如何分析python numpy库,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
numpy是一个开源的python科学计算扩展库,主要用来处理任意维度数组和矩阵。
相同的任务,使用numpy比直接用python的基本数据结构更加简单高效。
它的功能:
包含一个强大的N维数组对象Ndarray
广播功能函数
整合C/C++代码的工具
线性代数、傅里叶变换、随机数生成等功能
numpy是scipy,pandas等数据处理或科学计算库的基础

虽说别名可以省略或者更改,但尽量使用上述约定的别名
n维数组,它是一个相同数据类型的集合,以0为下标开始进行集合中元素的索引。
我们知道,python有列表和数组此类的数据结构。
列表:数据类型可以不同(如[3, 2.4 ,‘a' ,“abc”]),数据是有序的
数组:数据类型相同(如[1,2,3,4])
集合: (如{2,4,3,5,7})数据是无序的
观察下列两组操作,其功能都是一样的。
import numpy as np
def pysum():
a = [1, 2, 3, 4]
b = [5, 6, 7, 8]
c = []
for i in range(len(a)):
c.append(a[i]**2+b[i]**3)
return c
def numpysum():
a = np.array([1, 2, 3, 4])
b = np.array([5, 6, 7, 8])
c = a**2+b**3
return c
print("使用列表运算的结果是:", pysum())
print("使用Numpy运算的结果是:", numpysum())运行结果:
使用列表运算的结果是: [126, 220, 352, 528]
使用Numpy运算的结果是: [126 220 352 528]
但是很明显:
numpy的数组对象可以去掉元素建运算所需要的循环,使一维向量更像单个数据
numpy通过设立专门的数组对象,经过优化,运算速度也相应提升
通常情况下,在科学运算中,一个维度所有数据的类型往往相同,这时,使用数组对象采用相同的数据类型,有助于节省运算时间和存储空间
实际的数据
描述这些数据的元数据(数据维度、数据类型等)


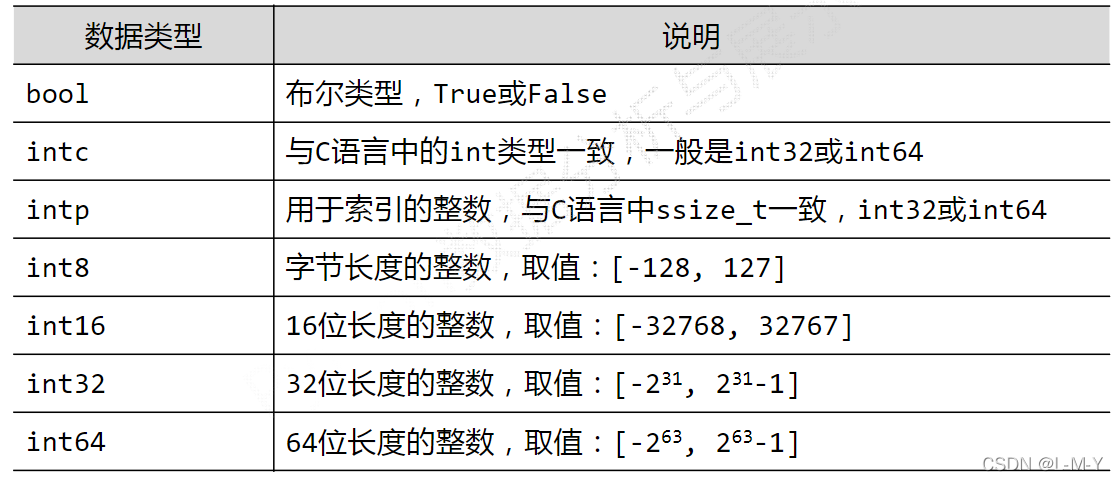
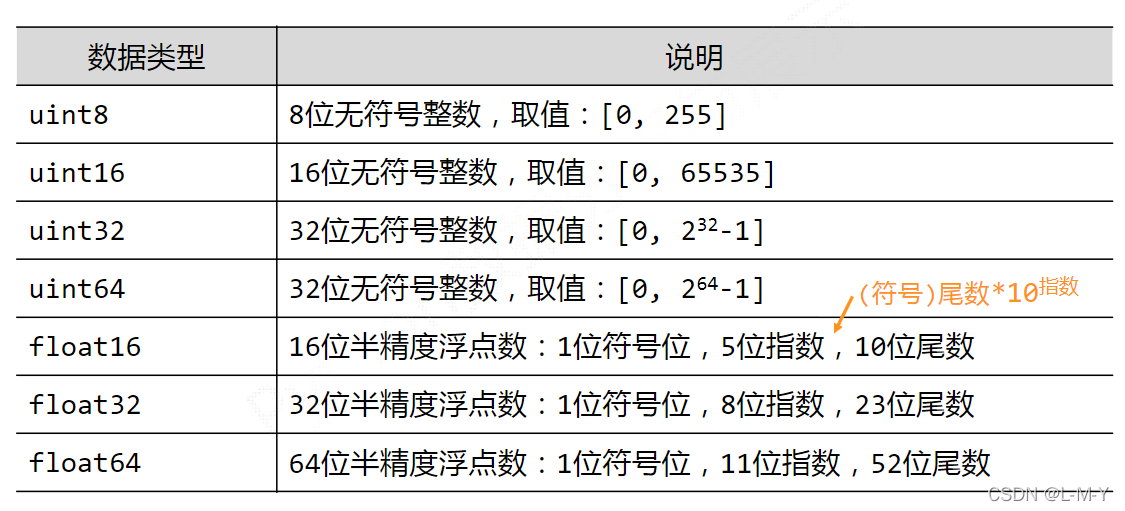

