这篇文章主要介绍“如何理解Python获取网页数据流程”,在日常操作中,相信很多人在如何理解Python获取网页数据流程问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”如何理解Python获取网页数据流程”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
Requests 库是 Python 中发起 HTTP 请求的库,使用非常方便简单。
发送 GET 请求
当我们用浏览器打开东旭蓝天股票首页时,发送的最原始的请求就是 GET 请求,并传入url参数.
import requests url='http://push3his.eastmoney.com/api/qt/stock/fflow/daykline/get'
用Python requests库的get函数得到数据并设置requests的请求头.
header={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}得到network的参数.
data={
'cb': 'jQuery1123026726575651052076_1633873068863',
'lmt': '0',
'klt':' 101',
'fields1': 'f1,f2,f3,f7',
'fields2': 'f51,f52,f53,f54,f55,f56,f57,f58,f59,f60,f61,f62,f63,f64,f65',
'ut': 'b2884a393a59ad64002292a3e90d46a5',
'secid': '0.000040',
'_': '1633873068864'
}我们使用 content 属性来获取网站返回的数据,并命名为sd.
sd=requests.get(url=url,headers=header,data=data).content
json库可以自字符串或文件中解析JSON。 该库解析JSON后将其转为Python字典或者列表。re模块是python独有的匹配字符串的模块,该模块中提供的很多功能是基于正则表达式实现的,而正则表达式是对字符串进行模糊匹配,提取自己需要的字符串部分.
import json import re text=str(sd,'utf-8') res=re.findall(r'[(](.*?)[)]',text) re=json.loads(res[0]) p=re['data']['klines']
将杂乱无章的数据排版到excel中,代码如下:
all_list=re['data']['klines']
data_list=[]
latest_price_list=[]
price_limit_list=[]
net_amount_list1=[]
net_proportion_list1=[]
net_amount_list2=[]
net_proportion_list2=[]
net_amount_list3=[]
net_proportion_list3=[]
net_amount_list4=[]
net_proportion_list4=[]
net_amount_list5=[]
net_proportion_list5=[]
for i in range(len(all_list)):
data=all_list[i].split(',')[0]
data_list.append(data)
##收盘价
latest_price=all_list[i].split(',')[11]
latest_price_list.append(latest_price)
##涨跌幅
price_limit=all_list[i].split(',')[12]
