(1)下载并安装VMware虚拟机软件。
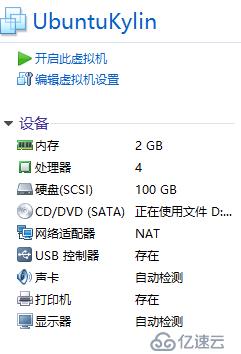
(2)创建虚拟机,实验环境虚拟机配置如下图所示。
(3)安装Ubuntu系统,安装结果如下图所示。

下载并安装JDK,安装结束后需对java环境进行配置,配置成功结果如下所示。

(1)创建Hadoop安装文件夹,并切到到此路径下。

(2)从 hadoop.apache.org 下载Hadoop 安装文件,并复制文件到安装Hadoop的文件夹中。下载地址如下图所示,本次试验选取较为稳定的最新版,即2.7.3版。

(3)解压Hadoop文件。
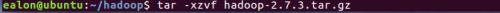
(4)修改配置文件
下面来写配置文件core-site.xml、hdfs-site.xml、hadoop-env.sh三个文件这三个文件都在~/hadoop/hadoop-2.7.3/etc/hadoop/下,在前两个文件中的和中写入如下内容。
第一个文件core-site.xml
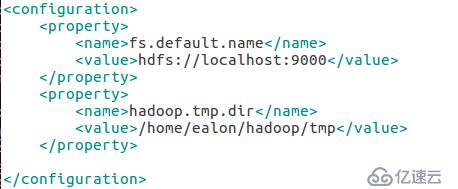
请注意/home/ealon/hadoop/tmp文件夹要被替换为计算机当前的用户目录中的tmp文件夹没有请创建。
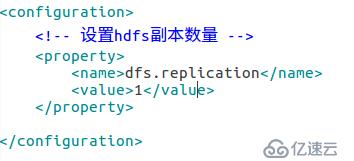
第二个文件hdfs-site.xml
第三个文件hadoop-env.sh中找到如下行然后写入内容。

接下来在系统环境变量中写入Hadoop的环境变量gedit /etc/environment
#在文件的结尾""之内加上
:/home/ealon/hadoop/hadoop-2.7.3/bin
:/home/ealon/hadoop/hadoop-2.7.3/sbin
(5)重启虚拟机
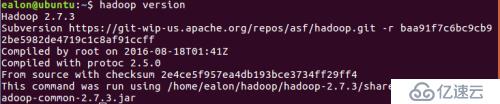
首先重启系统,待开机后,输入如下命令hadoop version,验证Hadoop环境是否安装成功。当看到屏幕上显示Hadoop的版本号即说明单机模式已经配置完成。如下图所示。
(6)启动HDFS
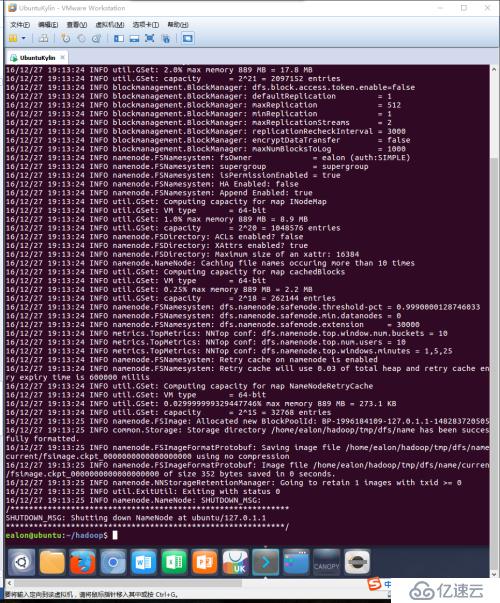
通过使用伪分布模式,启动HDFS服务。首先需对HDFS进行格式化处理。

显示如下内容即成功格式化。
(7)启动HDFS

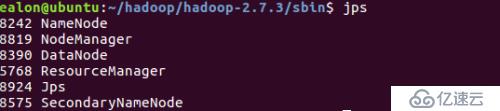
(8)查看进程
运行jps命令。如看到屏幕上显示如下内容即说明HDFS已经成功
(9)停止HDFS

