这期内容当中小编将会给大家带来有关MySQL数据优化中的多层索引是怎么样的,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
环境:Jupyter
import numpy as np
import pandas as pd
a=pd.DataFrame(np.random.random(size=(4,4)),index=[['上半年','上半年','下半年','下半年'],
['一季度','二季度','三季度','四季度']],
columns=[['蔬菜','蔬菜','肉类','肉类'],['胡萝卜','白菜','牛肉','猪肉']])
display(a)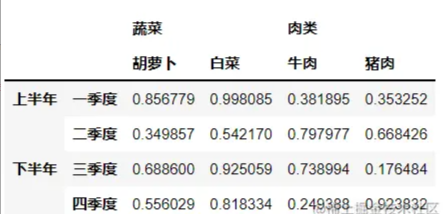
import numpy as np
import pandas as pd
a=pd.DataFrame(np.random.random(size=(4,4)),index=[['上半年','上半年','下半年','下半年'],
['一季度','二季度','三季度','四季度']],
columns=[['蔬菜','蔬菜','肉类','肉类'],['胡萝卜','白菜','牛肉','猪肉']])
a.index.names=['年度','季度']
a.columns.names=['大类','小类']
display(a)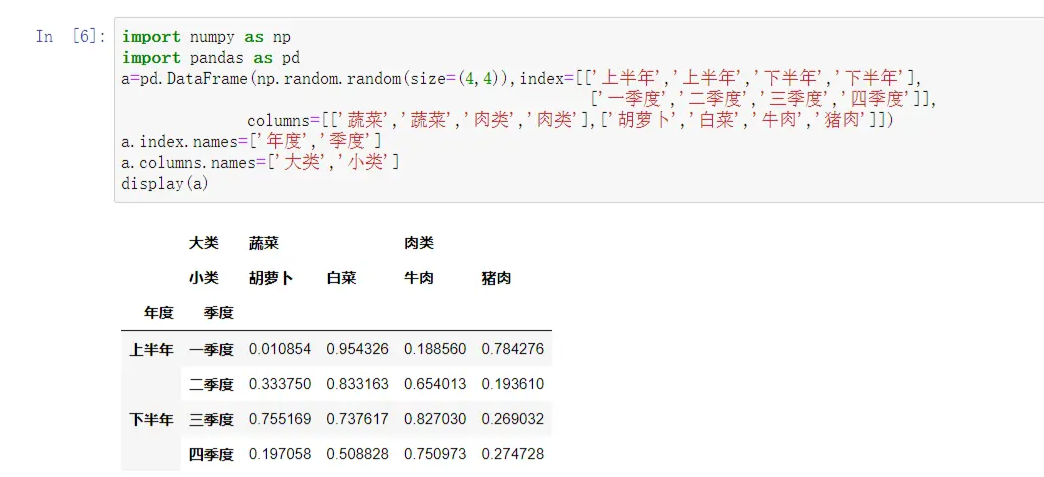
import numpy as np
import pandas as pd
index=pd.MultiIndex.from_arrays([['上半年','上半年','下半年','下半年'],['一季度','二季度','三季度','四季度']])
columns=pd.MultiIndex.from_tuples([('蔬菜','胡萝卜'),('蔬菜','白菜'),('肉类','牛肉'),('肉类','猪肉')])
a=pd.DataFrame(np.random.random(size=(4,4)),index=index,columns=columns)
display(a)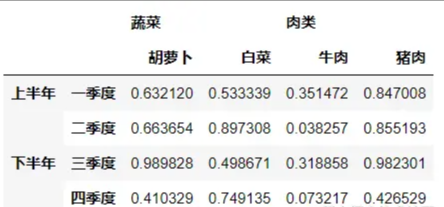
from_product() 局限性较大
