这篇文章主要讲解了“Java阻塞队列SynchronousQueue实例分析”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Java阻塞队列SynchronousQueue实例分析”吧!
分析
其实SynchronousQueue 是一个特别有意思的阻塞队列,就我个人理解来说,它很重要的特点就是没有容量。
直接看一个例子:
package dongguabai.test.juc.test;
import java.util.concurrent.SynchronousQueue;
/**
* @author Dongguabai
* @description
* @date 2021-09-01 21:52
*/
public class TestSynchronousQueue {
public static void main(String[] args) {
SynchronousQueue synchronousQueue = new SynchronousQueue();
boolean add = synchronousQueue.add("1");
System.out.println(add);
}
}代码很简单,就是往 SynchronousQueue 里放了一个元素,程序却抛异常了:
Exception in thread "main" java.lang.IllegalStateException: Queue full
at java.util.AbstractQueue.add(AbstractQueue.java:98)
at dongguabai.test.juc.test.TestSynchronousQueue.main(TestSynchronousQueue.java:14)而异常原因是队列满了。刚刚使用的是 SynchronousQueue#add 方法,现在来看看 SynchronousQueue#put 方法:
public static void main(String[] args) throws InterruptedException {
SynchronousQueue synchronousQueue = new SynchronousQueue();
synchronousQueue.put("1");
System.out.println("----");
}看到 InterruptedException 其实就能猜出这个方法肯定会阻塞当前线程。
通过这两个例子,也就解释了 SynchronousQueue 队列是没有容量的,也就是说在往 SynchronousQueue 中添加元素之前,得先向 SynchronousQueue 中取出元素,这句话听着很别扭,那可以换个角度猜想其实现原理,调用取出方法的时候设置了一个“已经有线程在等待取出”的标识,线程等待,然后添加元素的时候,先看这个标识,如果有线程在等待取出,则添加成功,反之则抛出异常或者阻塞。
接下来从 SynchronousQueue#put 方法开始进行分析:
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
if (transferer.transfer(e, false, 0) == null) {
Thread.interrupted();
throw new InterruptedException();
}
}可以发现是调用的 Transferer#transfer 方法,这个 Transferer 是在构造 SynchronousQueue 的时候初始化的:
public SynchronousQueue(boolean fair) {
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}SynchronousQueue 有两种模式,公平与非公平,默认是非公平,非公平使用的就是 TransferStack,是基于单向链表做的:
static final class SNode {
volatile SNode next; // next node in stack
volatile SNode match; // the node matched to this
volatile Thread waiter; // to control park/unpark
Object item; // data; or null for REQUESTs
int mode;
...
}那么重点就是 SynchronousQueue.TransferStack#transfer 方法了,从方法名都可以看出这是用来做数据交换的,但是这个方法有好几十行,里面各种 Node 指针搞来搞去,这个地方我觉得没必要过于纠结细节,老规矩,抓大放小,而且队列这种,很方便进行 Debug 调试。
再理一下思路:
今天研究的是阻塞队列,关注阻塞的话,更应该关系的是 take 和 put 方法;
Transferer 是一个抽象类,只有一个 transfer 方法,即 take 和 put 共用,那就肯定是基于入参进行功能的区分;
take 和 put 方法底层都调用的 SynchronousQueue.TransferStack#transfer 方法;
将上面 SynchronousQueue#put 使用的例子修改一下,再加一个线程take:
package dongguabai.test.juc.test;
import java.util.Date;
import java.util.concurrent.SynchronousQueue;
import java.util.concurrent.TimeUnit;
/**
* @author Dongguabai
* @description
* @date 2021-09-01 21:52
*/
public class TestSynchronousQueue {
public static void main(String[] args) throws InterruptedException {
SynchronousQueue synchronousQueue = new SynchronousQueue();
new Thread(()->{
System.out.println(new Date().toLocaleString()+"::"+Thread.currentThread().getName()+"-put了数据:"+"1");
try {
synchronousQueue.put("1");
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
System.out.println("----");
new Thread(()->{
Object take = null;
try {
take = synchronousQueue.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(new Date().toLocaleString()+"::"+Thread.currentThread().getName()+"-take到了数据:"+take);
}).start();
TimeUnit.SECONDS.sleep(1);
System.out.println("结束...");
}
}整个程序结束,并且输出:
----
2021-9-2 0:58:55::Thread-0-put了数据:1
2021-9-2 0:58:55::Thread-1-take到了数据:1
结束...
