快一年没写博客了,终于回来了,最近因公司业务需要,要基于cdh发行版打包自定义patch的rpm,于是又搞起了bigtop,就是那个hadoop编译打包rpm和deb的工具,由于国内基本没有相关的资料和文档,所以觉得有必要把阅读bigtop源码和修改的思路分享一下。
我记得很早以前,bigtop在1.0.0以前版本吧,是用make进行打包的,其实这个0.9.0以前的版本,搁我觉得就不应该出现在apache正式仓库里,就应该放在incubator里面,但是估计由于是cdh主导开发的,而Doug Cutting又是前基金会主席,所以,一个基本没有产品化的东西从孵化器提升到顶级项目相对容易一些吧。cloudera官方在github上开源的的cdh-package应该是基于bigtop 0.6.0的,不过由于他们的每个git分支只更新rpm的spec文件,所以,貌似默认情况下根本使不了,不厚道啊。而apache的bigtop又没有cdh相关的avro,sentry,llama等依赖,所以只能自己读源码修改。
解决方案一:基于cdh-package进行修改,优势是贴近cloudera,可能需要修改的代码量比较少,劣势是基于make,后期维护性和可扩展性较差,我可不想去改Makefile那种东西。
解决方案二:基于apache bigtop进行修改,优势是使用gradle编译,可维护性可扩展性好,劣势是代码修改量大。
考虑再三,我决定还是贴近社区,远离资本家,跟广大无产阶级走,所以我选择了apache bigtop,另外,cdh-package除了需要java1.7以外,还需要java1.5,所以。Let it be.
当然,这里有很多坑都需要踩,其中最大的一个坑就是GFW。感谢政府对我一奔四十的老爷们的思想保护,远离黄赌毒,用伟大的长城防火墙屏蔽了全世界。伟大的长城防火墙不但有花季护航,还有而立护航,不惑护航,知天命护航,耳顺护航及古稀护航,耄耋护航,期颐护航等众多配置选项,保护国人从生到死不受国外先进技术的侵蚀。
所以,如果你想正常编译hadoop及其周边生态,听我的,买个国外的云主机,绝对事半功倍。同时,为了保证对bigtop修改本身的版本控制及错误回滚,git或者svn是需要的。
以下内容基于bigtop 1.1.0 production以及美国云主机
打包编译相关技能天赋加点:
gradle, maven, ant, forrest, groovy, shell, rpm spec.特别是shell和spec的天赋要尽可能点满,不行就去看rpm.org里面的文档。而maven和ant基本都是自动施法,不太需要点天赋。另外,maven, ant, java本身的版本就不再赘述了。
按照我对bigtop源码的理解,分为执行层,编译层和脚本层。执行层即gradle和gradle的相关定义文件。编译层包括maven, ant,嵌套在maven里的ant,forrest,scala等。脚本层为rpm的spec文件,deb的定义文件以及他们所包含的编译相关脚本,如do-build-components这类脚本。
定义编译什么东西及它的版本,下载地址的定义,文件名的定义是在bigtop.bom中定义的,然后会调用package.gradle来进行自动下载及配置编译目录,打包目录等。之后会通过package.gradle调用rpmbuild来读取spec文件,spec文件会通过内部的Source0这类的定义来读取编译脚本,最终通过rpmbuild来建立所有需要的rpm包。
初始下载解压缩bigtop-1.1.0之后,需要先对bigtop依赖的包进行初始化,会下载protobuf,snappy什么的。完成之后用户可以编译的是apache的hadoop及周边相关,编译之后是可以用,但是不符合我的需求。为啥,因为cloudera 2B似的为显示自己牛逼,兼容,搞了一个画蛇添足的0.20-mapreduce。由于之前集群安装的是cdh的hadoop,已安装的rpm依赖里面有0.20的安装包,所以,如果我用原生apache bigtop打包出来的 cdh hadoop,是没有0.20这个package的。那么在自己做了repository之后用yum update,会提示缺少0.20的依赖,需要使用--skip-broken来安装,作为一个×××座是不允许这种情况发生的。另外,据同事反馈,cdh的hadoop如果使用apache的zookeeper做ha时会出现找不到znode的问题,无法ha。
所以,唯一的解决办法是找到cdh的spec文件,打的跟cdh一模一样才可以。这东西其实并不难找,留个问题自己发现吧。不过,直接取出来的cdh spec文件与打包脚本,在apache bigtop上是不能直接使用的。需要修改不少地方,比如像prelink,还有需要建立一套busybox出来,当然其他的打包依赖还有诸如boost,llvm,thrift等等。还有,cdh会把自己的编译依赖建立在/opt/toolchain下面,但是apache bigtop不会有这东西,自己建软链就可以解决了。
写着写着趴下眯了一会午觉,起来突然不知道该写什么了,如果熟悉之前说的天赋加点,这玩意确实没什么难度。如果不熟悉,那这玩意是相当的难以理解和使用,会遇到各种各样的报错,特别是如果在rpmbuild过程中报错,是很难找到出错原因的。
至于建立yum仓库这种事情就更不用描述了。
整个项目的关键点就是脚本和spec语言,gradle语言都是次要的。
最后,为显示自己牛逼,放两张截图出来。
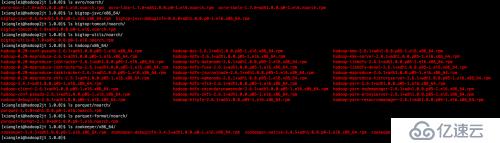

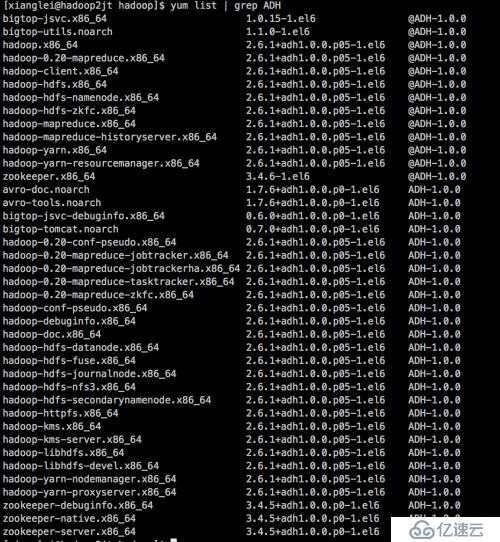
我的下一个milestone是把hortonworks的storm package打到cdh hadoop上面跑。不过在实现这个目标之前,似乎公司要把我派去写hive和pig脚本,真是没兴趣啊。
最后,打个广告,Nathan Marz (Storm作者) 的书,《大数据系统构建--Lambda架构实践》上市。译者:马延辉,魏东琦,还有我,欢迎大家踊跃购买,看完之后批评指正。
购买链接
京东
当当
亚马逊
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





