Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目
http://parquet.apache.org/
这里我们使用的版本为spark2.0.1,是2016年10月3日发布的最新版本。
Spark可以很好的使用和生成Parquet 文件。下面的截图来自官方文档。
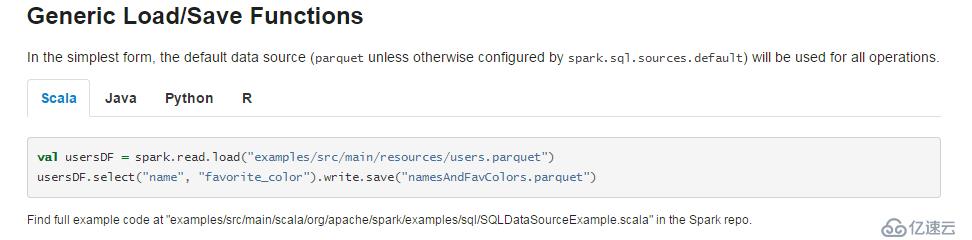
上图的例子中spark读取了一个位于examples/src/main/resources/users.parquet文件夹下的Parquet文件,并对数据进行了筛选后保存在了namesAndFavColors.parquet文件夹中,注意一下,官方文档路径取名加了.parquet,可能会被误解成是一个文件,其实是文件夹,这里自己试一下就可以证实。
Spark也支持将jdbc的数据转换成Parquet文件,下面的例子我们将SQLserver中的测试表1转换成Parquet文件。代码如下

生成好了的文件如下图所示,这里的实验环境为Windows,spark local模式,可以看到,文件名格式为*.snappy.parquet,这里的snappy表示的是压缩的方式,当然,这个压缩方式也是有很多种选择的,不过spark在这里选择了用snappy的压缩方式压缩成parquet文件作为默认策略。
我们看下测试表1在SQLserver中的信息,如下图所示:
可以看到这是一张7000w级别的表,表大小为6.5G,压缩过后的大小为768M,压缩后的大小为原文件大小的11%,节约了89%的空间。整个压缩时间耗时约11min,对于大数据平台来说,存储空间也是很重要的资源,而且对于网络传输有很大提升,在分布式计算中,网络传输有时会成为性能瓶颈。
我们再用另外一张测试表2做实验
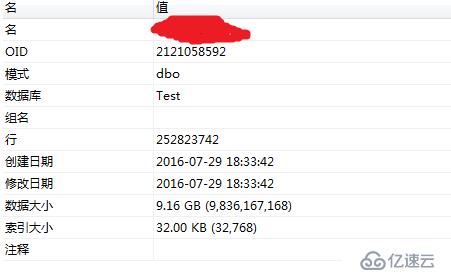
这是一张2.5亿级别的表,表大小为9G,压缩后的大小为3.99G,节约了56%的空间,耗时约17min这是因为列存储格式文件大小不仅和行数有关,也和具体数据有关,不同的数据会有不同的压缩率。
Spark Sql支持直接在sql语句中读取Parquet文件,如下图所示
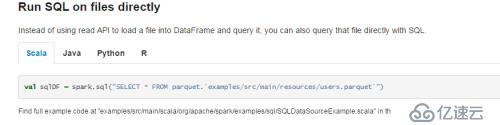
注意,这个语法是spark2.0开始才支持的新特性,利用这个特性,我们可以跳过建表这个过程直接读取文件的数据。
下面我们介绍一下性能。
我们使用三个场景来测试Parquet的性能,这里我们并没有直接去取parquet文件,而是用createOrReplaceTempView方法将其创建为一个view。测试结果如下。
SELECT YEAR(LOGOUT_DT) YR , MONTH(LOGOUT_DT) MTH,Modename,sum(WinCount+LoseCount+DrawCount) GameCount,sum(GameTime) GameTime,sum(GameTime) / sum(WinCount+LoseCount+DrawCount) Avg_GameTime FROM 测试表1 WHERE LOGOUT_DT BETWEEN '2015-01-01' AND '2016-01-01' GROUP BY YEAR(LOGOUT_DT) ,MONTH(LOGOUT_DT) ,Modename limit 1000;
我们再看一下一个对比试验:
Phoenix(poc环境,10台阿里云,集群环境) | 110s |
spark local(8G,4核,i3-4170,单机模式) | 52s |
spark 3node(8G,4核,i3-4170,集群环境) | 12s |
spark 5node (8G,4核,i3-4170,集群环境) | 12s |
hive 普通存储5node (8G,4核,i3-4170,集群环境) | 133s |
hive 列存储5node(parquet)(8G,4核,i3-4170,集群环境) | 43s |
Parquet不仅可以提高spark的查询速度,也可以提高hive的查询速度
集群的计算速度大于单机的计算速度(机器配置相同)
增加计算节点不一定会提高计算速度
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



