小编给大家分享一下如何使用python写个颜值评分器,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
总体来说,我们需要做的是获取直播颜值区的主播小姐姐的正在直播的全部主播名称和封面图并保存下来,用百度AI提供的人脸识别接口,进行颜值评分排序,选出颜值最高的。
拆解需求,大致可以整理出核心功能如下:
打开直播颜值区模块对页面进行分析
发送网络请求,解析数据
保存数据
百度人脸识别接口
遍历主播照片,调用颜值检测接口对主播颜值进行打分
对评分进行排序
首先我们选择的是某牙直播,进入首页打开颜值区,按F12可以进入开发者模式。
import requests
# 1.找到数据所在url地址(系统分析网页性质)
url = "https://www.huya.com/g/2168"
headers = {
'User-Agent': 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
# 2. 发送网络请求
response = requests.get(url=url, headers=headers)
html_data = response.text
print(html_data)不难发现所有的小姐姐直播封面对应的都是在li标签里面。我们只要解析获取这些li标签数据就可以了。
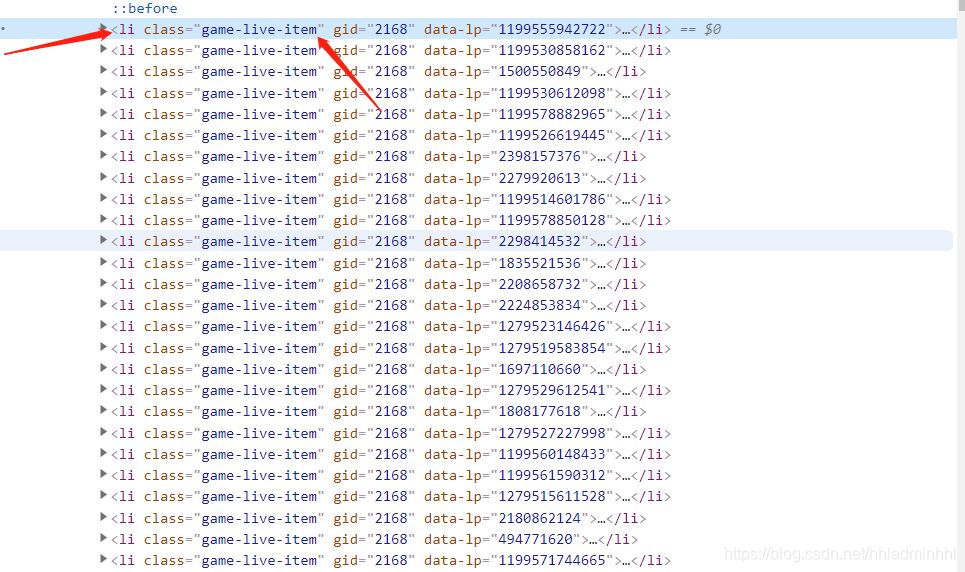
接着我们需要拿到直播小姐姐的封面图片,通过分析上面li标签里面的内容,可以发现下面有个a标签,里面的img标签中的data-original不就是我们要的小姐姐图片嘛!
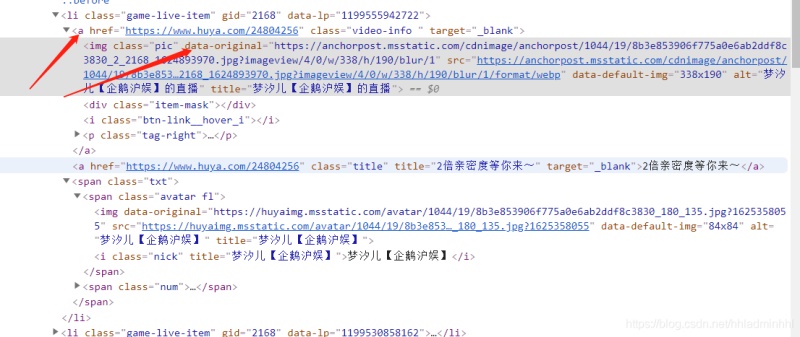
接下来我们想要获取主播小姐姐的名字怎么办呢?点开li标签继续分析,可以看到下面有个span标签,其中的i标签内容就是小姐姐直播的名字。
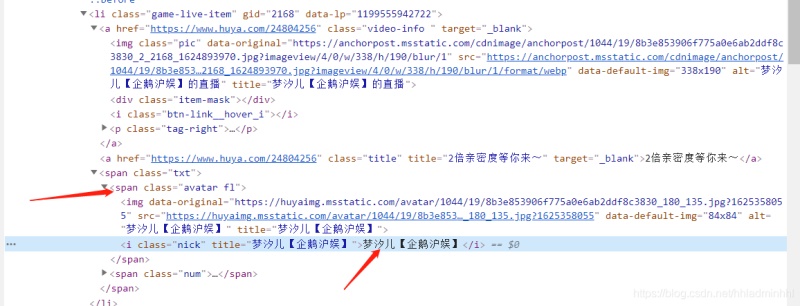
网页结构我们上面已经分析好了,那么我们就可以来动手爬取我们所需要的数据了。获取到所有的数据资源之后,把图片保存下来即可。文件的下载保存的方式比较多,我用的是通过 with open打开文件的方式 ,比较简单。
# 3. 数据解析
selector = parsel.Selector(html_data)
lis = selector.xpath('//li[@class="game-live-item"]') # 所有li标签
for li in lis:
img_name = li.xpath('.//span[@class="avatar fl"]/i/text()').get() # 主播名字
img_url = li.xpath('.//a/img/@data-original').get() # 主播图片地址
