【1】搭建HA高可用hadoop-2.3(规划+环境准备)
【2】搭建HA高可用hadoop-2.3(安装zookeeper)
【3】搭建HA高可用hadoop-2.3(部署配置hadoop--cdh6.1.0)
【4】搭建HA高可用hadoop-2.3(部署配置HBase)
安装部署hadoop
(1)安装hadoop
master1、master2、slave1、slave2、slave3
#cd /opt/ #tar xf hadoop-2.3.0-cdh6.1.0.tar.gz #ln -s ln -s hadoop-2.3.0-cdh6.1.0 hadoop
(2)添加hadoop环境变量
master1、master2、slave1、slave2、slave3
#cat >> /etc/profile <<EOF export HADOOP_HOME=/opt/hadoop export PATH=$PATH:$HADOOP_HOME/bin EOF #source /etc/profile
(3)配置hadoop
主要配置文件 (hadoop-2.3.0-cdh6.1.0 /etc/hadoop/) | 格式 | 作用 |
| hadoop-env.sh | bash脚本 | hadoop需要的环境变量 |
| core-site.xml | xml | hadoop的core的配置项 |
| hdfs-site.xml | xml | hdfs的守护进程配置,包括namenode、datanode |
| slaves | 纯文本 | datanode的节点列表(每行一个) |
| mapred-env.sh | bash脚本 | mapreduce需要的环境变量 |
| mapre-site.xml | xml | mapreduce的守护进程配置 |
| yarn-env.sh | bash脚本 | yarn需要的环境变量 |
| yarn-site.xml | xml | yarn的配置项 |
以下1-8的配置,所有机器都相同,可先配置一台,将配置统一copy到另外几台机器。
master1、master2、slave1、slave2、slave3
1:配置hadoop-env.sh
cat >> hadoop-env.sh <<EOF export JAVA_HOME=/usr/java/jdk1.8.0_60 export HADOOP_HOME=/opt/hadoop-2.3.0-cdh6.1.0 EOF
2:配置core-site.xml
#mkdir -p /data/hadoop/tmp #vim core-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <!--填写hdfs集群名,因为是HA,两个namenode--> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <property> <!-- hadoop很多路径都依赖他,namenode节点该目录不可以删除,否则要重新格式化--> <name>hadoop.tmp.dir</name> <value>/data/hadoop/tmp</value> </property> <property> <!--zookeeper集群的地址--> <name>ha.zookeeper.quorum</name> <value>master1:2181,master2:2181,slave1:2181,slave2:2181,slave3:2181</value> </property> </configuration>
3:配置hdfs-site.xml
#mkdir -p /data/hadoop/dfs/{namenode,datanode}
#mkdir -p /data/hadoop/ha/journal
#vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--hdfs-site.xml-->
<configuration>
<property>
<!--设置为true,否则一些命令无法使用如:webhdfs的LISTSTATUS-->
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<!--数据三副本-->
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<!--namenode的数据目录,存储集群元数据-->
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop/dfs/namenode</value>
</property>
<property>
<!--datenode的数据目录-->
<name>dfs.datanode.data.dir</name>
<value>file:/data/hadoop/dfs/datanode</value>
</property>
<property>
<!--可选,关闭权限带来一些不必要的麻烦-->
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<!--可选,关闭权限带来一些不必要的麻烦-->
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!--HA配置-->
<property>
<!--设置集群的逻辑名-->
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<!--hdfs集群中的namenode节点逻辑名-->
<name>dfs.ha.namenodes.mycluster</name>
<value>namenode1,namenode2</value>
</property>
<property>
<!--hdfs namenode逻辑名中RPC配置,rpc简单理解为序列化文件上传输出文件要用到-->
<name>dfs.namenode.rpc-address.mycluster.namenode1</name>
<value>master1:9000</value>
</property>
<property>
<!--hdfs namenode逻辑名中RPC配置,rpc简单理解为序列化文件上传输出文件要用到-->
<name>dfs.namenode.rpc-address.mycluster.namenode2</name>
<value>master2:9000</value>
</property>
<property>
<!--配置hadoop页面访问端口-->
<name>dfs.namenode.http-address.mycluster.namenode1</name>
<value>master1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.namenode2</name>
<value>master2:50070</value>
</property>
<property>
<!--建立与namenode的通信-->
<name>dfs.namenode.servicerpc-address.mycluster.namenode1</name>
<value>master1:53310</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.mycluster.namenode2</name>
<value>master2:53310</value>
</property>
<property>
<!--journalnode 共享文件集群-->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master1:8485;master2:8485;slave1:8485;slave2:8485;slave3:8485/mycluster</value>
</property>
<property>
<!--journalnode对namenode的进行共享设置-->
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop/ha/journal</value>
</property>
<property>
<!--设置故障处理类-->
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!--开启自动切换,namenode1 stanby后nn2或active-->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<!--zookeeper集群的地址-->
<name>ha.zookeeper.quorum</name>
<value>master1:2181,master2:2181,slave1:2181,slave2:2181,slave3:2181</value>
</property>
<property>
<!--使用ssh方式进行故障切换-->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<!--ssh通信密码通信位置-->
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
</configuration>4:配置mapred-env.sh
cat >> mapred-env.sh <<EOF #heqinqin configure export JAVA_HOME=/usr/java/jdk1.8.0_60 EOF
5:配置mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <name>mapreduce.framework.name</name> <value>yarn<value> </configuration>
6:配置yarn-env.sh
cat >> yarn-env.sh <<EOF #heqinqin configure export JAVA_HOME=/usr/java/jdk1.8.0_60 EOF
7:配置yarn-site.xml
