数据迁移是DBA的日常工作,对于相应的方法、命令等,相信很多人早已了如指掌。圆满的数据迁移流程不单单指将数据从数据库A备份恢复到数据库B,而且要保证迁移前后数据的完整与服务的可用性。
近日,在给客户做了单机到集群的数据迁移后,发现集群的在线重做日志切换频繁,进而产生了大量的归档日志,对服务器造成了不小的压力。本文是对上述问题的分析处理过程。
在迁移完成后,需要对集群进行一段时间的深度观察。通过v$archived_log视图,分析数据库历史的归档情况,可以发现整个库的业务活动情况。
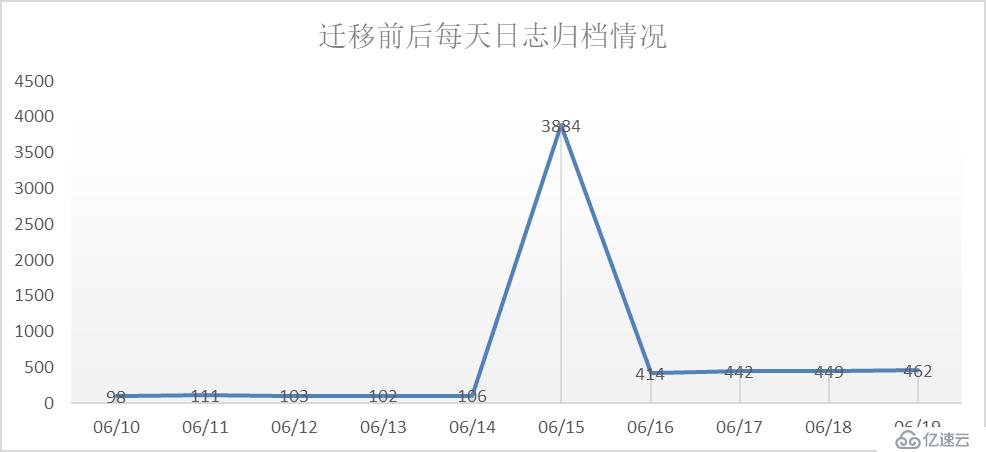
观察上图,不难发现迁移(6月15日)前后是一个明显得变化点,每天日志归档频率由原来的100多次变成400多次。这种情况要么是迁入的系统业务量确实很大,要么是迁入的数据库用户配置有问题。
经过与新迁入系统的运维人员沟通确认,该系统的使用人数虽然多,但都是以查询类的动作偏多,不应该带来这么大量的日志。因为集群中还有其它系统,不能直接判断是新系统的问题。假设运维所说情况属实,那么问题的关键点就是要找到产生大量日志的操作语句,进而找到对应的应用,再确认归档情况是否正常。
日志归档频繁,说明在线重做日志切换频繁,一般是由于产生了大量的redo。这里通过awr检查redo的生成情况。
一天内日志归档的详细情况

