Python中的lxml模块指的是什么,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
对html或xml形式的文本提取特定的内容,就需要我们掌握lxml模块的使用和xpath语法。
lxml模块可以利用xPath规则语法,来快速的定位HEML \ XML 文档中特定元素以及获取节点信息(文本内容、属性值);XPath (XML Path Language)是一门HTML\XML 文档中查找信息的语言,可用来在HTML|XML文档中对元素和属性进行遍历。
提取xml、html的数据需要lxml模块和xpath语法配合使用;
在谷歌浏览器中对当前页面测试xpath语法规则。
谷歌浏览器xpath helper插件的安装和使用
我们以windows为例进行xpath helper的安装。
xpath helper插件的安装:
1)、下载Chrome插件 XPath Helper
可以在Chrome应用商城进行下载,如果无法下载,也可以从下面的链接进行下载
2)、把文件的后缀名crx改为rar,然后解压到同名文件夹中;
3)、把解压后的文件夹拖入到已经开启开发者模式的chrome浏览器扩展程序界面;
学习xpath语法需要先了解xpath中的节点关系。
每个html、xml的标签我们都称之为节点,其中最顶层的节点称为根节点。我们以xml为例、html也是一样的。、


author 是 title的第一个兄弟节点。
1)、XPath 使用路径表达式来选取XML文档中的节点或者节点集。
2)、这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似;
3)、使用chrome插件选择标签时候,选中的标签会添加属性class=“xh-highlight”;

可以根据标签的属性值,下标等来获取特定的节点。
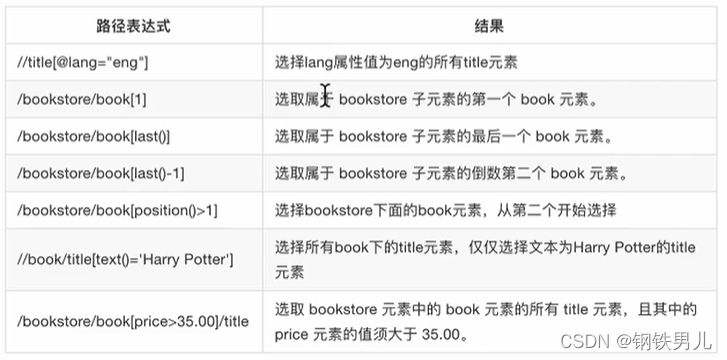
在xpath中,第一个元素的位置是1;
最后一个元素的位置是last();
倒数第二个是last() - 1;
可以同通配符来选取未知的html、xml的元素。

lxml模块是一个第三方模块,安装之后使用。
对发送请求获取的xml或html形式的响应内容进行提取。
pip install lxml
提取标签中的文本内容;
提取标签中的属性的值;
比如,提取a标签中href属性的值,获取url,进而继续发起请求。
1)、导入lxml的etree库
from lxml import etree
2)、利用etree.HTML,将html字符串(bytes类型或str类型)转化为Element对象,Element对象具有xpath的方法,返回结果的类别。
html = etree.HTML(text)
ret_list = html.xpath("xpath语法规则字符串")3)、xpath方法返回列表的三种情况
返回空列表:根据xpath语法规则字符串,没有定位到任何元素;
返回由字符串构成的列表:xpath字符串规则匹配的一定是文本内容或某属性的值;
返回由Element对象构成的列表:xpath规则字符串匹配的是标签,列表中的Element对象可以继续进行xpath;
import requests
from lxml import etree
class Tieba(object):
def __init__(self,name):
self.url = "https://tieba.baidu.com/f?ie=utf-8&kw={}".format(name)
self.headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'
}
def get_data(self,url):
response = requests.get(url,headers=self.headers)
with open("temp.html","wb") as f:
f.write(response.content)
return response.content
def parse_data(self,data):
# 创建element对象
data = data.decode().replace("<!--","").replace("-->","")
html =etree.HTML(data)
el_list = html.xpath('//li[@class="j_thread_list clearfix"]/div/div[2]/div[1]/div[1]/a')
#print(len(el_list))
data_list = []
for el in el_list:
temp = {}
temp['title'] = el.xpath("./text()")[0]
temp['link'] = 'http://tieba.baidu.com' + el.xpath("./@href")[0]
data_list.append(temp)
# 获取下一页url
try:
next_url = 'https:' + html.xpath('//a[contains(text(),"下一页"]/@href')[0]
except:
next_url = None
return data_list,next_url
def save_data(self,data_list):
for data in data_list:
print(data)
def run(self):
# url
# headers
next_url = self.url
while True:
# 发送请求,获取响应
data = self.get_data(self.url)
# 从响应中提取数据(数据和翻页用的url)
data_list,next_url = self.parse_data(data)
self.save_data(data_list)
print(next_url)
# 判断是否终结
if next_url == None:
break
if __name__ == '__main__':
tieba =Tieba("传智播客")
tieba.run()运行下边的代码,观察对比html的原字符串和打印输出的结果
from lxml import etree html_str = """<div<<ul> <li class="item-1"><a href="link1.html" rel="external nofollow" >first item</a></li> <li class="item-1"><a href="link2.html" rel="external nofollow" >second item</a></li> <li class="item-inactive"><a href="link3.html" rel="external nofollow" >third item</a></li> <li class="item-1"><a href="link4.html" rel="external nofollow" >fourth item</a></li> <li class="item=0"><a href="link5.html" rel="external nofollow" >fifth item</a> </ur></div> """ html = etree.HTML(html_str) handeled_html_str = etree.tostring(html).decode() print(handeled_html_str)
结论:
lxml.etree.HTML(html_str)可以自动补全标签;
lxml.etree.tostring 函数可以将转换位Element对象再转换回html字符串;
爬虫如果使用lxml来提取数据,应该以lxml.etree.tostring 的返回结果作为提取数据的依据;
看完上述内容,你们掌握Python中的lxml模块指的是什么的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