当np.array()不指定dtype时,numpy将根据数据情况关联一个dtype类型
ndarray支持多种数据类型的原因
python基本语法只支持整数、浮点数和复数3种类型
科学计算涉及数据较多,对存储和性能都有较高要求
对元素类型精细定义,有助于numpy合理使用存储空间并优化性能
对元素类型精细定义,有助于程序员对程序规模有合理评估
import numpy as np
x = np.array([[1, 0], [2, 0], [3, 1]], np.int32)
print(x)
print(x.dtype)程序输出:
[[1 0]
[2 0]
[3 1]]
int32







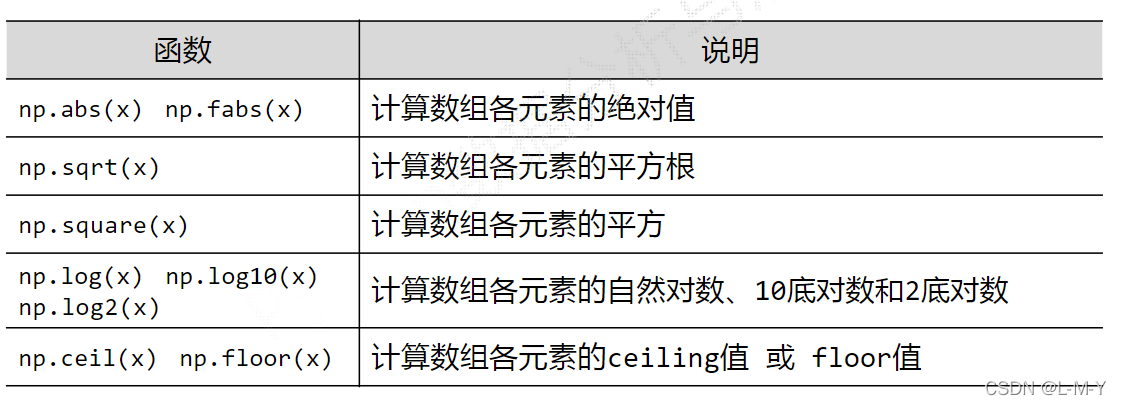
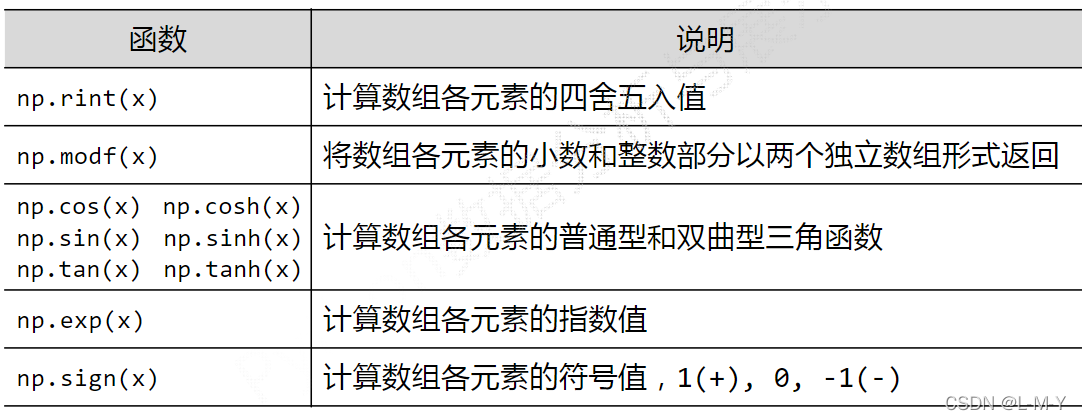