import pandas as pd
index = pd.MultiIndex.from_product([['上半年','下半年'],['蔬菜','肉类']])
a=pd.DataFrame(np.random.random(size=(4,4)),index=index)
display(a)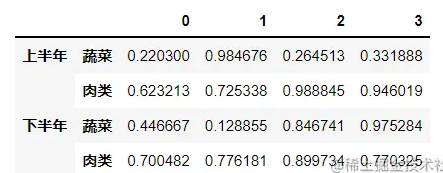
import pandas as pd
a=pd.Series([1,2,3,4],index=[['a','a','b','b'],['c','d','e','f']])
print(a)
print('---------------------')
print(a.loc['a'])
print('---------------------')
print(a.loc['a','c'])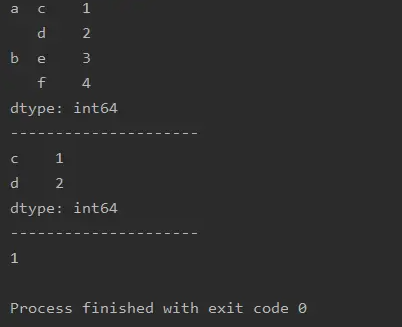
import pandas as pd
a=pd.Series([1,2,3,4],index=[['a','a','b','b'],['c','d','e','f']])
print(a)
print('---------------------')
print(a.iloc[0])
print('---------------------')
print(a.loc['a':'b'])
print('---------------------')
print(a.iloc[0:2])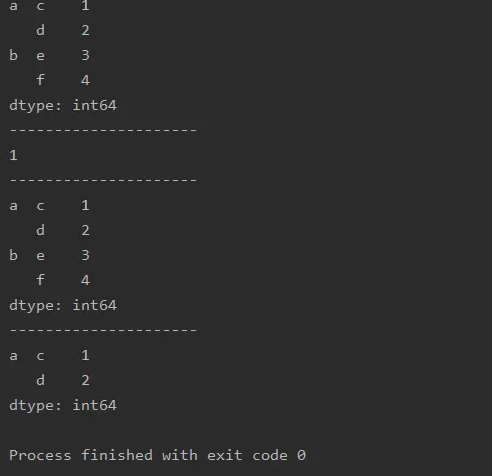
import numpy as np
import pandas as pd
a=pd.DataFrame(np.random.random(size=(4,4)),index=[['上半年','上半年','下半年','下半年'],
['一季度','二季度','三季度','四季度']],
columns=[['蔬菜','蔬菜','肉类','肉类'],['胡萝卜','白菜','牛肉','猪肉']])
print(a)
print('--------------------')
print(a.loc['上半年','二季度'])
print('--------------------')
