这篇文章主要介绍了Java如何获取网站图片,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
最近我的的朋友浏览一些网站,看到好看的图片,问我有没有办法不用手动一张一张保存图片!
我说用Jsoup丫!
测试网站

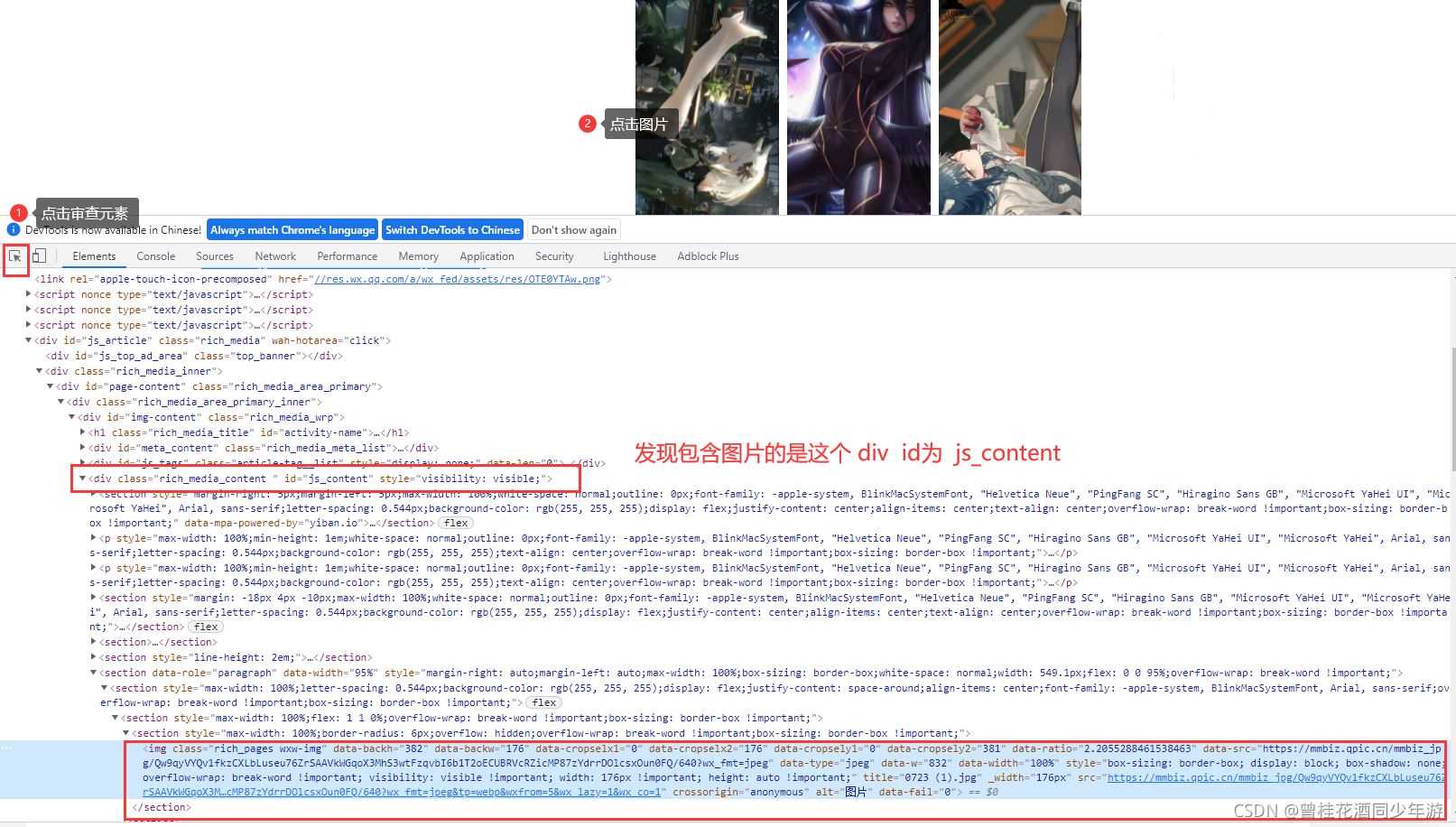
打开开发者模式(F12),找到对应图片的链接,在互联网中,每一张图片就是一个链接!
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.2</version>
</dependency>public class JsoupTest {
public static void main(String[] args) throws IOException {
// 爬虫的网站
String url="https://mp.weixin.qq.com/s/caU6d6ebpsLVJaf-7gMjtg";
// 获得网页的document对象
Document document = Jsoup.parse(new URL(url), 10000);
// 爬取含图片的代码部分
Element content = document.getElementById("js_content");
// 获取img标签代码 这是个集合
Elements imgs = content.getElementsByTag("img");
// 命名图片的id
int id=0;
for (Element img : imgs) {
// 获取具体的图片
String pic = img.attr("data-src");
URL target = new URL(pic);
// 获取连接对象
URLConnection urlConnection = target.openConnection();
// 获取输入流,用来读取图片信息
InputStream inputStream = urlConnection.getInputStream();
// 获取输出流 输出地址+文件名
id++;
FileOutputStream fileOutputStream = new FileOutputStream("E:\\JsoupPic\\" + id + ".png");
int len=0;
// 设置一个缓存区
byte[] buffer = new byte[1024 * 1024];
// 写出图片到E:\JsoupPic中, 输入流读数据到缓冲区中,并赋给len
while ((len=inputStream.read(buffer))>0){
// 参数一:图片数据 参数二:起始长度 参数三:终止长度
fileOutputStream.write(buffer, 0, len);
}
System.out.println(id+".png下载完毕");
// 关闭输入输出流 最后创建先关闭
fileOutputStream.close();
inputStream.close();
}
}
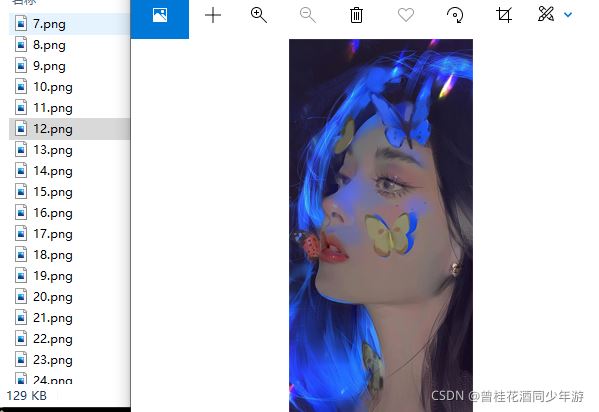
}成果:
感谢你能够认真阅读完这篇文章,希望小编分享的“Java如何获取网站图片”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