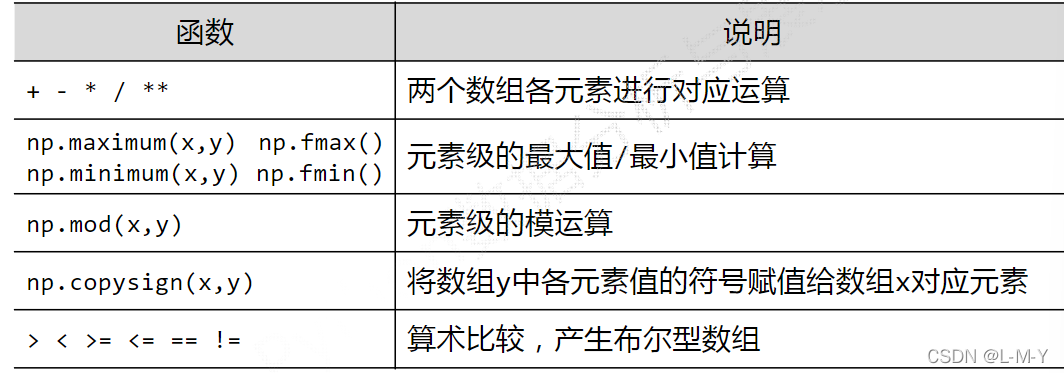

索引:获取数组中特定位置元素的过程
切片:获取数组元素子集的过程











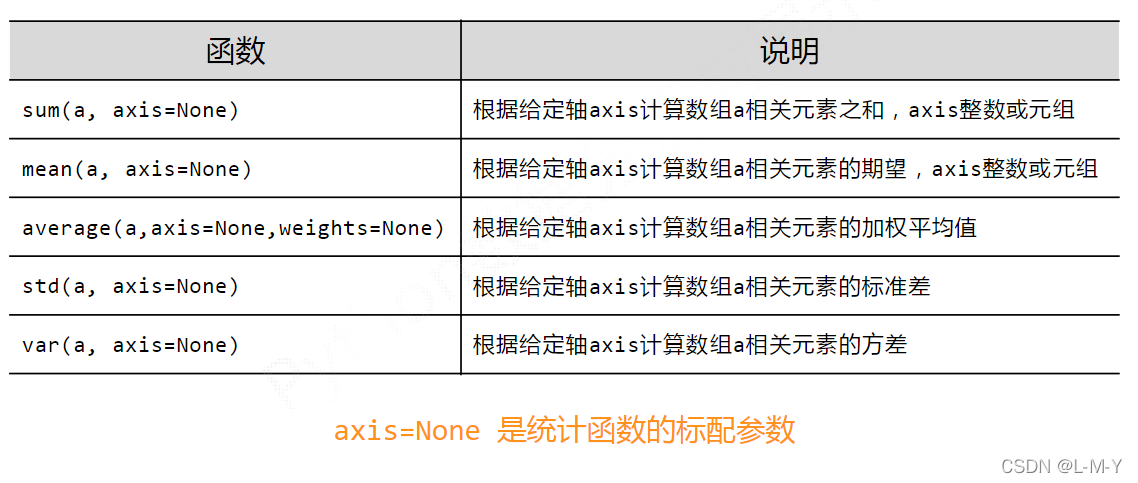