print(a.iloc[0])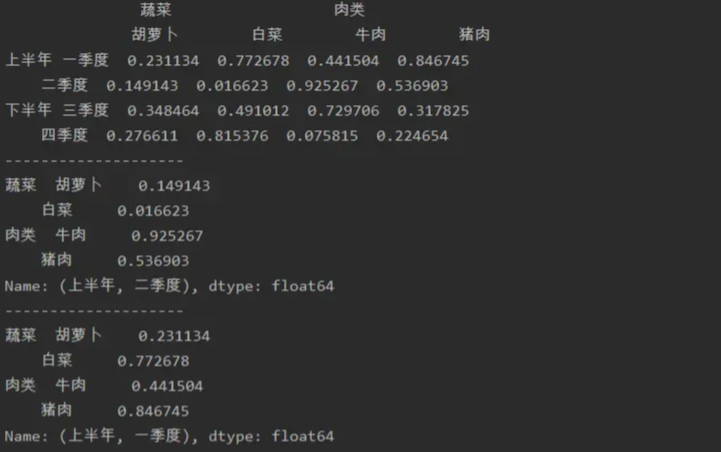
swaplevel( )
import numpy as np
import pandas as pd
a=pd.DataFrame(np.random.random(size=(4,4)),index=[['2021','2021','2022','2022'],
['一季度','二季度','三季度','四季度']],
columns=[['蔬菜','蔬菜','肉类','肉类'],['胡萝卜','白菜','牛肉','猪肉']])
a.index.names=['年度','季度']
print(a)
print('--------------------')
print(a.swaplevel('年度','季度'))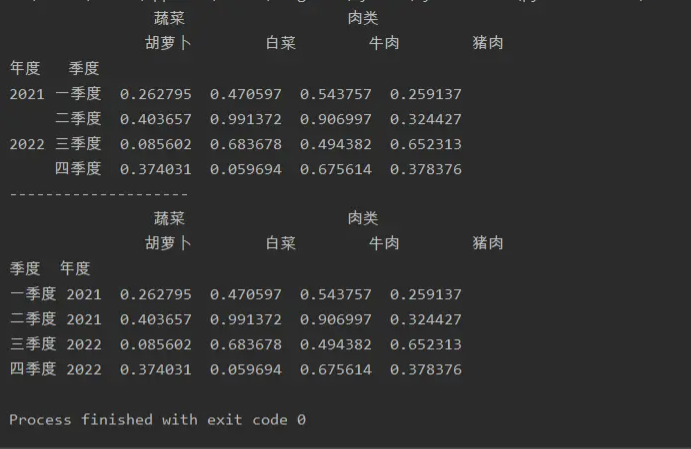
sort_index( )
level:指定根据哪一层进行排序,默认为最层
inplace:是否修改原数据。默认为False
import numpy as np
import pandas as pd
a=pd.DataFrame(np.random.random(size=(4,4)),index=[['2021','2021','2022','2022'],
[1,3,2,4]],
columns=[['蔬菜','蔬菜','肉类','肉类'],['胡萝卜','白菜','牛肉','猪肉']])
a.index.names=['年度','季度']
print(a)
print('--------------------')
print(a.sort_index())
print('--------------------')
print(a.sort_index(level=1))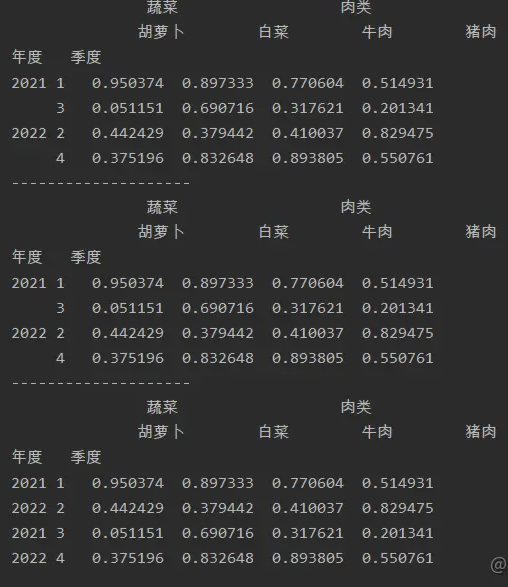
stack( )
将指定层级的列转换成行
import numpy as np
import pandas as pd
a=pd.DataFrame(np.random.random(size=(4,4)),index=[['2021','2021','2022','2022'],
[1,3,2,4]],
