本篇内容主要讲解“Python爬虫入门案例之实现回车桌面壁纸网美女图片采集”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Python爬虫入门案例之实现回车桌面壁纸网美女图片采集”吧!
知识点
环境
目标网址:
爬虫代码
导入模块
发送网络请求
获取网页源代码
提取每个相册的详情页链接地址
替换所有的图片链接 换成大图
保存图片 图片名字
翻页
爬取结果
requests
parsel
re
os
python3.8
pycharm2021
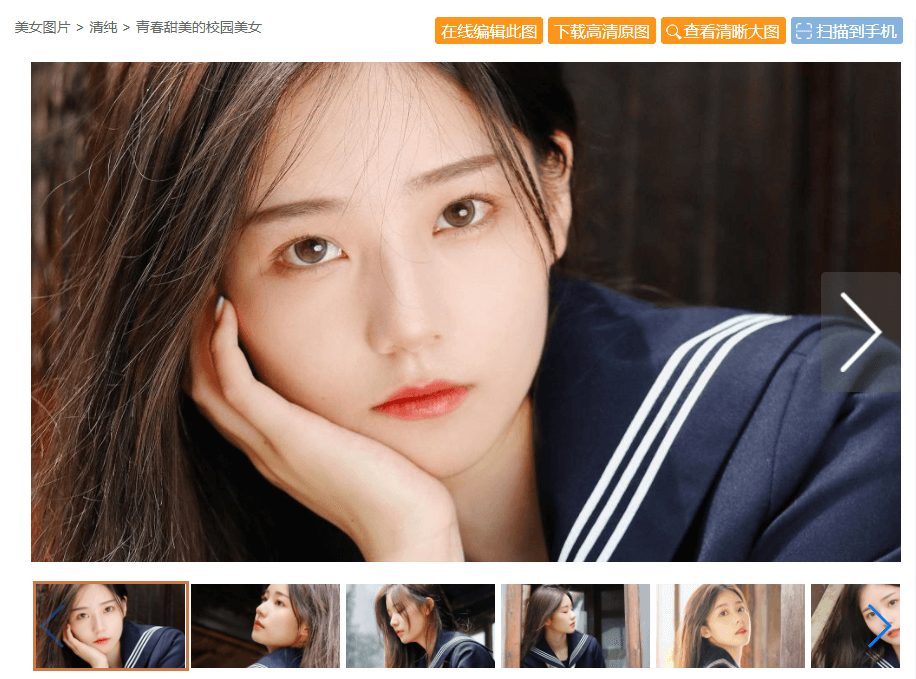
https://mm.enterdesk.com/bizhi/63899-347866.html
【付费VIP完整版】只要看了就能学会的教程,80集Python基础入门视频教学
点这里即可免费在线观看
注意: 在我们查看网页源代码的时候 (1. 控制台为准 2. 以右键查看网页源代码 3. 元素面板)
发送网络请求
获取网页源代码
提取想要的图片链接 css样式提取 xpath re正则表达式 bs4
替换所有的图片链接 换成大图
保存图片
import requests # 第三方库 pip install requests
import parsel # 第三方库 pip install parsel
import os # 新建文件夹response = requests.get('https://mm.enterdesk.com/bizhi/64011-348522.html')data_html = response_1.textselector_1 = parsel.Selector(data_html)
photo_url_list = selector_1.css('.egeli_pic_dl dd a::attr(href)').getall()
title_list = selector_1.css('.egeli_pic_dl dd a img::attr(title)').getall()
for photo_url, title in zip(photo_url_list, title_list):
print(f'*****************正在爬取{title}*****************')
response = requests.get(photo_url)
# <Response [200]>: 请求成功的标识
selector = parsel.Selector(response.text)
# 提取想要的图片链接[第一个链接, 第二个链接,....]
img_src_list = selector.css('.swiper-wrapper a img::attr(src)').getall()
# 新建一个文件夹
if not os.path.exists('img/' + title):
os.mkdir('img/' + title)for img_src in img_src_list:
# 字符串的替换
img_url = img_src.replace('_360_360', '_source')# 图片 音频 视频 二进制数据content
img_data = requests.get(img_url).content
# 图片名称 字符串分割
# 分割完之后 会给我们返回一个列表
img_title = img_url.split('/')[-1]
with open(f'img/{title}/{img_title}', mode='wb') as f:
f.write(img_data)
print(img_title, '保存成功!!!')page_html = requests.get('https://mm.enterdesk.com/').text
counts = parsel.Selector(page_html).css('.wrap.no_a::attr(href)').get().split('/')[-1].split('.')[0]
for page in range(1, int(counts) + 1):
print(f'------------------------------------正在爬取第{page}页------------------------------------')
发送网络请求
response_1 = requests.get(f'https://mm.enterdesk.com/{page}.html')
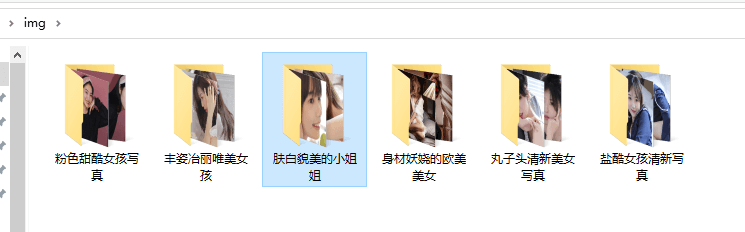
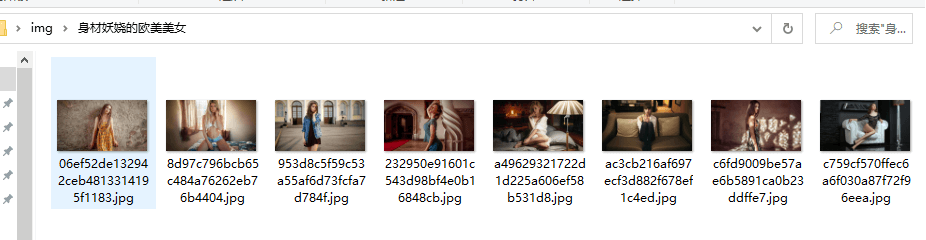
到此,相信大家对“Python爬虫入门案例之实现回车桌面壁纸网美女图片采集”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