也就是说当一个线程在 put 的时候,如果有线程 take ,那么 put 线程可以正常运行,不会被阻塞。
基于这个例子,再结合上文的猜想,也就是说核心点就是找到 put 的时候现在已经有线程在 take 的标识,或者 take 的时候已经有线程在 put,这个标识不一定是变量,结合 AQS 的原理来看,很可能是根据链表中的 Node 进行判断。
接下来看 SynchronousQueue.put 方法:
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
if (transferer.transfer(e, false, 0) == null) {
Thread.interrupted();
throw new InterruptedException();
}
}它底层也是调用的 SynchronousQueue.TransferStack#transfer 方法,但是传入参数是当前 put 的元素、false 和 0。再回过头看 SynchronousQueue.TransferStack#transfer 方法:
E transfer(E e, boolean timed, long nanos) {
SNode s = null; // constructed/reused as needed
//这里的参数e就是要put的元素,显然不为null,也就是说是DATA模式,根据注释,DATA模式就说明当前线程是producer
int mode = (e == null) ? REQUEST : DATA;
for (;;) {
SNode h = head;
if (h == null || h.mode == mode) { // empty or same-mode
if (timed && nanos <= 0) { // can't wait
if (h != null && h.isCancelled())
casHead(h, h.next); // pop cancelled node
else
return null;
} else if (casHead(h, s = snode(s, e, h, mode))) {
//因为第一次put那么h肯定为null,这里入参timed为false,所以会到这里,执行awaitFulfill方法,根据名称可以猜想出是一个阻塞方法
SNode m = awaitFulfill(s, timed, nanos);
if (m == s) { // wait was cancelled
clean(s);
return null;
}
....