columns=[['蔬菜','蔬菜','肉类','肉类'],['胡萝卜','胡萝卜','牛肉','牛肉']])
print(a)
print('--------------------')
print(a.stack(0))
print('--------------------')
print(a.stack(-1))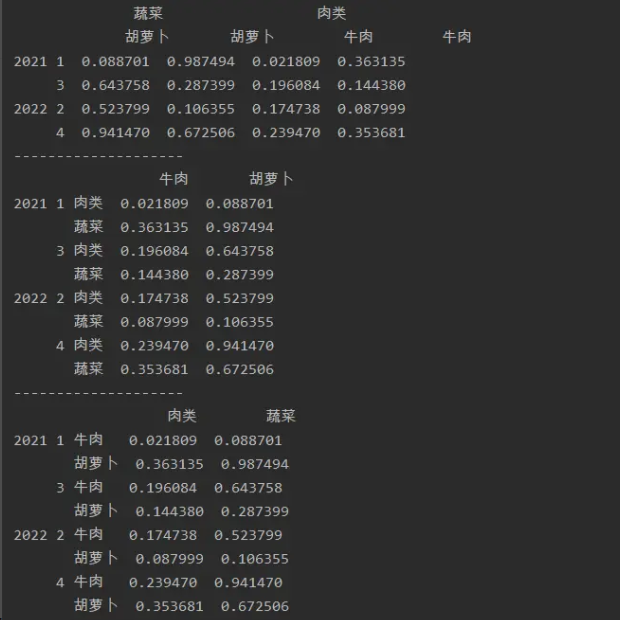
unstack( )
将指定层级的行转换成列
fill_value:指定填充值。
import numpy as np
import pandas as pd
a=pd.DataFrame(np.random.random(size=(4,4)),index=[['2021','2021','2022','2022'],
[1,3,2,4]],
columns=[['蔬菜','蔬菜','肉类','肉类'],['胡萝卜','胡萝卜','牛肉','牛肉']])
print(a)
print('--------------------')
a=a.stack(0)
print(a)
print('--------------------')
print(a.unstack(-1))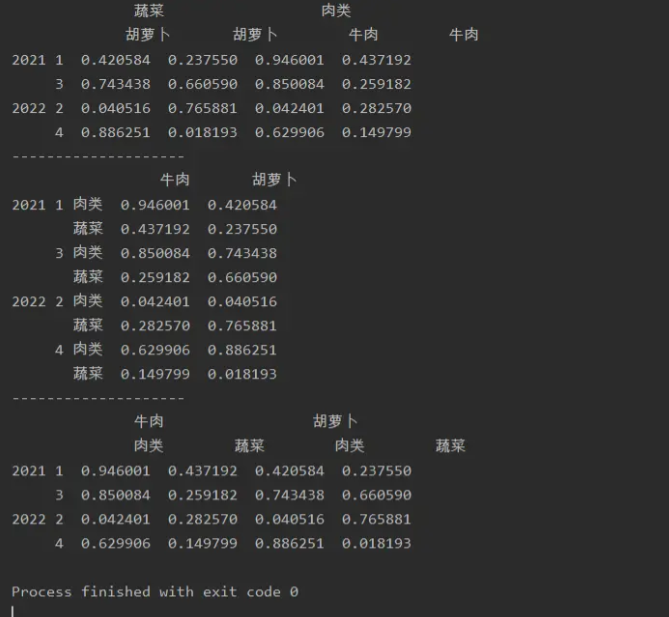
import numpy as np
import pandas as pd
a=pd.DataFrame(np.random.random(size=(4,4)),index=[['2021','2021','2022','2022'],
[1,3,2,4]],
columns=[['蔬菜','蔬菜','肉类','肉类'],['胡萝卜','胡萝卜','牛肉','牛肉']])
print(a)
print('--------------------')
a=a.stack(0)
print(a)
print('--------------------')
print(a.unstack(0,fill_value='0'))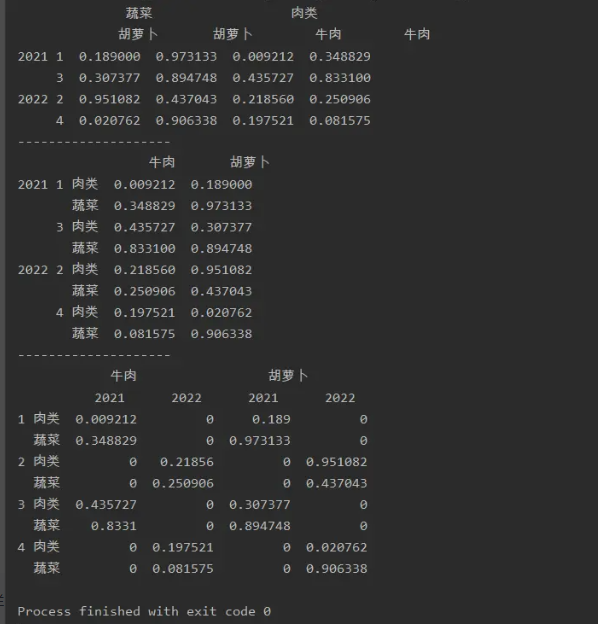
上述就是小编为大家分享的MySQL数据优化中的多层索引是怎么样的了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



