485;hadoop5:8485/master</value> </property> <property> <!--JournalNode存放数据地址 --> <name>dfs.journalnode.edits.dir</name> <value>/usr/local/hadoop/dfs/journal</value> </property> <property> <!--NameNode失败自动切换实现方式 --> <name>dfs.client.failover.proxy.provider.master</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!--=========Namenode fencing:======== --> <!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行 --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence shell(/bin/true)</value> </property> <!-- 使用sshfence隔离机制时需要ssh免登陆 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!-- 配置sshfence隔离机制超时时间 --> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> <!--开启基于Zookeeper及ZKFC进程的自动备援设置,监视进程是否死掉 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>hadoop3:2181,hadoop4:2181,hadoop5:2181</value> </property> <property> <!--指定ZooKeeper超时间隔,单位毫秒 --> <name>ha.zookeeper.session-timeout.ms</name> <value>2000</value> </property> </configuration>
3.yarn-site.xml
<configuration> <!--NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.connect.retry-interval.ms</name> <value>2000</value> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!-- 指定RM的cluster id --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yrc</value> </property> <!--指定两台RM主机名标识符--> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!--RM主机1--> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>hadoop1</value> </property> <!--RM主机2--> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>hadoop2</value> </property> <!--RM故障自动切换--> <property> <name>yarn.resourcemanager.ha.automatic-failover.enabled</name> <value>true</value> </property> <!--RM故障自动恢复 --> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!--RM状态信息存储方式,一种基于内存(MemStore),另一种基于ZK(ZKStore)--> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <!-- 指定zk集群地址 --> <property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop3:2181,hadoop4:2181,hadoop5:2181</value> </property> <!--向RM调度资源地址--> <property> <name>yarn.resourcemanager.scheduler.address.rm1</name> <value>hadoop1:8030</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm2</name> <value>hadoop2:8030</value> </property> <!--NodeManager通过该地址交换信息--> <property> <name>yarn.resourcemanager.resource-tracker.address.rm1</name> <value>hadoop1:8031</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm2</name> <value>hadoop2:8031</value> </property> <!--客户端通过该地址向RM提交对应用程序操作--> <property> <name>yarn.resourcemanager.address.rm1</name> <value>hadoop1:8032</value> </property> <property> <name>yarn.resourcemanager.address.rm2</name> <value>hadoop2:8032</value> </property> <!--管理员通过该地址向RM发送管理命令--> <property> <name>yarn.resourcemanager.admin.address.rm1</name> <value>hadoop1:8033</value> </property> <property> <name>yarn.resourcemanager.admin.address.rm2</name> <value>hadoop2:8033</value> </property> <!--RM HTTP访问地址,查看集群信息--> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>hadoop1:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>hadoop2:8088</value> </property> </configuration>
4.mapred-site.xml
<configuration> <!-- 指定mr框架为yarn方式 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 配置 MapReduce JobHistory Server地址 ,默认端口10020 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop1:10020</value> </property> <!-- 配置 MapReduce JobHistory Server HTTP地址, 默认端口19888 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop1:19888</value> </property> </configuration>
5.slaves
[root@hadoop1 hadoop]# cat slaves hadoop3 hadoop4 hadoop5