# print(img_name, img_url)
# 请求图片数据
img_data = requests.get(url=img_url).content # 图片数据
# 4. 数据保存
# 准备文件名
file_name = img_name + '.jpg'
with open('img\\' + file_name, mode='wb') as f:
f.write(img_data)
print('正在保存:', file_name)这样小姐姐的直播名称和照片都可以保存下来了,效果如下:

我们调用的是百度开放的人脸识别接口 – 百度AI开放平台链接。
这里面我们可以创建一个人脸识别应用,其中的API Key及Secret Key后面我们调用人脸识别检测接口时会用到。

接下来我们可以看看官方提供的API帮助文档,里面介绍的很详细。包括如何调用请求URL数据格式,向API服务地址使用POST发送请求,必须在URL中带上参数access_token,可通过后台的API Key和Secret Key生成。这里面的API Key和Secret Key就是我们上面提到的。
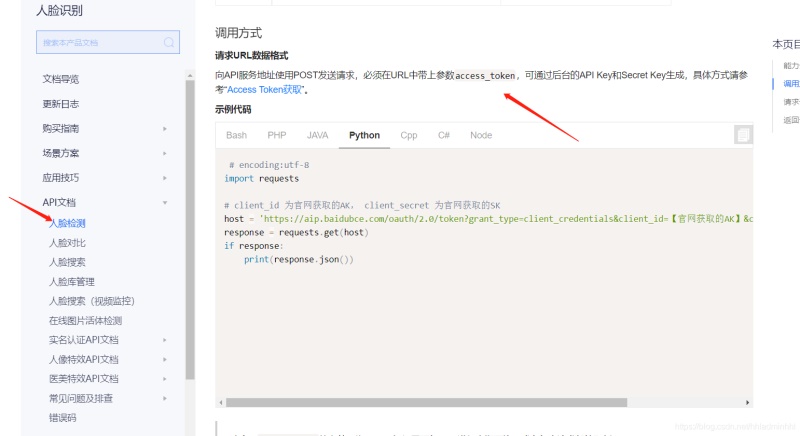
那我们要的打分颜值分数是哪个呢?提供返回结果参数,可以看到里面有个beauty就是我们要的颜值分数。
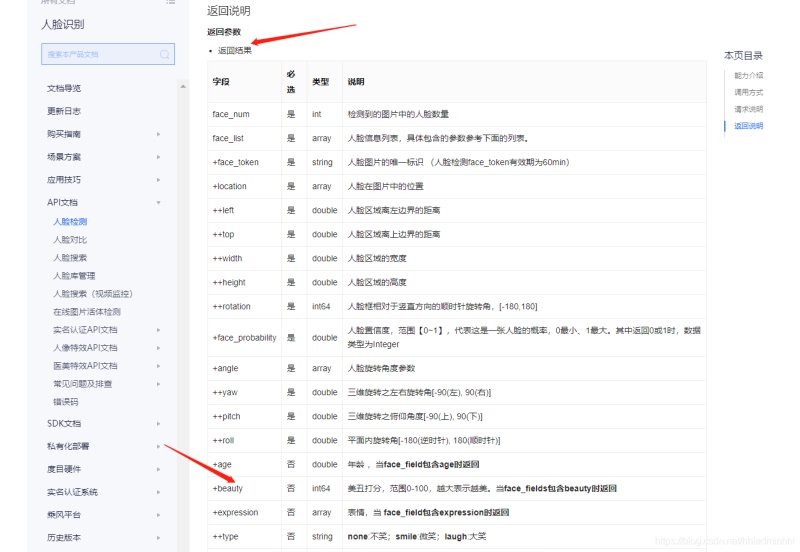
这样颜值检测的接口流程基本就已经清楚了,可以进行代码实现了。
其中获取token的时候,需要用到client_id 和 client_secret ,这两个就是上面创建人脸识别应用时提供的。
import base64
import requests
# import pprint
# 获取token
def get_token():
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【官网获取的AK】&client_secret=【官网获取的SK】'
response = requests.get(host)
if response:
# print(response.json())
return response.json()['access_token']
# 颜值检测接口
def face_input(file_path):
with open(file_path, 'rb') as file:
data = base64.b64encode(file.read())
img = data.decode()
request_url = "https://aip.baidubce.com/rest/2.0/face/v3/detect"
params = "{\"image\":\"%s\",\"image_type\":\"BASE64\",\"face_field\":\"beauty\"}" % img