通过以上操作,Hadoop环境就基本搭建完毕。
要在 Eclipse 上编译和运行 MapReduce 程序,需要安装 hadoop-eclipse-plugin,可下载 Github 上的 hadoop2x-eclipse-plugin。
下载后,将 release 中的hadoop-eclipse-kepler-plugin-2.6.0.jar复制到 Eclipse 安装目录的 plugins 文件夹中,运行 eclipse -clean 重启 Eclipse 即可。
unzip-qo ~/下载/hadoop2x-eclipse-plugin-master.zip -d ~/下载 # 解压到 ~/下载中
sudocp ~/下载/hadoop2x-eclipse-plugin-master/release/hadoop-eclipse-plugin-2.6.0.jar/usr/lib/eclipse/plugins/ # 复制到 eclipse 安装目录的 plugins 目录下
/usr/lib/eclipse/eclipse-clean # 添加插件后需要用这种方式使插件生效
在继续配置前请确保已经开启了 Hadoop。
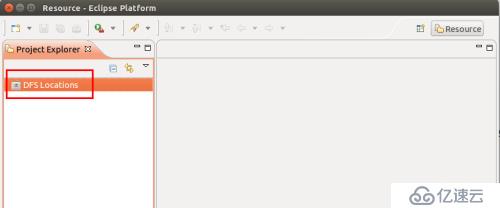
启动 Eclipse 后就可以在左侧的Project Explorer中看到 DFS Locations(若看到的是 welcome 界面,点击左上角的 x 关闭就可以看到了。
插件需要进一步的配置
第一步:选择 Window 菜单下的 Preference。
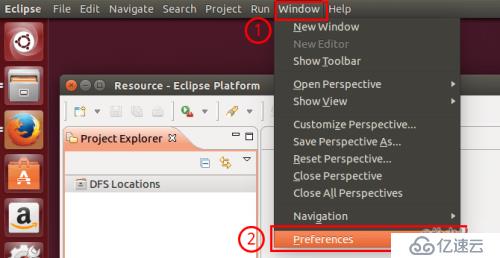
打开Preference打开Preference
此时会弹出一个窗体,窗体的左侧会多出 Hadoop Map/Reduce 选项,点击此选项,选择 Hadoop 的安装目录(如/usr/local/hadoop,Ubuntu不好选择目录,直接输入就行)。
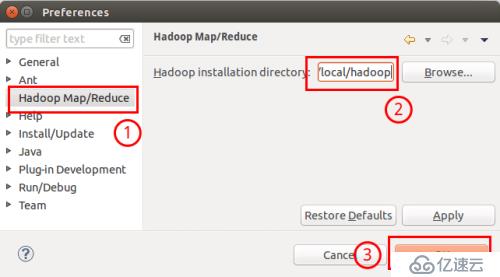
选择 Hadoop 的安装目录选择Hadoop 的安装目录
第二步:切换 Map/Reduce 开发视图,选择 Window 菜单下选择 Open Perspective ->Other(CentOS 是 Window -> Perspective-> Open Perspective -> Other),弹出一个窗体,从中选择 Map/Reduce 选项即可进行切换。
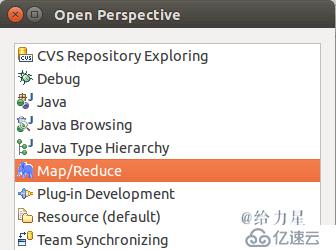
切换 Map/Reduce 开发视图切换Map/Reduce 开发视图
第三步:建立与 Hadoop 集群的连接,点击 Eclipse软件右下角的 Map/Reduce Locations 面板,在面板中单击右键,选择 New Hadoop Location。
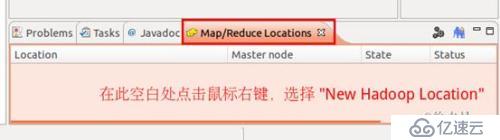
建立与 Hadoop 集群的连接建立与Hadoop 集群的连接
在弹出来的 General 选项面板中,General 的设置要与 Hadoop 的配置一致。一般两个 Host 值是一样的,如果是伪分布式,填写 localhost 即可,另外我使用的Hadoop伪分布式配置,设置 fs.defaultFS 为 hdfs://localhost:9000,则 DFS Master 的 Port 要改为 9000。Map/Reduce(V2) Master 的 Port 用默认的即可,Location Name 随意填写。
