жҖҺд№Ҳз”ЁPythonиҜ»еҸ–CSVж–Ү件
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶжҖҺд№Ҳз”ЁPythonиҜ»еҸ–CSVж–Ү件пјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« д№ӢеҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©е°Ҹзј–еёҰзқҖеӨ§е®¶дёҖиө·дәҶи§ЈдёҖдёӢгҖӮ
е…ёеһӢзҡ„ж•°жҚ®йӣҶstocks.csvпјҡ
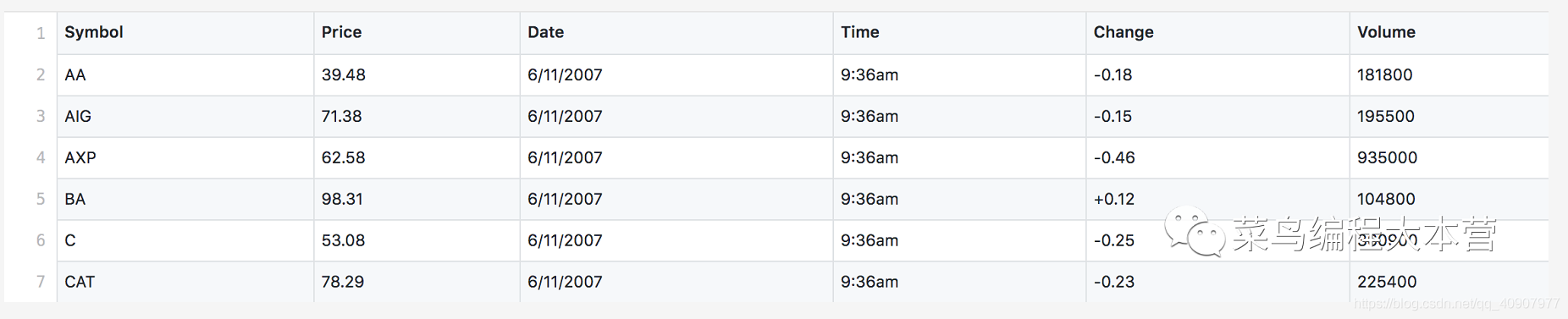
дёҖдёӘиӮЎзҘЁзҡ„ж•°жҚ®йӣҶпјҢе…¶е®һе°ұжҳҜеёёи§Ғзҡ„иЎЁж јж•°жҚ®гҖӮжңүиӮЎзҘЁд»Јз ҒпјҢд»·ж јпјҢж—ҘжңҹпјҢж—¶й—ҙпјҢд»·ж јеҸҳеҠЁе’ҢжҲҗдәӨйҮҸгҖӮиҝҷдёӘж•°жҚ®йӣҶе…¶е®һе°ұжҳҜдёҖдёӘиЎЁж јж•°жҚ®пјҢжңүиҮӘе·ұзҡ„еӨҙйғЁе’Ңиә«дҪ“гҖӮ
第дёҖжӢӣпјҡз®ҖеҚ•зҡ„иҜ»еҸ–
жҲ‘们е…ҲжқҘзңӢдёҖз§Қз®ҖеҚ•иҜ»еҸ–ж–№жі•пјҢе…Ҳз”Ёcsv.reader()еҮҪж•°иҜ»еҸ–ж–Ү件зҡ„еҸҘжҹ„fз”ҹжҲҗдёҖдёӘcsvзҡ„еҸҘжҹ„пјҢе…¶е®һе°ұжҳҜдёҖдёӘиҝӯд»ЈеҷЁпјҢжҲ‘们зңӢдёҖдёӢиҝҷдёӘreaderзҡ„жәҗз Ғпјҡ
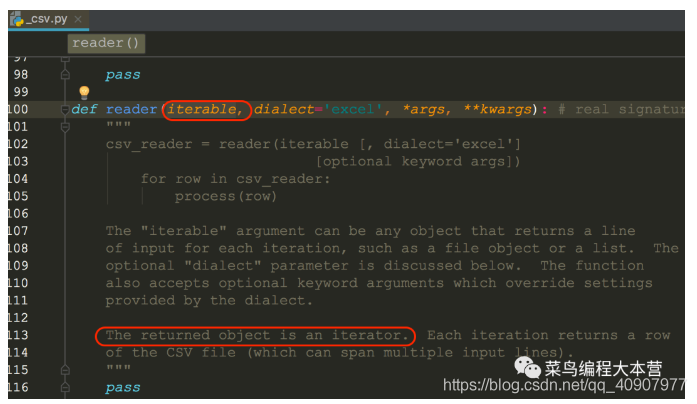
е–Ӯз»ҷreaderдёҖдёӘеҸҜиҝӯд»ЈеҜ№иұЎжҲ–иҖ…жҳҜж–Ү件зҡ„objectпјҢ然еҗҺиҝ”еӣһдёҖдёӘеҸҜиҝӯд»ЈеҜ№иұЎгҖӮ