这里选择6月18日上午10点到11点间集群2节点的awr报告
节点1:
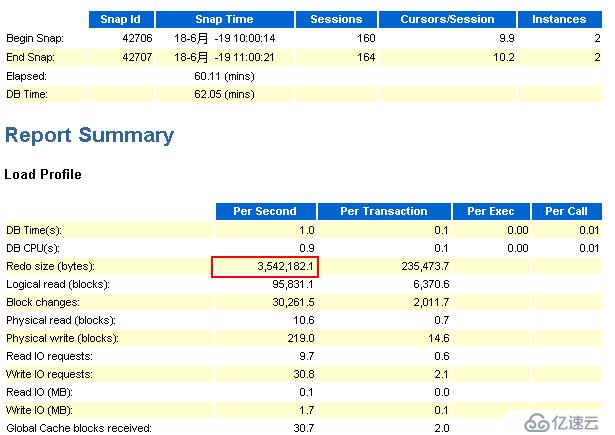
观察上图,可以看到在1小时内,节点1的redo的产生速率约为3.38MB/S,那么一小时就有约11.88GB。
节点2:
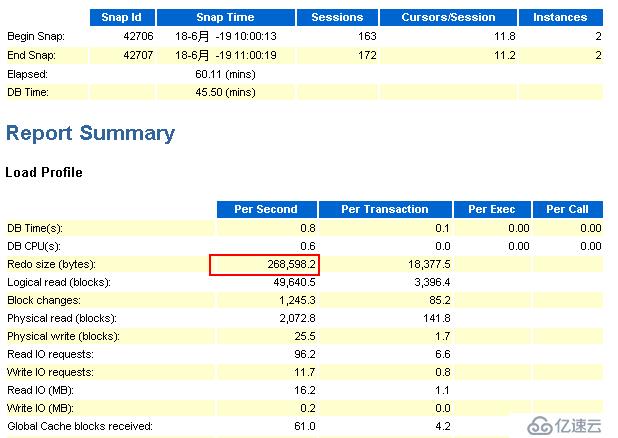
观察上图,可以看到在1小时内,节点2的redo的产生速率约为0.26MB/S,那么一小时就有约0.9GB。
通过查询v$archived_log视图,分类计算出10点到11点间所产生的归档日志大小约为12.3GB,这与根据awr报告推算出来的值12.78GB非常接近,可以说明以上两份awr报告的可参考性很高。
现在已经确认是归档频繁是由大量的redo引起的,那么就需要看在问题时间区间内,导致数据块变化的原因(sql),这个可以从awr报告的“Segments by DB Blocks Changes”部分可以找到答案:
节点1:
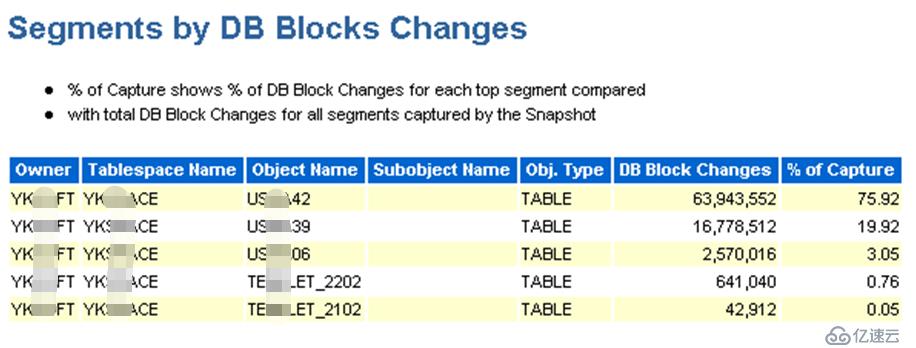
节点2:
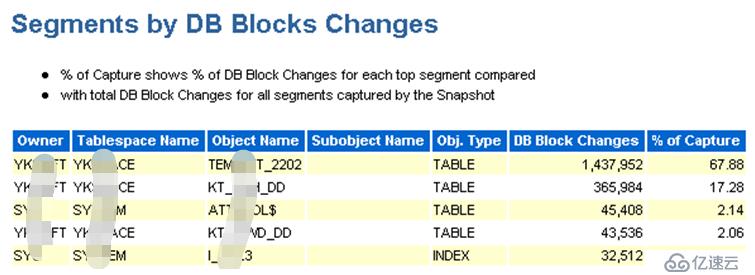
由上边2个截图可以发现,用户YK***FT名下的有3个表(US***42、US***39、US***06)的数据块被频繁的操作,而这个用户正是新迁入系统的数据库用户。
为了更进一步了解对该3个表做了哪些操作,可以在awr报告中分别搜索表名称,找出相关的sql语句。
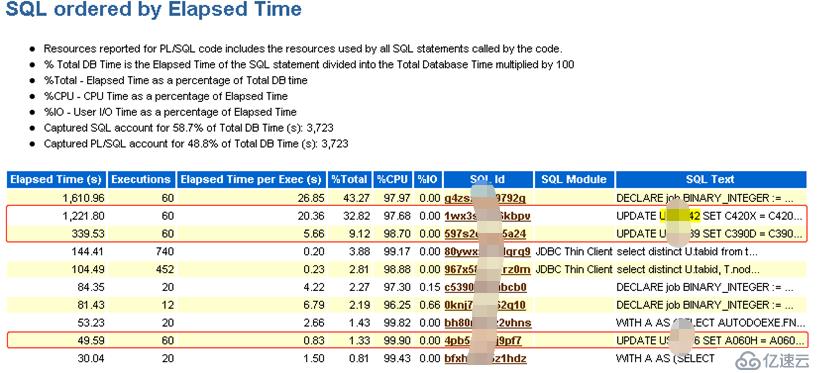
由上图可以看出,在1小时之内,对该3个表分别执行了60次update操作,具体的sql语句如下:

这里注意到一个数字60,看样子像是一个定时任务,首先想到的是job。经过查询,发现yk***ft用户下确实存在一个job,而且正好是每分钟执行一次!
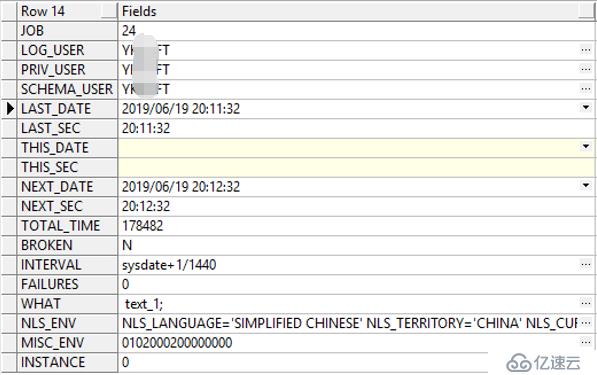
进一步查看job执行的存储过程发现正是上边的3条语句:
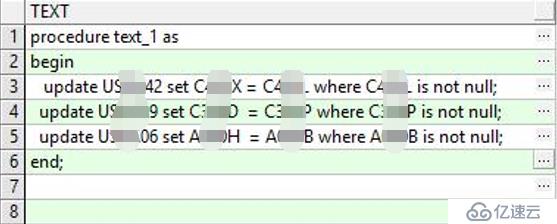
通过分析US***42、US***39、US***06这个3个表和update中的where语句,发现那3条update语句很有问题,符合where的数据量大,且只增不减,必须要调整。

根据前边找到的线索,跟运维人员确认job(24)的业务作用,得到的反馈是之前有个需求是定期把符合要求的字段A的值写到字段B,现在该需求已不再需要,可以删除。
禁用job
虽然业务确认可以删除,但为了保险起见,这里将job(24)禁用,通过调用dbms_job.broken完成。

观察redo
这里选择调整之后的6月20日上午10点到11点间集群2节点的awr报告
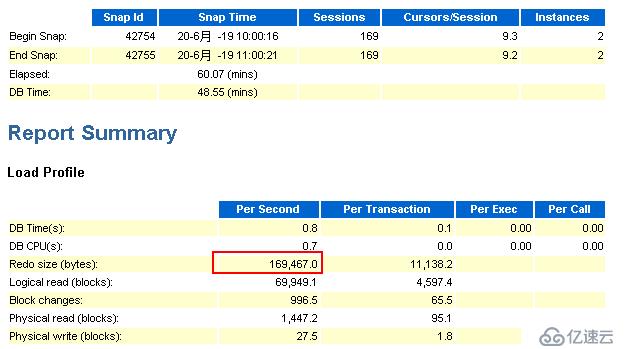
节点1:
节点2:
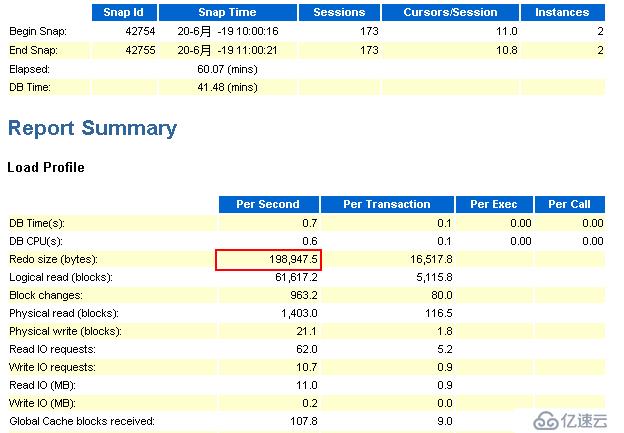
由上述节点1和节点2相同时间内的awr报告的来看,redo产生速率有了很大的降低。通过观察归档日志的生成情况,发现归档频率也降低了。
经过回顾整个问题的发现、分析和解决过程,可以发现其实并没有什么技术难点,问题的原因主要还是出在业务沟通上。在迁移之前,最好能够跟应用管理员确认清楚业务的特点,包括现有业务的压力情况、已发现的性能瓶颈、不再需要的各类数据库对象(索引、视图、存储过程、函数、触发器等),提前做好应对措施,保证数据迁移的圆满完成。

亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