access_token = get_token()
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/json'}
response = requests.post(request_url, data=params, headers=headers)
if response:
beauty = response.json()['result']['face_list'][0]['beauty']
# pprint.pprint(response.json())
return beauty可以看到result字段里面的beauty就是代表对小姐姐的颜值评分。效果如下:
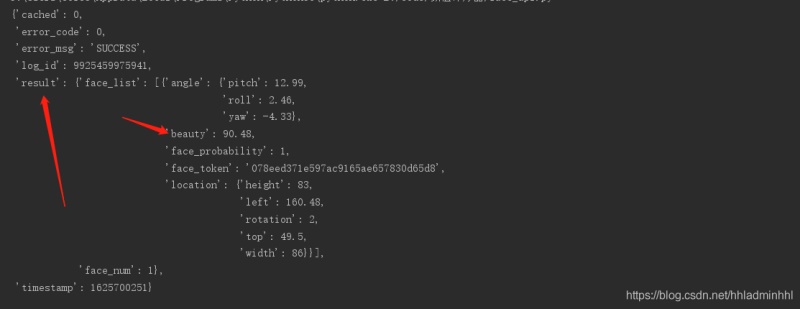
调用颜值检测接口已经写好了,下面我们要遍历之前保存的所有小姐姐直播照片,对每个进行颜值打分。
path = './img'
img_list = os.listdir(path)
# print(img_list)
score_dict ={}
for img in img_list:
try:
# 提取主播名字
name = img.split('.')[0]
# 构建图片路径
img_path = path + '//' + img
# 调用颜值检测接口
face_score = face_input(img_path)
# print(face_score)
score_dict[name] = face_score
except:
print(f'正在检测{name}| 检测失败')
else:
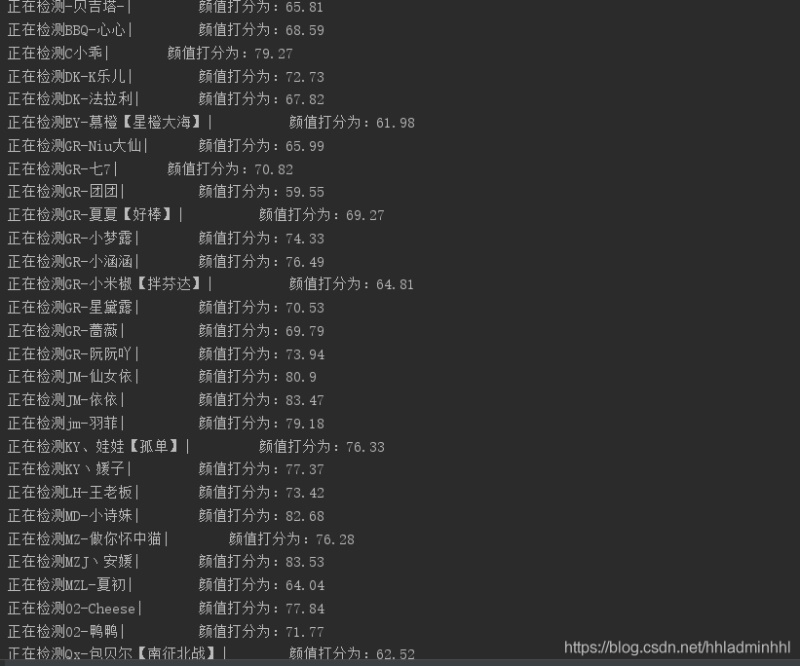
print(f'正在检测{name}| \t\t 颜值打分为:{face_score}')最后我们就只需要按照颜值分数进行降序排列,就可以选出颜值最高的小姐姐啦~
sorted_score = sorted(score_dict.items(), key=lambda x: x[1], reverse=True)
# print(sorted_score)
for i, j in enumerate(sorted_score):
print(f'小姐姐名字是:{sorted_score[i][0]} | 颜值名次是:第{i+1}名 | 颜值分数是:{sorted_score[i][1]}')通过颜值检测,这样就可以找到颜值最高的小姐姐了,颜值打分有90分以上。今天我们就到这里,明天继续努力!不说了,赶紧看直播去~

以上是“如何使用python写个颜值评分器”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