йҰ–е…ҲиҜ»еҸ–csv ж–Ү件пјҢ然еҗҺз”Ёcsv.readerз”ҹжҲҗдёҖдёӘcsvиҝӯд»ЈеҷЁf_csv
然еҗҺеҲ©з”Ёиҝӯд»ЈеҷЁзҡ„зү№жҖ§пјҢnext(f_csv)иҺ·еҸ–csvж–Ү件зҡ„еӨҙпјҢд№ҹе°ұжҳҜиЎЁж јж•°жҚ®зҡ„еӨҙ
жҺҘзқҖеҲ©з”ЁforеҫӘзҺҜпјҢдёҖиЎҢдёҖиЎҢжү“еҚ°rowзҡ„еҶ…е®№пјҢд№ҹе°ұжҳҜиЎЁж јж•°жҚ®зҡ„иә«дҪ“

第дәҢжӢӣпјҡз”Ёnametuple
дёҠйқўзҡ„第дёҖжӢӣе…¶е®һжҳҜжңҖз®ҖеҚ•зҡ„пјҢдёӢйқўжҲ‘们用nametuple жқҘеҢ…иЈ№дёҖдёӢиҝҷдёӘз”ҹжҲҗзҡ„rowж•°жҚ®гҖӮ

nametupleе…¶е®һжҳҜдёҖдёӘйқһеёёжңүз”Ёзҡ„зұ»пјҢиҝҷдёӘзұ»еұһдәҺcollectionsжЁЎеқ—пјҢиҖҢиҝҷдёӘжЁЎеқ—з®Җзӣҙе°ұжҳҜдёҖдёӘзҷҫе®қз®ұйҮҢйқўжңүйқһеёёеӨҡзҡ„зүӣйҖјзҡ„еә“пјӣ
иҝҷйҮҢжҲ‘们用next(f_csv)е…¶е®һе°ұжҳҜиҺ·еҸ–иЎЁж јзҡ„еӨҙйғЁжқҘеҲқе§ӢеҢ–иҝҷдёӘRowпјӣ
然еҗҺеҫӘзҺҜжқҘжһ„йҖ иҝҷдёӘRowзҡ„ж•°жҚ®пјҢжҠҠжҲ‘д»¬иЎЁж јйҮҢйқўзҡ„жҜҸдёҖиЎҢзҡ„ж•°жҚ®йғҪе–ӮжҲҗnametupleж јејҸзҡ„row_info;
иҝҷж ·еҒҡзҡ„еҘҪеӨ„е°ұжҳҜдҪ еҸҜд»ҘйҡҸеҝғжүҖж¬Ізҡ„и®ҝй—®иҝҷдёӘrow_infoйҮҢйқўзҡ„ж•°жҚ®пјҢе°ұжғіи®ҝй—®зұ»ж•°жҚ®дёҖж ·пјҢжҜ”еҰӮrow_info.price
第дёүжӢӣпјҡз”Ёtupleзұ»еһӢиҪ¬жҚў
еҰӮжһңжҲ‘们еҜ№csvж•°жҚ®жҜҸдёҖиЎҢзҡ„зұ»еһӢйғҪйқһеёёжё…жҘҡзҡ„иҜқпјҢеҳҝеҳҝеҸҜд»Ҙз”ЁдёҖдёӘи®ҫе®ҡеҘҪзҡ„ж•°жҚ®ж јејҸиҪ¬жҚўеӨҙжқҘеҜ№ж•°жҚ®иҝӣиЎҢиҪ¬жҚўгҖӮ
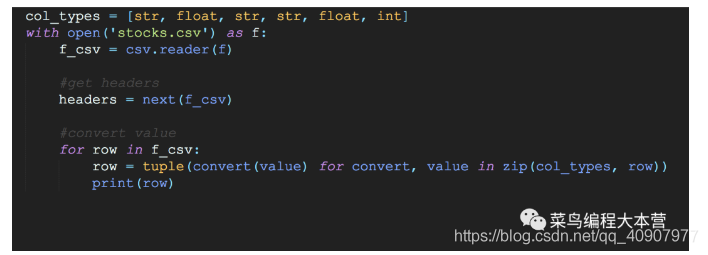
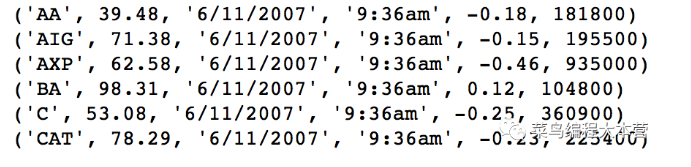
ж“ҚдҪңзҡ„жӯҘйӘӨе…¶е®һи·ҹдёҠйқўе·®дёҚеӨҡпјҢе°ұжҳҜеҜ№ж•°жҚ®з»“жһңзҡ„жё…жҙ—еӨ„зҗҶзЁҚеҫ®дёҚдёҖж ·гҖӮиҝҷйҮҢйқһеёёе·§еҰҷзҡ„zipжқҘжһ„йҖ дёҖдёӘеөҢеҘ—зҡ„ж•°жҚ®еҲ—иЎЁпјҢ然еҗҺз”Ёconvert(data)жҠҠcsvж–Ү件йҮҢйқўжҜҸдёҖиЎҢзҡ„ж•°жҚ®иҝӣиЎҢзұ»еһӢиҪ¬жҚўпјҢиҝҷжӢӣзңҹзҡ„дёҚй”ҷпјҒ
зңӢдёҖдёӢз»“жһңпјҡ
第еӣӣжӢӣпјҡз”ЁDictReader
дёҠйқўз”Ёзҡ„nametupleе…¶е®һд№ҹжҳҜдёҖдёӘж•°жҚ®зҡ„жҳ е°„пјҢжңүжІЎжңүд»Җд№Ҳж–№жі•еҸҜд»ҘзӣҙжҺҘжҠҠcsv зҡ„еҶ…е®№з”Ёжҳ е°„зҡ„ж–№жі•иҜ»еҸ–пјҢзӣҙжҺҘеҮәжқҘдёҖдёӘеӯ—е…ёпјҢиҝҳзңҹжңүзҡ„пјҢжқҘзңӢдёҖдёӢд»Јз Ғпјҡ

