文件存储分行存储和列存储,每个存储格式里面又分不同的类型,在实际的应用中如何去使用?怎样去使用?快来围观吧!
文件存储格式,我们在什么时候去指定呢?比如在Hve和Ipala中去创建表的时候,我们除了指定列和分隔符,在它的命令行结尾有STORED AS参数,这个参数默认是文本格式,但是文本不适合所有的场景,那么在这里我们就可以改变文本的信息。
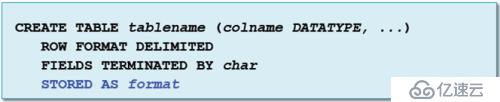
那么到底我们应该选择哪些格式呢?每种格式都有什么样的特点呢?我们为什么要去选择这种格式呢?
一、文本文件:
文本文件是Hadoop里面最基本的文件类型,可以从任何编程语言进行读或写,兼容逗号和tab分隔的文件以及其它很多的应用。而且文本文件直接可读的,因为都是字符串,所以在Debug的时候非常有用。然而,数据到达一定规模,这种格式是很低效的:(1)文本文件把数值表示为string浪费了存储空间;(2)很难表示二进制的数据,比如图片,通常依靠其他技术,比如Base64编码
所以文本文件格式总结起来就是:易操作,但性能低
二、序列文件
序列文件本质是基于key-value键值对的二进制容器格式,它比文本格式冗余更少,更高效,适合存储二进制数据,比如图片。而且它是Java专有格式并且跟Hadoop紧密结合。
所以序列文件格式总结起来就是:性能好,但难操作
三、Avro数据文件
Avro数据文件是二进制编码,存储效率更好。它不仅可以在Hadoop生态系统得到广泛支持,还可以在Hadoop之外使用。它是长期存储重要数据的理想选择,可以通过多种语言读写。
而且它内嵌schema文件,通过这个文件我们可以很轻松的像表一样去定义数据的模式,可以灵活制定字段及字段类型。Schema演化可以适应各种变化,比如当前指定一个Schema类型,将来增加了一些数据结构、删除了一些数据、类型发生了变更、长度发生了变更,都是可以应对的。
所以Avro数据文件格式总结起来就是:极好的操作性和性能,是Hadoop通用存储的最佳选择。
以上介绍的三种格式都是行存储,但是Hadoop里面还有一些列存储格式。典型的OLTP以行的形式来存储,就是以连续的行来存储到连续的块,当我们进行随机的寻值访问的时候,我们通常会去加一些条件,对于行存储而言可以迅速定义到块所在位置,然后提取行的数据。而列存储以列为单位进行存储,如果将列存储应用于OLTP我们要定义到特定行进行扫描的时候,它会扫描到所有的列。对于列存储应用到在线事务场景处理就是一个很恐怖的事情,列存储的意义在于应用于大数据分析场景,比如进行特征值的抽取,变量的筛选,通常在大数据场景应用中我们会大量的应用宽表,可能对于某一业务分析而言,我们只需要使用其中一个或几十个这样的列,那么就可去选择一些列进行扫描,不会扫描到全表。行存储与列存储并没有绝对的好坏之分,只是彼此适用的场景不一样。
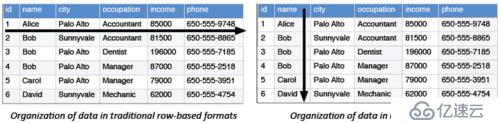
下面我们看一下列存储重要的存储方式:
一、Parquet文件
Parquet文件格式非常重要,在未来也将会被广泛的使用。我们把HDFS称作是大数据存储事实标准的话,那么Parquet文件就是文件存储格式的事实标准。目前spark已经把它作为默认的文件存储格式,可见它的重要性。最初由cloudera和twitter开发的开源列存储格式,在MapReduce、Hive、Pig、Impala、Spark、Crunch和其他项目中支持应用。它和Avro数据文件都有Schema元数据,区别只是Parquet文件是列存储,Avro数据文件是行存储。这里必须要强调的是Parquet文件在编码方面进行了一些额外优化,减少存储空间,增加了性能。
所以Parquet文件总结起来就是:极好的操作性和性能,是基于列访问模式的最佳选择。
文件存储格式,需要重点去把握和学习,尤其是每种存储格式优劣势,必须熟练掌握,才可以在使用中更好的去选择使用。另外,我们在平常的工作中也要多去和别人分享交流,这样才会更好的完善自己的知识架构,提升自己的技术水平,友情推荐“大数据cn”微信公众号,等你来交流!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