}这里首先会构造一个 SNode,然后执行 casHead 函数,其实最终栈结构就是:
head->put_e
就是 head 会指向 put 的元素对应的 SNode。
然后会执行 awaitFulfill 方法:
SNode awaitFulfill(SNode s, boolean timed, long nanos) {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
int spins = (shouldSpin(s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
if (w.isInterrupted())
s.tryCancel();
SNode m = s.match;
if (m != null)
return m;
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel();
continue;
}
}
if (spins > 0)
spins = shouldSpin(s) ? (spins-1) : 0; //自旋机制
else if (s.waiter == null)
s.waiter = w; // establish waiter so can park next iter
else if (!timed)
LockSupport.park(this); //阻塞
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}最终还是会使用 LockSupport 进行阻塞,等待唤醒。
已经大致过了一遍流程了,细节方面就不再纠结了,那么假如再put 一个元素呢,其实结合源码已经可以分析出此时栈的结果为:
head-->put_e_1-->put_e
避免分析出错,写个 Debug 的代码验证一下:
package dongguabai.test.juc.test;
import java.util.concurrent.SynchronousQueue;
import java.util.concurrent.TimeUnit;
/**
* @author Dongguabai
* @description
* @date 2021-09-02 02:15
*/
public class DebugPut2E {
public static void main(String[] args) throws InterruptedException {
SynchronousQueue synchronousQueue = new SynchronousQueue();
