这篇文章主要介绍Python编程应用设计原则的示例分析,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
单一职责原则(Single Responsibility Principle)这个原则的英文描述是这样的:A class or module should have a single responsibility。如果我们把它翻译成中文,那就是:一个类或者模块只负责完成一个职责(或者功能)。
让我们举一个更简单的例子,我们有一个数字 L = [n1, n2, …, nx] 的列表,我们计算一些数学函数。例如,计算最大值、平均值等。
一个不好的方法是让一个函数来完成所有的工作:
import numpy as np
def math_operations(list_):
# Compute Average
print(f"the mean is {np.mean(list_)}")
# Compute Max
print(f"the max is {np.max(list_)}")
math_operations(list_ = [1,2,3,4,5])
# the mean is 3.0
# the max is 5实际开发中,你可以认为 math_operations 很庞大,揉杂了各种功能代码。
为了使这个更符合单一职责原则,我们应该做的第一件事是将函数 math_operations 拆分为更细粒度的函数,一个函数只干一件事:
def get_mean(list_):
'''Compute Max'''
print(f"the mean is {np.mean(list_)}")
def get_max(list_):
'''Compute Max'''
print(f"the max is {np.max(list_)}")
def main(list_):
# Compute Average
get_mean(list_)
# Compute Max
get_max(list_)
main([1,2,3,4,5])
# the mean is 3.0
# the max is 5这样做的好处就是:
易读易调试,更容易定位错误。
可复用,代码的任何部分都可以在代码的其他部分中重用。
可测试,为代码的每个功能创建测试更容易。
但是要增加新功能,比如计算中位数,main 函数还是很难维护,因此还需要第二个原则:OCP。
开闭原则(Open Closed Principle)就是对扩展开放,对修改关闭,这可以大大提升代码的可维护性,也就是说要增加新功能时只需要添加新的代码,不修改原有的代码,这样做即简单,也不会影响之前的单元测试,不容易出错,即使出错也只需要检查新添加的代码。
上述代码,可以通过将我们编写的所有函数变成一个类的子类来解决这个问题。代码如下:
import numpy as np
from abc import ABC, abstractmethod
class Operations(ABC):
'''Operations'''
@abstractmethod
def operation():
pass
class Mean(Operations):
'''Compute Max'''
def operation(list_):
print(f"The mean is {np.mean(list_)}")
class Max(Operations):
'''Compute Max'''
def operation(list_):
print(f"The max is {np.max(list_)}")
class Main:
'''Main'''
def get_operations(list_):
# __subclasses__ will found all classes inheriting from Operations
for operation in Operations.__subclasses__():
operation.operation(list_)
if __name__ == "__main__":
Main.get_operations([1,2,3,4,5])
# The mean is 3.0
# The max is 5如果现在我们想添加一个新的操作,例如:median,我们只需要添加一个继承自 Operations 类的 Median 类。新形成的子类将立即被 __subclasses__()接收,无需对代码的任何其他部分进行修改。
里式替换原则的英文是 Liskov Substitution Principle,缩写为 LSP。这个原则最早是在 1986 年由 Barbara Liskov 提出,他是这么描述这条原则的:
If S is a subtype of T, then objects of type T may be replaced with objects of type S, without breaking the program。
也就是说 子类对象能够替换程序中父类对象出现的任何地方,并且保证原来程序的逻辑行为不变及正确性不被破坏。
实际上,里式替换原则还有另外一个更加能落地、更有指导意义的描述,那就是按照协议来设计,子类在设计的时候,要遵守父类的行为约定(或者叫协议)。父类定义了函数的行为约定,那子类可以改变函数的内部实现逻辑,但不能改变函数原有的行为约定。这里的行为约定包括:函数声明要实现的功能;对输入、输出、异常的约定;甚至包括注释中所罗列的任何特殊说明。
