Avro schema作为大数据一个项目,它可以算得上精品中的上等品,让学习或者想要学习大数据的人为之倾倒,不断挖掘学习,那么它究竟有着怎样的神秘面纱呢?我们一起来揭开!
为了理解Avro,首先要理解序列化。序列化是在内存里表述数据的一种方式,它是一连串的字节,可以保存数据到磁盘或通过网络发送出去,反序列化允许你把数据读回到内存。
举个实际的例子,我们如何序列化数字108125150?可以指定一些具体类型:(1)当存储为Java int类型时是4 bytes;(2)当存储为Java string类型时是9 bytes.
很多编程语言和库都支持序列化,比如Java里的Serializable或Python的pickle。但是向后兼容和交叉语言支持对我们来讲可能是一项挑战,而Avro就是开发出来应对这些挑战。
什么是Apache Avro
Avro数据文件格式只是Avro项目的一部分,它是高效的数据序列化框架,是由Doug Cutting创立的Apache顶级项目,在Hadoop和它的生态系统得到广泛的支持。最大的特点就是在不牺牲性能的前提下提供兼容性,可在Java、C、C++、C#、Python、PHP和其他语言中读写数据。Avro也支持RemoteProcedure Calls(RPC),可以用于构建定制网络协议,而且Flume使用它进行内部通信。
AvroSchemas支持的类型
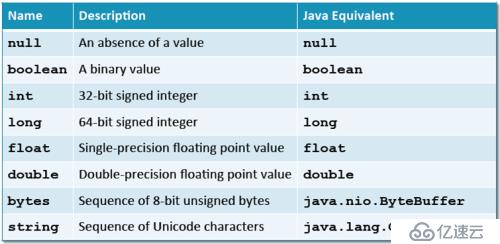
(1)简单类型:
(2)复杂类型

这里record类型最重要,其他类型主要用来定义record的字段。
基本schema示例
这里我们先引用一段SQL CREATE TABLE语句

然后我们使用Avro schema来表达同样的语句

在Schema里指定默认值
Avro支持在schema里设置默认值,当没有明确指定字段值的时候使用,和SQL相似

AvroSchemas和Null值
(1)当序列化数据时Avro检查null值
(2)当在schema里明确指定时才可以使用Null值

复杂类型的schema示例
示例:带enum和string array类型的record

注释schema
给schema加注释是一种避免歧义的好的做法
(1)所有的类型都支持加上可选的doc属性

Avro容器格式
Avro定义了一种容器文件格式来存储Avro记录,也称为“Avro数据文件格式”。和Hadoop SequenceFile格式相似,支持交叉语言的数据读写。它也支持块记录的压缩,压缩后数据可分片。另外这种格式是自描述的,每个文件包含一份schema的拷贝,用于写数据,并且所有记录在文件中必须使用相同的schema。
使用Avro工具检查Avro数据文件
Avro数据文件是一种高效存储数据的方式,然而,二进制格式使得debug很不方便。使用avro-tools命令来操作二进制文件,可以读取Avro文件里的schema或数据。

挖掘了一番,你有没有挖掘到宝贝呢?如果找到了,这绝对是你的私人财产,如果没有,也没有关系,因为还有猛料等你来!盛大网络大咖亲自坐镇,分享大数据干货,一起来吧!关注微信公众号“大数据cn”,一起来交流。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