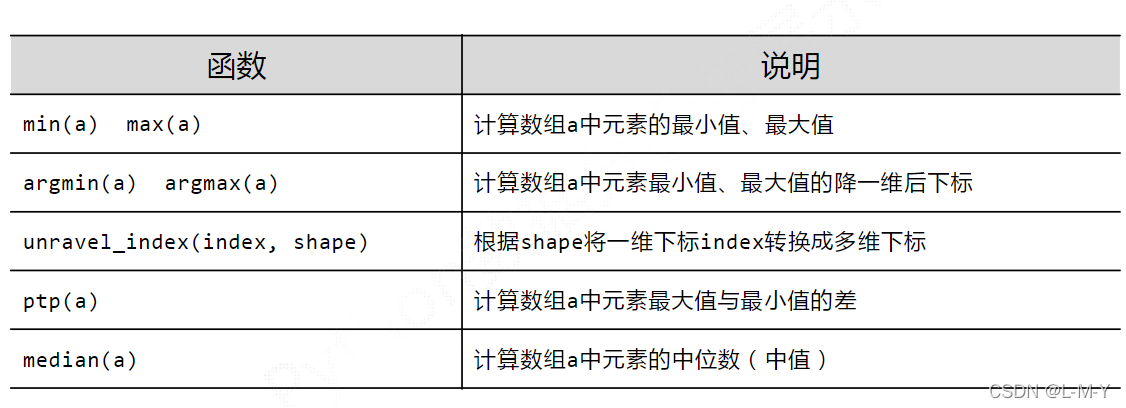





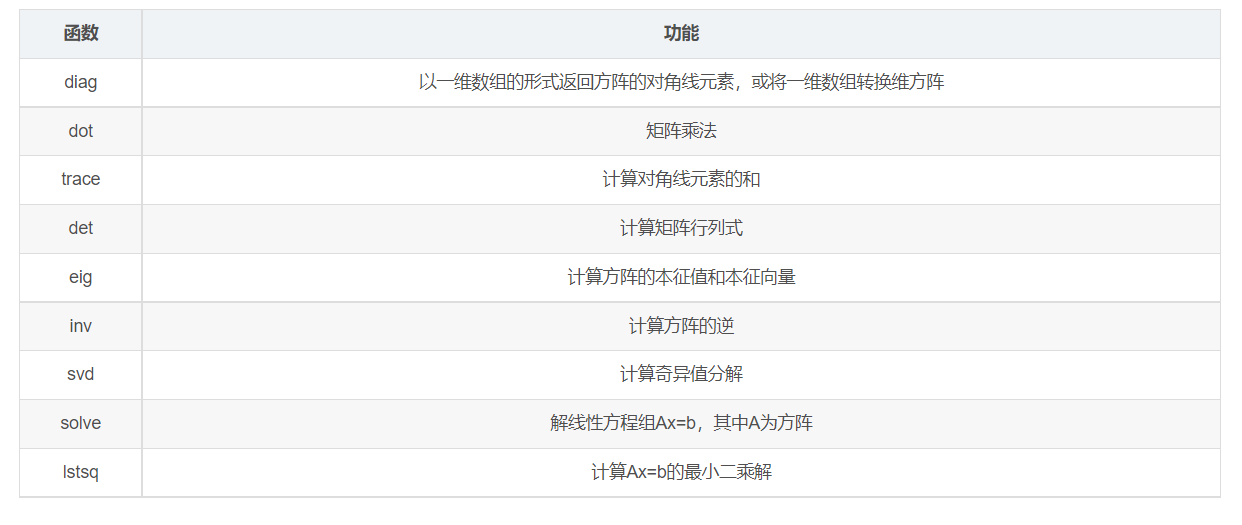
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