接口隔离原则的英文翻译是 Interface Segregation Principle,缩写为 ISP。Robert Martin 在 SOLID 原则中是这样定义它的:Clients should not be forced to depend upon interfaces that they do not use。
直译成中文的话就是:客户端不应该被强迫依赖它不需要的接口。其中的 客户端 ,可以理解为接口的调用者或者使用者。
举个例子:
from abc import ABC, abstractmethod
class Mammals(ABC):
@abstractmethod
def swim(self) -> bool:
pass
@abstractmethod
def walk(self) -> bool:
pass
class Human(Mammals):
def swim(self)-> bool:
print("Humans can swim")
return True
def walk(self)-> bool:
print("Humans can walk")
return True
class Whale(Mammals):
def walk(self) -> bool:
print("Whales can't walk")
return False
def swim(self):
print("Whales can swim")
return True
human = Human()
human.swim()
human.walk()
whale = Whale()
whale.swim()
whale.walk()执行结果:
Humans can swim
Humans can walk
Whales can swim
Whales can't walk
事实上,子类鲸鱼不应该依赖它不需要的接口 walk,针对这种情况,就需要对接口进行拆分,代码如下:
from abc import ABC, abstractmethod
class Swimer(ABC):
@abstractmethod
def swim(self) -> bool:
pass
class Walker(ABC):
@abstractmethod
def walk(self) -> bool:
pass
class Human(Swimer,Walker):
def swim(self)-> bool:
print("Humans can swim")
return True
def walk(self)-> bool:
print("Humans can walk")
return True
class Whale(Swimer):
def swim(self):
print("Whales can swim")
return True
human = Human()
human.swim()
human.walk()
whale = Whale()
whale.swim()依赖反转原则的英文翻译是 Dependency Inversion Principle,缩写为 DIP。英文描述:High-level modules shouldn't depend on low-level modules. Both modules should depend on abstractions. In addition, abstractions shouldn't depend on details. Details depend on abstractions。
我们将它翻译成中文,大概意思就是:高层模块不要依赖低层模块。高层模块和低层模块应该通过抽象(abstractions)来互相依赖。除此之外,抽象不要依赖具体实现细节,具体实现细节依赖抽象。
在调用链上,调用者属于高层,被调用者属于低层,我们写的代码都属于低层,由框架来调用。在平时的业务代码开发中,高层模块依赖低层模块是没有任何问题的,但是在框架层面设计的时候,就要考虑通用性,高层应该依赖抽象的接口,低层应该实现对应的接口。如下图所示:
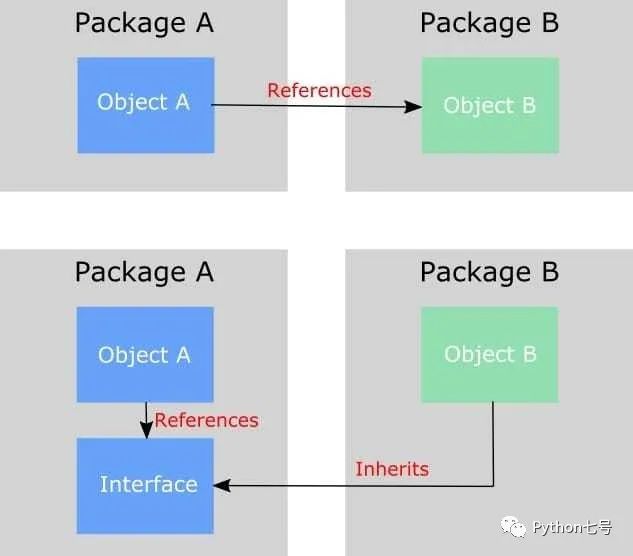
也就是说本来 ObjectA 依赖 ObjectB,但为了扩展后面可能会有 ObjectC,ObjectD,经常变化,因此为了频繁改动,让高层模块依赖抽象的接口 interface,然后让 ObjectB 也反过来依赖 interface,这就是依赖反转原则。
举个例子,wsgi 协议就是一种抽象接口,高层模块有 uWSGI,gunicorn等,低层模块有 Django,Flask 等,uWSGI,gunicorn 并不直接依赖 Django,Flask,而是通过 wsgi 协议进行互相依赖。
依赖倒置原则概念是高层次模块不依赖于低层次模块。看似在要求高层次模块,实际上是在规范低层次模块的设计。低层次模块提供的接口要足够的抽象、通用,在设计时需要考虑高层次模块的使用种类和场景。明明是高层次模块要使用低层次模块,对低层次模块有依赖性。现在反而低层次模块需要根据高层次模块来设计,出现了「倒置」的显现。
这样设计好处有两点:
低层次模块更加通用,适用性更广
高层次模块没有依赖低层次模块的具体实现,方便低层次模块的替换
以上是“Python编程应用设计原则的示例分析”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