6.hadoop-env.sh
export JAVA_HOME=/usr/local/jdk #在后面添加
六、克隆虚拟机
1.使用hadoop1为模板克隆4台虚拟机,并将网卡的MAC地址重新生成
2.修改主机名为hadoop2-hadoop5
3.修改IP地址
4.配置所有机器之间的ssh免密登陆(ssh公钥分发)
七、配置zookeeper
[root@hadoop3 ~]# echo 1 > /usr/local/hadoop/zookeeper/data/myid #在hadoop3上 [root@hadoop4 ~]# echo 2 > /usr/local/hadoop/zookeeper/data/myid #在hadoop4上 [root@hadoop5 ~]# echo 3 > /usr/local/hadoop/zookeeper/data/myid #在hadoop5上
八、启动集群
1.在hadoop3-5上启动zookeeper
[root@hadoop3 ~]# zkServer.sh start ZooKeeper JMX enabled by default Using config: /usr/local/hadoop/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [root@hadoop3 ~]# zkServer.sh status ZooKeeper JMX enabled by default Using config: /usr/local/hadoop/zookeeper/bin/../conf/zoo.cfg Mode: follower [root@hadoop3 ~]# jps 2184 QuorumPeerMain 2237 Jps #hadoop4和hadoop5相同操作
2.在hadoop1上格式化 ZooKeeper 集群
[root@hadoop1 ~]# hdfs zkfc -formatZK
3.在hadoop3-5上启动journalnode
[root@hadoop3 ~]# hadoop-daemon.sh start journalnode starting journalnode, logging to /usr/local/hadoop/logs/hadoop-root-journalnode-hadoop3.out [root@hadoop3 ~]# jps 2244 JournalNode 2293 Jps 2188 QuorumPeerMain
4.在hadoop1上格式化namenode
[root@hadoop1 ~]# hdfs namenode -format ... 17/08/29 22:53:30 INFO util.ExitUtil: Exiting with status 0 17/08/29 22:53:30 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop1/192.168.100.11 ************************************************************/
5.在hadoop1上启动刚格式化的namenode
[root@hadoop1 ~]# hadoop-daemon.sh start namenode starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-hadoop1.out [root@hadoop1 ~]# jps 2422 Jps 2349 NameNode
6.在hadoop2上同步nn1(hadoop1)数据到nn2(hadoop2)
[root@hadoop2 ~]# hdfs namenode -bootstrapStandby ... 17/08/29 22:55:45 INFO namenode.TransferFsImage: Image Transfer timeout configured to 60000 milliseconds 17/08/29 22:55:45 INFO namenode.TransferFsImage: Transfer took 0.00s at 0.00 KB/s 17/08/29 22:55:45 INFO namenode.TransferFsImage: Downloaded file fsp_w_picpath.ckpt_0000000000000000000 size 321 bytes. 17/08/29 22:55:45 INFO util.ExitUtil: Exiting with status 0 17/08/29 22:55:45 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop2/192.168.100.12 ************************************************************/
7.启动hadoop2上的namenode
[root@hadoop2 ~]# hadoop-daemon.sh start namenode
8.启动集群中的所有服务
[root@hadoop1 ~]# start-all.sh
9.在hadoop2上启动yarn
[root@hadoop2 ~]# yarn-daemon.sh start resourcemanager
10.开启historyserver
[root@hadoop1 ~]# mr-jobhistory-daemon.sh start historyserver starting historyserver, logging to /usr/local/hadoop/logs/mapred-root-historyserver-hadoop1.out [root@hadoop1 ~]# jps 3026 DFSZKFailoverController 3110 ResourceManager 3894 JobHistoryServer 3927 Jps 2446 NameNode
11.查看进程
[root@hadoop3 ~]# jps 2480 DataNode 2722 Jps 2219 JournalNode 2174 QuorumPeerMain 2606 NodeManager [root@hadoop4 ~]# jps 2608 NodeManager 2178 QuorumPeerMain 2482 DataNode 2724 Jps 2229 JournalNode [root@hadoop5 ~]# jps 2178 QuorumPeerMain 2601 NodeManager 2475 DataNode 2717 Jps 2223 JournalNode
九、测试
1.连接
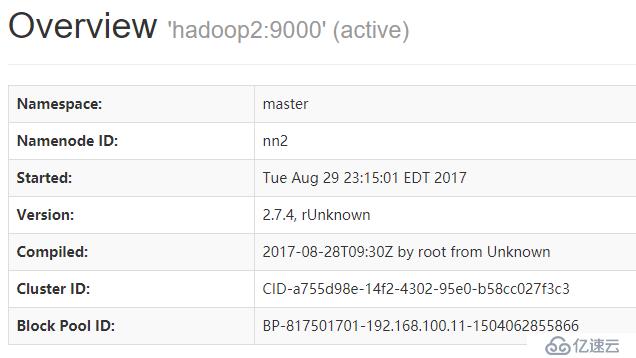
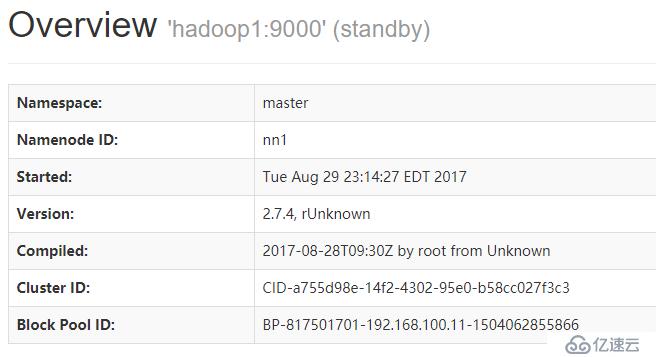
2.kill hadoop2上的namenode
[root@hadoop2 ~]# jps 2742 NameNode 3016 DFSZKFailoverController 4024 JobHistoryServer 4057 Jps 3133 ResourceManager [root@hadoop2 ~]# kill -9 2742 [root@hadoop2 ~]# jps 3016 DFSZKFailoverController 3133 ResourceManager 4205 Jps
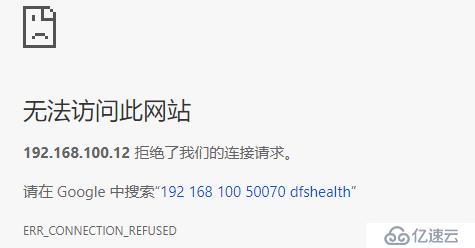
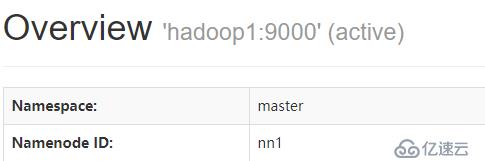
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