最后的设置如下图所示:
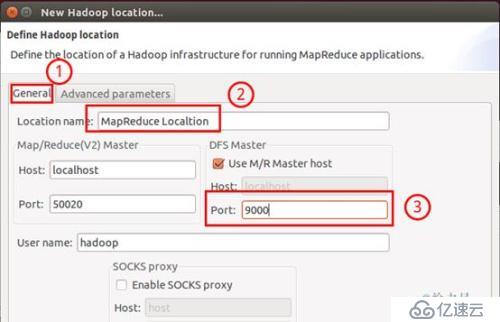
Hadoop Location 的设置HadoopLocation 的设置
Advancedparameters 选项面板是对 Hadoop 参数进行配置,实际上就是填写 Hadoop 的配置项(/usr/local/hadoop/etc/hadoop中的配置文件),如我配置了 hadoop.tmp.dir ,就要进行相应的修改。但修改起来会比较繁琐,我们可以通过复制配置文件的方式解决(下面会说到)。
总之,我们只要配置 General 就行了,点击 finish,Map/Reduce Location 就创建好了。
配置好后,点击左侧 Project Explorer 中的 MapReduce Location (点击三角形展开)就能直接查看 HDFS 中的文件列表了(HDFS 中要有文件,如下图是 WordCount 的输出结果),双击可以查看内容,右键点击可以上传、下载、删除 HDFS 中的文件,无需再通过繁琐的 hdfs dfs -ls 等命令进行操作了。
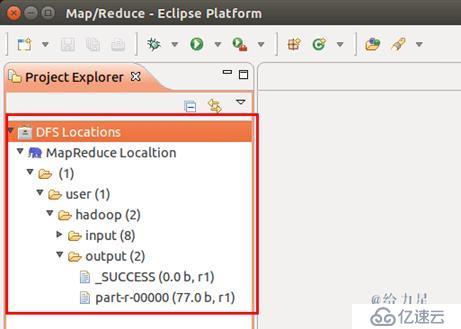
使用Eclipse查看HDFS中的文件内容
如果无法查看,可右键点击 Location 尝试 Reconnect 或重启 Eclipse。
点击 File 菜单,选择 New -> Project…:
创建Project
选择 Map/ReduceProject,点击 Next。
创建MapReduce项目
填写 Projectname 为 WordCount 即可,点击 Finish 就创建好了项目。
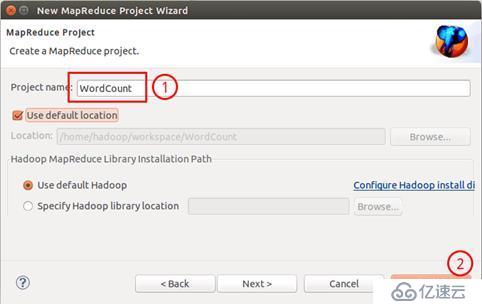
填写项目名
此时在左侧的Project Explorer 就能看到刚才建立的项目了。
项目创建完成
接着右键点击刚创建的WordCount 项目,选择 New -> Class
新建Class
需要填写两个地方:在 Package 处填写org.apache.hadoop.examples;在 Name 处填写 WordCount。
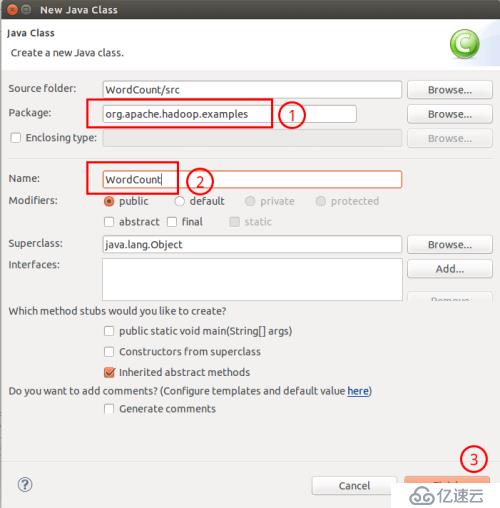
填写Class信息
创建 Class 完成后,在 Project 的 src 中就能看到 WordCount.java 这个文件。将如下 WordCount 的代码复制到该文件中。
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
importorg.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;
importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
importorg.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException,InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException,InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job,new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}在运行 MapReduce 程序前,还需要执行一项重要操作(也就是上面提到的通过复制配置文件解决参数设置问题):将/usr/local/hadoop/etc/hadoop 中将有修改过的配置文件(如伪分布式需要 core-site.xml 和 hdfs-site.xml),以及 log4j.properties 复制到 WordCount 项目下的 src 文件夹(~/workspace/WordCount/src)中:
cp/usr/local/hadoop/etc/hadoop/core-site.xml ~/workspace/WordCount/src
cp/usr/local/hadoop/etc/hadoop/hdfs-site.xml ~/workspace/WordCount/src
cp/usr/local/hadoop/etc/hadoop/log4j.properties ~/workspace/WordCount/src
没有复制这些文件的话程序将无法正确运行,本教程最后再解释为什么需要复制这些文件。
复制完成后,务必右键点击 WordCount 选择 refresh 进行刷新(不会自动刷新,需要手动刷新),可以看到文件结构如下所示:
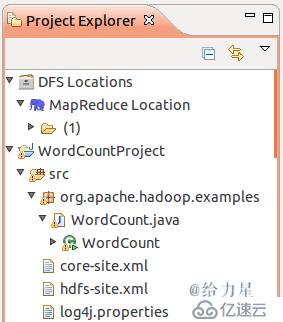
WordCount项目文件结构
点击工具栏中的 Run 图标,或者右键点击 Project Explorer 中的 WordCount.java,选择 Run As -> Run onHadoop,就可以运行 MapReduce 程序了。不过由于没有指定参数,运行时会提示 “Usage: wordcount “,需要通过Eclipse设定一下运行参数。
右键点击刚创建的 WordCount.java,选择 Run As -> RunConfigurations,在此处可以设置运行时的相关参数(如果 Java Application 下面没有 WordCount,那么需要先双击 Java Application)。切换到 “Arguments” 栏,在 Program arguments 处填写 “input output” 就可以了。
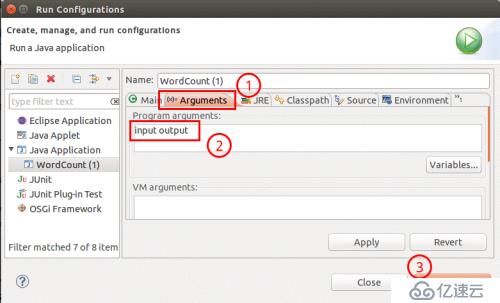
设置程序运行参数
或者也可以直接在代码中设置好输入参数。可将代码 main() 函数的 String[] otherArgs= new GenericOptionsParser(conf, args).getRemainingArgs(); 改为:
//String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
String[]otherArgs=new String[]{"input","output"}; /* 直接设置输入参数 */
设定参数后,再次运行程序,可以看到运行成功的提示,刷新 DFS Location 后也能看到输出的 output 文件夹。
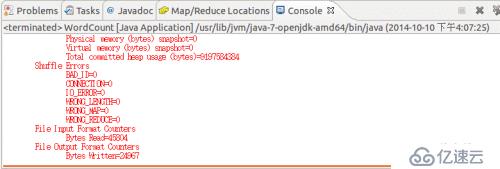
WordCount 运行结果
至此,你就可以使用 Eclipse 方便的进行 MapReduce程序的开发了。
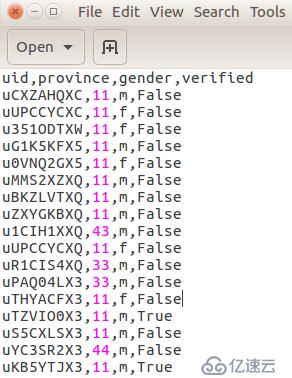
通过网络下载userdata.csv微博用户数据,共有14388385条用户数据,包含:用户id,所在省份,性别,是否认证信息。数据截图如下图所示。
项目代码结构如下图所示:
Maper函数:

