本篇内容介绍了“如何实现mysql重复记录数据的排查处理”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
前言
分析
数据总计
重复次数占比
where 和 having 的区别
总结
客户当时直接一摞重复标签的盒子码在我面前,我慌得一匹,这怕不是捅娄子了
稍加思索,现在需要做的就是,在数据库中查询出重复的标签,即对一个标签进行统计,判断出计数> 1 的即可
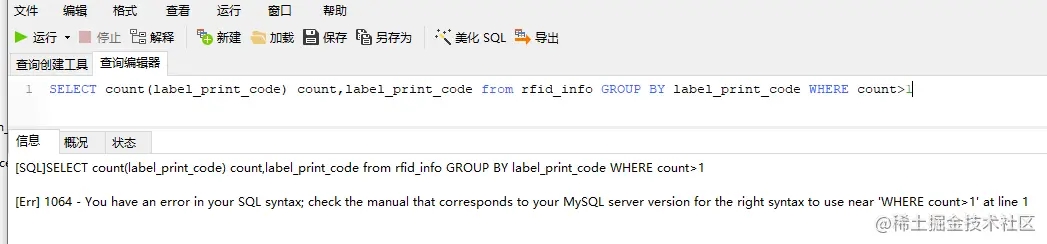
emmm,语法错误,我记得还有个Having 来着,换上试试
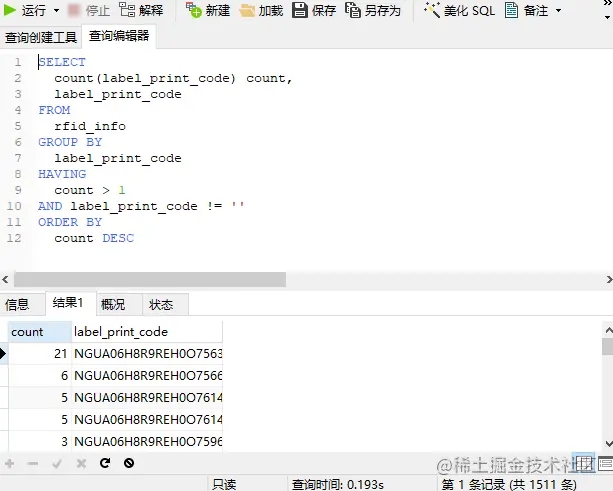
好家伙,重复的标签有 1500 多条,再统计一下总共问题的记录数量,以及再分组看看标签重复次数的占比数据
对了,先把这些重复标签数据扔个客户去追溯产品(幸好 navicat 支持复制数据)
以上一条查询记录的结果为临时表,在此基础上,用 sum() 求和
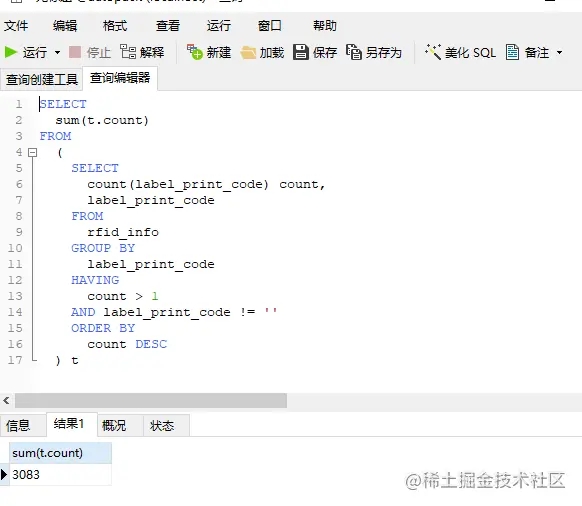
重复的记录有点多,这问题有一点点大了
对之前的查询表换一个查询方式,即对 count 数据再次分组
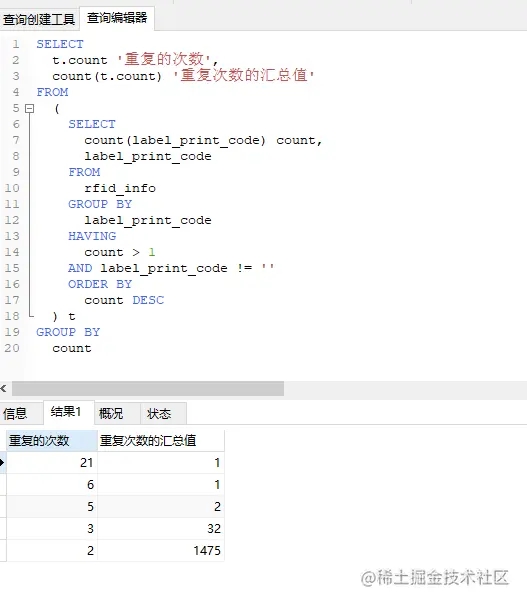
从结果来看,绝大部分问题数据重复了2次
Where是一个 约束声明,在查询数据库的结果返回之前对数据库中的查询条件进行约束,即在结果返回之前起作用,且where后面 不能使用聚合函数
Having是一个 过滤声明,所谓过滤是 在查询数据库的结果返回之后进行过滤,即在结果返回之后起作用,并且having后面可以使用聚合函数。
所谓 聚合函数,是对一组值进行计算并且返回单一值的函数:sum---求和,count---计数,max---最大值,avg---平均值等。
“如何实现mysql重复记录数据的排查处理”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



