1)启动环境
start-all.sh
2)产看状态
jps
0613 NameNode
10733 DataNode
3455 NodeManager
15423 Jps
11082 ResourceManager
10913 SecondaryNameNode
3)利用Eclipse编写jar
1.编写 MapCal类
package com.mp; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class MapCal extends Mapper<LongWritable, Text, Text, Text> { @Override protected void map(LongWritable lon, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] peps = line.split("-"); // 键值对 context.write(new Text(peps[0]), new Text("s" + peps[1])); context.write(new Text(peps[1]), new Text("g" + peps[0])); } } |
2.编写ReduceCal类
public class ReduceCal extends Reducer<Text, Text, Text, Text> { @Override protected void reduce(Text arg0, Iterable<Text> arg1, Context context) throws IOException, InterruptedException { ArrayList<Text> grands = new ArrayList<Text>(); ArrayList<Text> sons = new ArrayList<Text>(); // 把这些值写入集合 for (Text text : arg1) { String str = text.toString(); if (str.startsWith("g")) { grands.add(text); } else { sons.add(text); } } // 输出 for (int i = 0; i < sons.size(); i++) { for (int j = 0; j < grands.size(); j++) { context.write(grands.get(i), sons.get(j)); } } } } |
3. 编写Jobrun类
public class RunJob { // 全限定名 public static void main(String[] args) { Configuration conf = new Configuration(); // 本地多线程模拟执行。 // conf.set("fs.defaultFS", "hdfs://node3:8020"); // conf.set("mapred.jar", "C:\\Users\\Administrator\\Desktop\\wc.jar"); try { FileSystem fs = FileSystem.get(conf); Job job = Job.getInstance(conf); job.setJobName("wc"); job.setJarByClass(RunJob.class); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReduce.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // job 输入数据和输出数据的目录 FileInputFormat.addInputPath(job, new Path("/word.txt")); Path outPath = new Path("/output/wc2");// job执行结果存放的目录。该目录在执行前不能存在。 if (fs.exists(outPath)) { fs.delete(outPath, true); } FileOutputFormat.setOutputPath(job, outPath); boolean f = job.waitForCompletion(true); if (f) { System.out.println("任务执行成功!"); } } catch (Exception e) { e.printStackTrace(); } } } |
4)导出jar包.
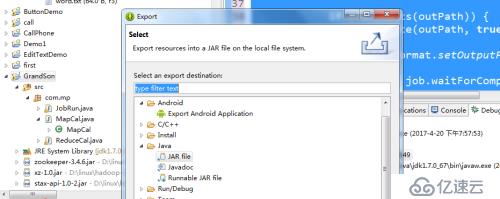
5)通过ftp上传jar到linux目录
6)运行jar包
hadoop jar shuju.jar com.mc.RunJob / /outg
7)如果map和reduce都100%
Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=45 File Output Format Counters Bytes Written=18 |
表示运行成功!!
8)产看结果
hadoop fs -tail /outg/part-r-00000
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



