这篇文章主要讲解了“MySQL索引怎么实现分页探索”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“MySQL索引怎么实现分页探索”吧!
表结构
CREATE TABLE `demo` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '职位',
`card_num` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '工卡号',
PRIMARY KEY (`id`),
KEY `index_union` (`name`,`age`,`position`)
) ENGINE=InnoDB AUTO_INCREMENT=450003 DEFAULT CHARSET=utf8;
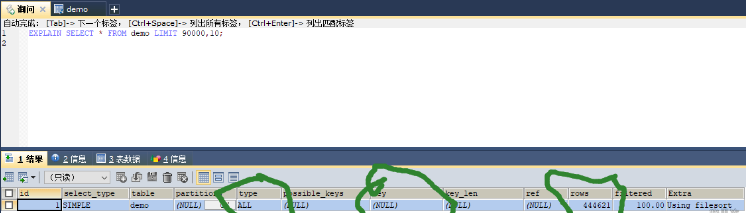
450003条数据limit分页执行情况
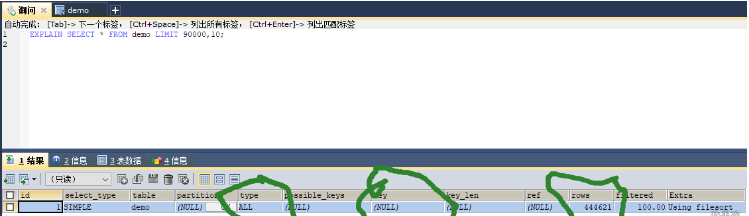
像select * from demo limit 90000,10;考虑到回表,所以mysql干脆选择全表扫描。
mysql不是直接从第90000行开始计算10条,而是从第一个叶子节点开始计数,计算90010行。
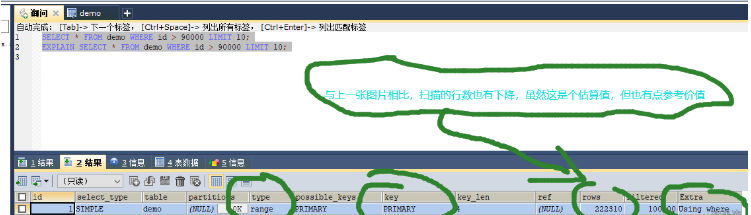
针对上图,当id是连续自增的时候,可以用主键筛选出id=90000之后的数据。因为主键的索引是B+树结构,本身就是有序的。

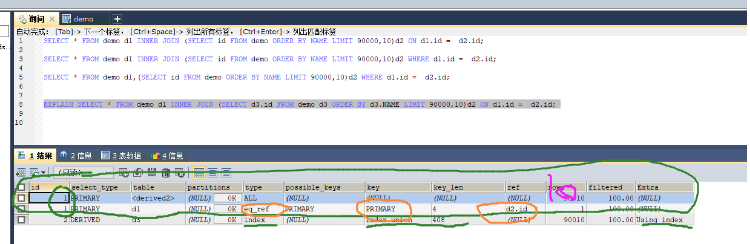
先按照name排序,然后再从第90000行起找10行,虽然name是索引,但select的列在index_union索引树上并没有保存。
所以还会涉及到回表,于是mysql直接选择扫主键索引树的叶子结点,先将40多万数据根据name排好序,然后计算90000行+10行。
优化方法:利用子查询解决最消耗时间的排序和回表问题,联合索引树种保存有主键id,order by name的话可以将name、age、position整个索引充分使用因为确定了最左列的排序,其余的俩列age、和position其实也是
排好序的了,通过Extra字段也可以是使用了索引树做排序。
最外层的查询是根据主键来关联的,所以几乎可以忽略。10+10 因为id是主键,可以直接拿临时表10条数据去扫。
感谢各位的阅读,以上就是“MySQL索引怎么实现分页探索”的内容了,经过本文的学习后,相信大家对MySQL索引怎么实现分页探索这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