#mkdir -p /data/hadoop/yarn/local #mkdir -p /data/hadoop/logs #chown -R hadoop /data/hadoop #vim yarn-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!--####################yarn-site.xml#########################--> <configuration> <property> <!--rm失联后重新链接的时间--> <name>yarn.resourcemanager.connect.retry-interval.ms</name> <value>2000</value> </property> <property> <!--开启resource manager HA,默认为false--> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <!--开启故障自动切换--> <name>yarn.resourcemanager.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <!--配置resource manager --> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.ha.id</name> <value>rm1</value> <description>If we want to launch more than one RM in single node, we need this configuration</description> </property> <property> <!--开启自动恢复功能--> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <!--配置与zookeeper的连接地址--> <name>yarn.resourcemanager.zk-state-store.address</name> <value>localhost:2181</value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>localhost:2181</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarncluster</value> </property> <property> <!--schelduler失联等待连接时间--> <name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name> <value>5000</value> </property> <!--配置resourcemanager--> <!--配置rm1--> <property> <!--配置应用管理端口--> <name>yarn.resourcemanager.address.rm1</name> <value>master1:8032</value> </property> <property> <!--scheduler调度器组建的ipc端口--> <name>yarn.resourcemanager.scheduler.address.rm1</name> <value>master1:8030</value> </property> <property> <!--http服务端口--> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>master1:8088</value> </property> <property> <!--IPC端口--> <name>yarn.resourcemanager.resource-tracker.address.rm1</name> <value>master1:8031</value> </property> <property> <!--IPC端口--> <name>yarn.resourcemanager.admin.address.rm1</name> <value>master1:8033</value> </property> <property> <name>yarn.resourcemanager.ha.admin.address.rm1</name> <value>master1:8035</value> </property> <!--配置rm2--> <property> <!--application 管理端口--> <name>yarn.resourcemanager.address.rm2</name> <value>master2:8032</value> </property> <property> <!--scheduler调度器端口--> <name>yarn.resourcemanager.scheduler.address.rm2</name> <value>master2:8030</value> </property> <property> <!--http服务端口--> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>master2:8088</value> </property> <property> <!--ipc端口--> <name>yarn.resourcemanager.resource-tracker.address.rm2</name> <value>master2:8031</value> </property> <property> <!--ipc端口--> <name>yarn.resourcemanager.admin.address.rm2</name> <value>master2:8033</value> </property> <property> <name>yarn.resourcemanager.ha.admin.address.rm2</name> <value>master2:8035</value> </property> <!--配置nodemanager--> <property> <!--配置localizer ipc端口--> <description>Address where the localizer IPC is.</description> <name>yarn.nodemanager.localizer.address</name> <value>0.0.0.0:8040</value> </property> <property> <!--nodemanager http访问端口--> <description>NM Webapp address.</description> <name>yarn.nodemanager.webapp.address</name> <value>0.0.0.0:8042</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.nodemanager.local-dirs</name> <value>/data/hadoop/yarn/local</value> </property> <property> <name>yarn.nodemanager.log-dirs</name> <value>/data/hadoop/logs</value> </property> <property> <name>mapreduce.shuffle.port</name> <value>8050</value> </property> <!--故障处理类--> <property> <name>yarn.client.failover-proxy-provider</name> <value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value> </property> </configuration>
8:配置slaves
cat >> slaves <<EOF slave1 slave2 slave3 EOF
配置完毕
启动集群
(1)格式化命名空间
master1
#/opt/hadoop/bin/hdfs zkfc -formatZK
(2)启动journalnode
master1、master2、slave1、slave2、slave3 (集群内随意算则奇数台机器作为journalnode,三台也可以)
#/opt/hadoop/sbin/hadoop-daemon.sh start journalnode
(3)master1节点格式化,并启动namenode
master1
格式化namenode的目录
#/opt/hadoop/bin/hadoop namenode -format mycluster
启动namenode
#/opt/hadoop/sbin/hadoop-daemon.sh start namenode
(4)master2节点同步master1的格式化目录,并启动namenode
master2
从master1将格式化的目录同步过来
#/opt/hadoop/bin/hdfs namenode -bootstrapStandby
启动namenode
#/opt/hadoop/sbin/hadoop-daemon.sh start namenode
(5)master节点启动zkfs
master1、master2
#/opt/hadoop/sbin/hadoop-daemon.sh start zkfc
(6)slave节点启动datanode
slave1、slave2、slave3
#/opt/hadoop/sbin/hadoop-daemon.sh start datanode
(7)master节点启动yarn
master1
#/opt/hadoop/sbin/start-yarn.sh
(8)master节点启动historyserver
master1
./mr-jobhistory-daemon.sh start historyserver
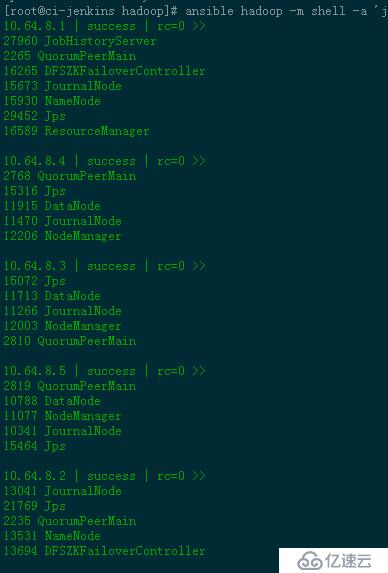
集群已启动。在各服务器执行jps查看,两个master上各一个namenode,形成namenode高可用,实现故障自动切换。
【1】搭建HA高可用hadoop-2.3(规划+环境准备)
【2】搭建HA高可用hadoop-2.3(安装zookeeper)
【3】搭建HA高可用hadoop-2.3(部署配置hadoop--cdh6.1.0)
【4】搭建HA高可用hadoop-2.3(部署配置HBase)
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