жҳҜдёҚжҳҜйқһеёёз®ҖжҚ·пјҢеҺҹжқҘcsvжЁЎеқ—зӣҙжҺҘеҶ…зҪ®дәҶDictReader()пјҢжҢүз…§еӯ—е…ёзҡ„ж–№жі•иҝӣиЎҢиҜ»еҸ–пјҢ然еҗҺз”ҹжҲҗдёҖдёӘжңүеәҸзҡ„еӯ—е…ёпјҢзңӢдёҖдёӢз»“жһңпјҡ
жңүе…ҙи¶Јзҡ„еҸҜд»ҘзңӢдёҖдёӢиҝҷдёӘDictReader()зҡ„жәҗз ҒпјҢе®ғе…¶е®һдёҖдёӘеҶ…йғЁжһ„йҖ зҡ„иҝӯд»ЈеҷЁзұ»пјҢеңЁеҶ…йғЁзҡ„__next__е…¶е®һд№ҹжҳҜз”Ёзҡ„OrderedDict(zip(self.fieldnames, row))жқҘз”ҹжҲҗзҡ„гҖӮ
第дә”жӢӣпјҡз”Ёеӯ—е…ёиҪ¬жҚў
еҰӮжһңжҲ‘们йңҖиҰҒеҜ№иҝҷдёӘcsvйҮҢйқўзҡ„ж•°жҚ®иҝӣиЎҢжё…жҙ—пјҢеӣ дёәиҜ»еҮәжқҘзҡ„ж—¶еҖҷйғҪжҳҜеӯ—з¬ҰдёІпјҢжҲ‘们йңҖиҰҒжӣҙж–°дёәзү№е®ҡзҡ„ж•°жҚ®зұ»еһӢпјҢиҝҷдёӘж—¶еҖҷд№ҹеҸҜд»Ҙз”Ёеӯ—е…ёиҪ¬жҚўиҝҷдёҖжӢӣпјҢд№ҹжҳҜйқһеёёе·§еҰҷзҡ„пјҢжҲ‘们зңӢдёҖдёӢжәҗз Ғпјҡ

еҺҹжқҘзҡ„ж•°жҚ®д»·ж јPriceе’ҢжҲҗдәӨйҮҸпјҢжҲ‘еёҢжңӣжңҖеҗҺиҜ»еҸ–з”ҹжҲҗзҡ„жҳҜдёҖдёӘжө®зӮ№еһӢж•°жҚ®е’Ңж•ҙеҪўзҡ„ж•°жҚ®пјҢиҝҷд№Ҳжҗһе‘ўпјҢз”ЁдёҖдёӘеӯ—е…ёжқҘе·§еҰҷзҡ„жӣҙж–°keyеҚіеҸҜгҖӮ
йҰ–е…ҲжҲ‘们声жҳҺдёҖдёӘиҮӘе®ҡд№үзҡ„зұ»еһӢиҪ¬жҚўеҷЁfield_types;
然еҗҺеҫӘзҺҜз”ҹжҲҗдёҖдёӘеҸҜиҝӯд»Јзҡ„еҜ№иұЎ(key,conversion(row[key]);
жңҖеҗҺжӣҙж–°дёҖдёӢеӯ—е…ёйҮҢйқўзӣёеҗҢзҡ„key,жҜ”еҰӮrow[вҖҳprice']зҡ„еҶ…е®№е°ұдјҡиў«жӣҙж–°дәҶ
ж„ҹи°ўдҪ иғҪеӨҹи®Өзңҹйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« пјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„вҖңжҖҺд№Ҳз”ЁPythonиҜ»еҸ–CSVж–Ү件вҖқиҝҷзҜҮж–Үз« еҜ№еӨ§е®¶жңүеё®еҠ©пјҢеҗҢж—¶д№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘пјҢе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶзӯүзқҖдҪ жқҘеӯҰд№ !