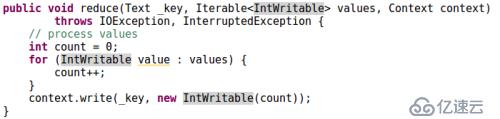
Reducer函数:
计算结果分布如下图所示:
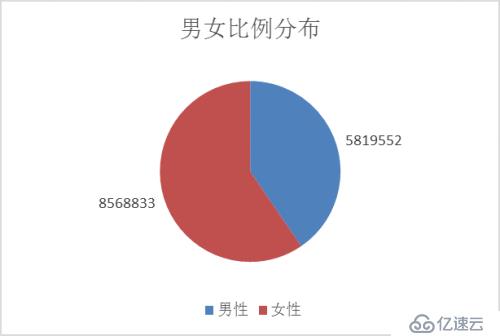
从图中可以观察到,微博用户中女性所占比例较大,多余男性用户。
该部分Maper函数、Reducer函数与性别统计算法相同,不再赘述,计算结果如下图所示:
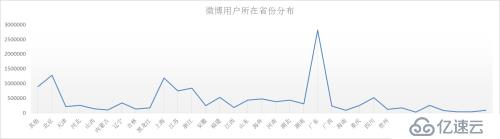
从图中可以看出,广东、北京、上海、江苏、浙江等地微博用户量较大。
该部分Maper函数、Reducer函数与性别统计算法相同,不再赘述,计算结果如下图所示:
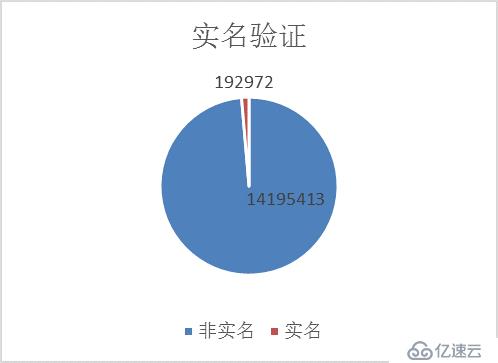
从图中可以看出,非实名用户在微博用户中占绝大部分。
该部分Maper函数、Reducer函数与性别统计算法基本相同,不再赘述,计算结果如下图所示:
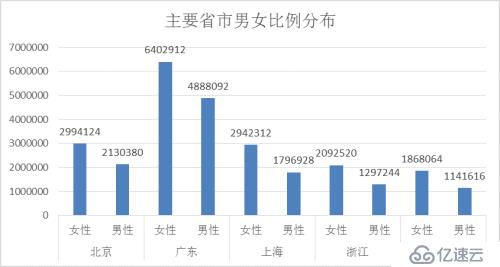
各省市女性用户数量均占所在省市总用户数的一半以上。
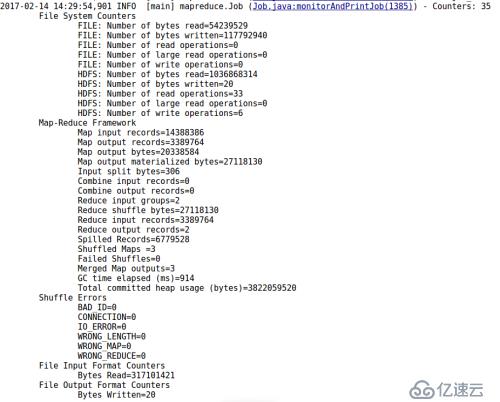
通过浏览控制台和Web管理端输出结果,算法执行过程未见明显异常或报错。控制台输出结果如下图所示:
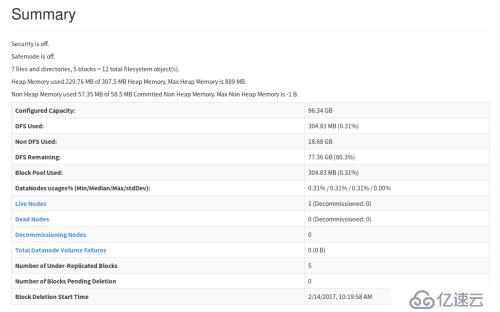
Web端面板统计结果如下图所示:
任务执行结果统计如下图所示:
结合水运行业实际需求,智慧港口建设作为我国港口转型升级的重要途径,其所涉及的关键技术就包含港口数据分析与处理。Hadoop技术在互联网行业已广泛应用,但在港口自动化、智能化建设中还未起到关键、核心作用。因此,大数据分析与挖掘技术在港口领域的深度应用,是港口发展的高级阶段。对我国港口而言,通过打造智慧港口,优化提升港口基础设施和管理模式,实现港口功能创新、技术创新和服务创新,已成为我国港口提高国际竞争力,完成转型升级的重要途径。通过对大数据技术在智慧港口中应用研究,是我国港口信息化积累的海量数据发挥其巨大优势,为我国港口管理部门以及港口企业提供决策支撑,具有重要的显示意义。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