new Thread(()-> {
try {
synchronousQueue.put("1");
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
TimeUnit.SECONDS.sleep(1);
new Thread(()-> {
try {
synchronousQueue.put("2");
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}在 SynchronousQueue.TransferStack#awaitFulfill 方法的 LockSupport.park(this); 处打上断点,运行上面的代码,再看看现在的 head:
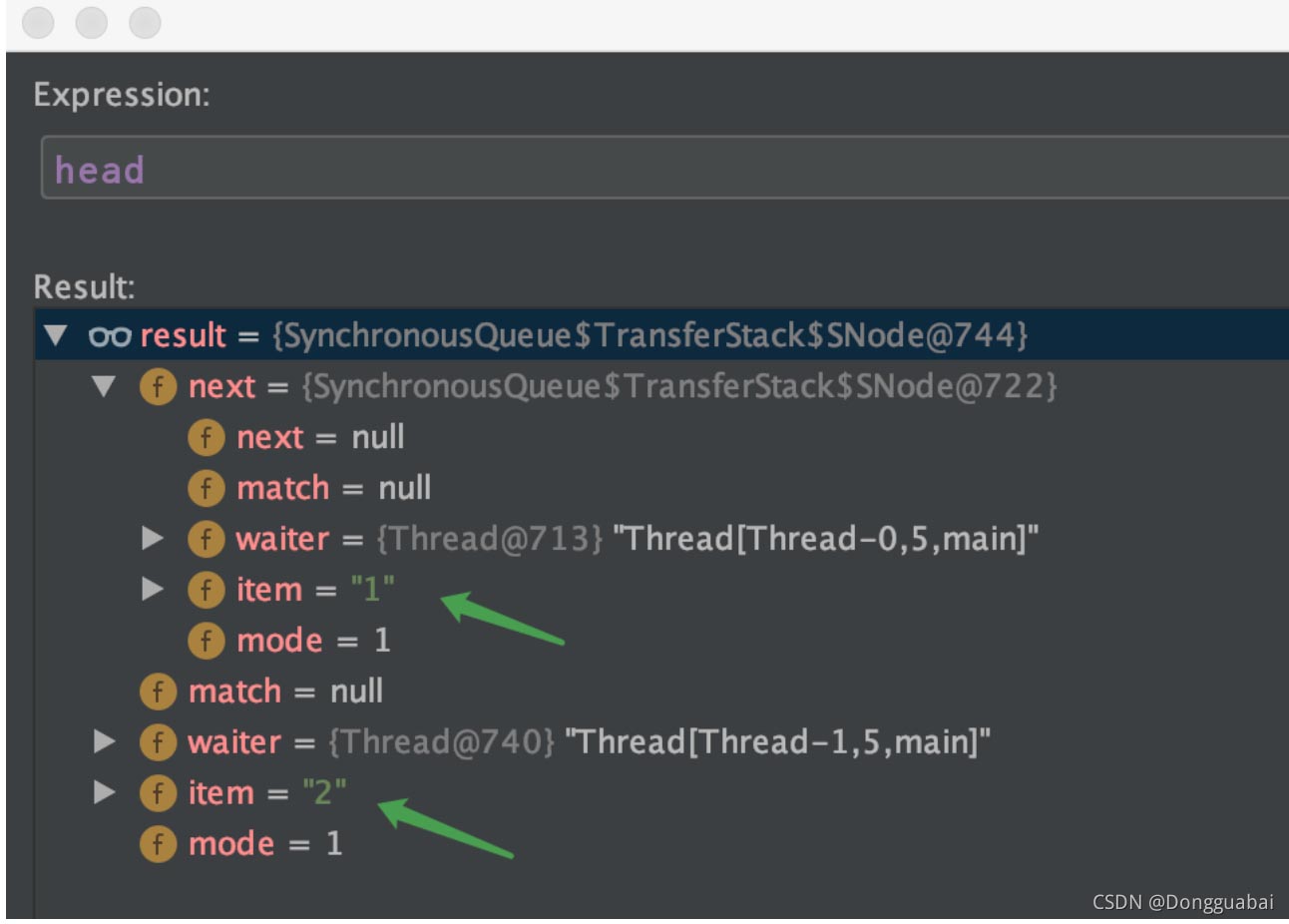
的确与分析的一致。
也就是先进后出。再看 take 方法:
public E take() throws InterruptedException {
E e = transferer.transfer(null, false, 0);
if (e != null)
return e;
Thread.interrupted();
throw new InterruptedException();
}调用的 SynchronousQueue.TransferStack#transfer 方法,但是传入参数是 null、false 和 0。
偷个懒就不分析源码了,直接 Debug 走一遍,代码如下:
package dongguabai.test.juc.test;
import java.util.concurrent.SynchronousQueue;
import java.util.concurrent.TimeUnit;
/**
* @author Dongguabai
* @description
* @date 2021-09-02 02:24
*/
public class DebugTake {
public static void main(String[] args) throws InterruptedException {
SynchronousQueue synchronousQueue = new SynchronousQueue();
new Thread(()-> {
try {
synchronousQueue.put("1");
} catch (InterruptedException e) {
e.printStackTrace();
}