price_limit_list.append(price_limit)
##主力净流入
####净额
net_amount1=all_list[i].split(',')[1]
net_amount_list1.append(net_amount1)
##占比
net_proportion1=all_list[i].split(',')[6]
net_proportion_list1.append(net_proportion1)
##超大单净流入
####净额
net_amount2=all_list[i].split(',')[5]
net_amount_list2.append(net_amount2)
##占比
net_proportion2=all_list[i].split(',')[10]
net_proportion_list2.append(net_proportion2)
##大单净流入
####净额
net_amount3=all_list[i].split(',')[4]
net_amount_list3.append(net_amount3)
##占比
net_proportion3=all_list[i].split(',')[9]
net_proportion_list3.append(net_proportion3)
##中单净流入
####净额
net_amount4=all_list[i].split(',')[3]
net_amount_list4.append(net_amount4)
##占比
net_proportion4=all_list[i].split(',')[8]
net_proportion_list4.append(net_proportion4)
##小单净流入
####净额
net_amount5=all_list[i].split(',')[2]
net_amount_list5.append(net_amount5)
##占比
net_proportion5=all_list[i].split(',')[7]
net_proportion_list5.append(net_proportion5)
#print(data_list)import pandas as pd
df=pd.DataFrame()
df['日期'] = data_list
df['收盘价'] = latest_price_list
df['涨跌幅(%)'] = price_limit_list
df['主力净流入-净额'] = net_amount_list1
df['主力净流入-净占比(%)'] = net_proportion_list1
df['超大单净流入-净额'] = net_amount_list2
df['超大单净流入-净占比(%)'] = net_proportion_list2
df['大单净流入-净额'] = net_amount_list3
df['大单净流入-净占比(%)'] = net_proportion_list3
df['中单净流入-净额'] = net_amount_list4
df['中单净流入-净占比(%)'] = net_proportion_list4
df['小单净流入-净额'] = net_amount_list5
df['小单净流入-净占比(%)'] = net_proportion_list5
df# 写入excel
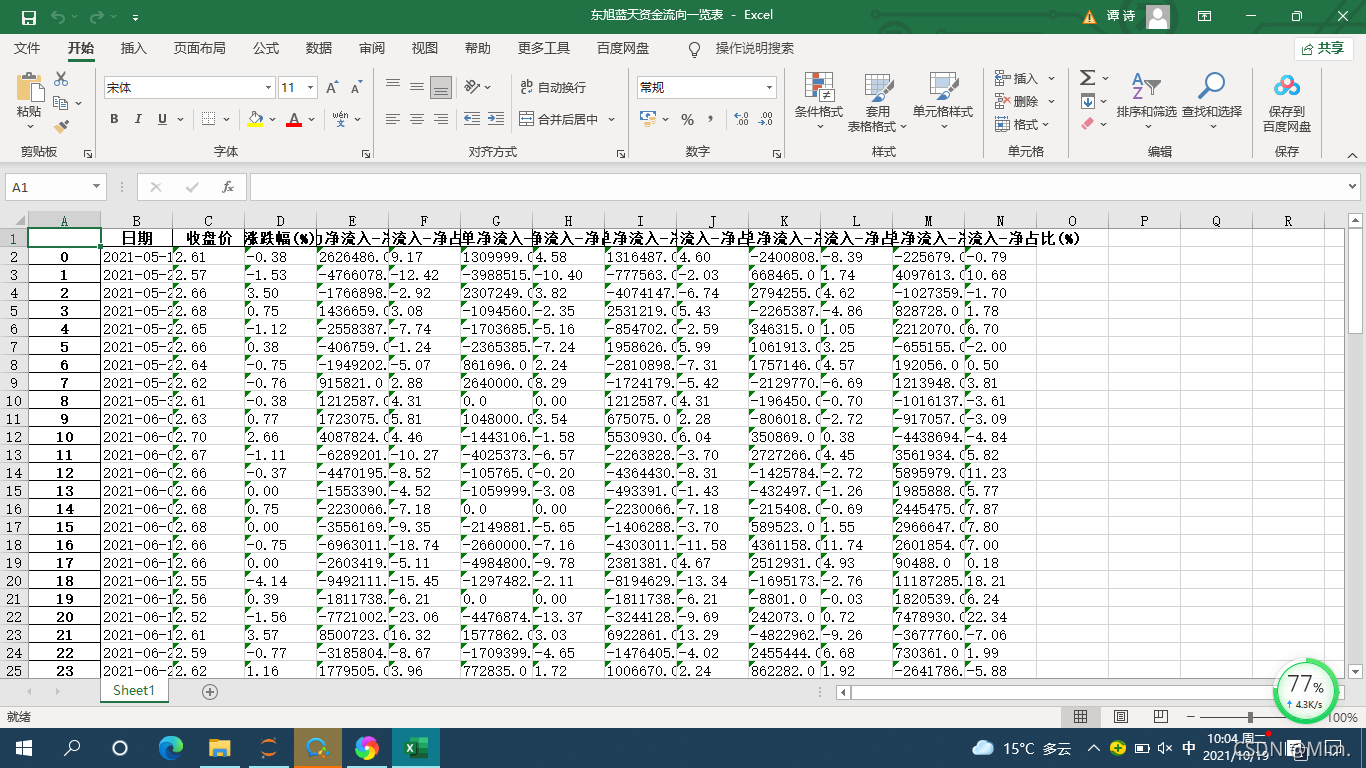
df.to_excel('东旭蓝天资金流向一览表.xlsx')将爬取出的东旭蓝天资金流向数据存到excel表中,得到表格的部分截图如下:
到此,关于“如何理解Python获取网页数据流程”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