},"Thread-put-1").start();
TimeUnit.SECONDS.sleep(1);
new Thread(()-> {
try {
synchronousQueue.put("2");
} catch (InterruptedException e) {
e.printStackTrace();
}
},"Thread-put-2").start();
TimeUnit.SECONDS.sleep(1);
new Thread(()->{
try {
Object take = synchronousQueue.take();
System.out.println("======take:"+take);
} catch (InterruptedException e) {
e.printStackTrace();
}
},"Thread-Take").start();
}
}在 SynchronousQueue#take 方法中打上断点,运行上面的代码:
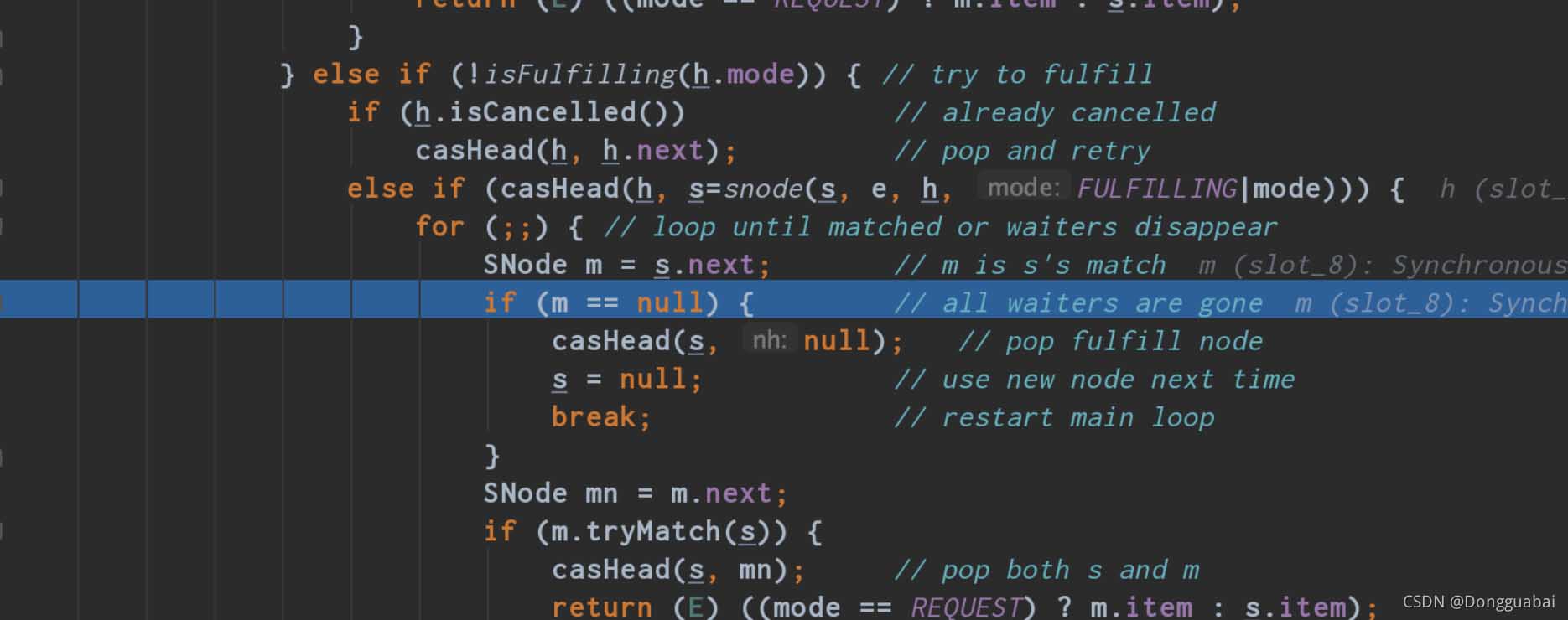
这里的 s 就是 head,m 就是栈顶的元素,也是最近一次 put 的元素。说白了 take 就是取的栈顶的元素,最后再匹配一下,符合条件就直接取出来。take 之后 head 为:
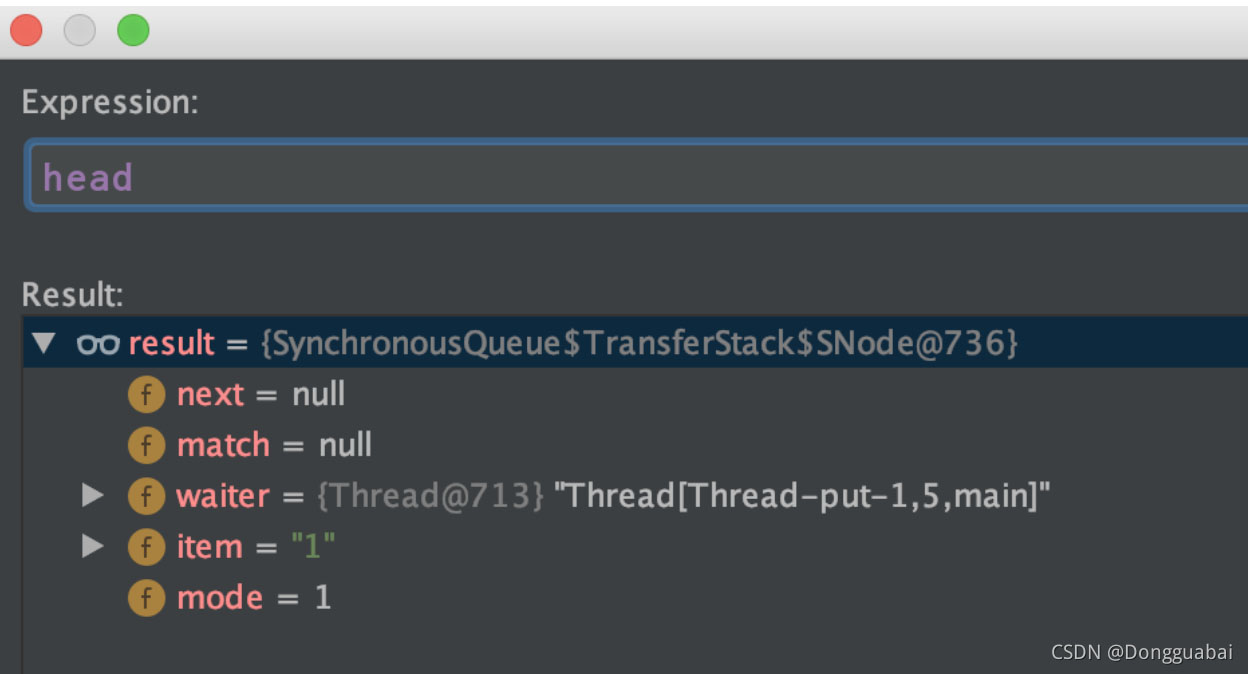
栈的结构为:
head-->put_e
最后再把整个流程梳理一遍:
执行 put 操作的时候,每次压入栈顶;take 的时候就取栈顶的元素,即先进后出;这也就实现了非公平;
至于公平模式,结合 TransferStack 的实现,可以猜测实现就是 put 的时候放入队列,take 的时候从队列头部开始取,先进先出。
那么这个队列设计的优势使用场景在哪里呢?个人感觉它的优势就是完全不会产生对队列中数据的争抢,因为说白了队列是空的,从某种程度上来说消费速率是很快的。
至于使用场景,我这边的确没有想到比较好的使用场景。结合组内同学的使用来看,他选择使用这个队列的原因是因为它不会在内存中生成任务队列,当服务宕机后不用担心内存中任务的丢失(非优雅停机的情况)。经过讨论后发现即使使用了 SynchronousQueue 也无法有效的避免任务丢失,但这的确是一个思路,没准以后在其他场景中用得上。
感谢各位的阅读,以上就是“Java阻塞队列SynchronousQueue实例分析”的内容了,经过本文的学习后,相信大家对Java阻塞队列SynchronousQueue实例分析这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



