Spark 官方网站使用如下简洁的语言描述了Spark
 我们可以从中提取出如下信息:
我们可以从中提取出如下信息:
Spark是一个引擎
快速
通用
Spark可以用来处理数据
数据是大规模的
Spark本身并不提供数据存储能力,它只是一个计算框架
它的快速体现在什么地方呢?
 如果处理的数据在内存中,运行MapReduce比hadoop要快100倍以上,要是数据在磁盘中,也比Hadoop快10倍以上。
如果处理的数据在内存中,运行MapReduce比hadoop要快100倍以上,要是数据在磁盘中,也比Hadoop快10倍以上。
为什么会快呢,Spark在处理数据的时候,使用了一个高级的执行引擎:DAG - 有向无环图 。以及内存计算。
易于使用:
可以使用scala、java、Python等语言快速的开发应用程序。Spark提供了超过80个操作来简单的构建并行应用。只需几行代码,就可以完成wordcount的计算。

通用性:
Spark 提供了大数据一栈式解决方案。包含了流计算、图计算、机器学习、SQL等。
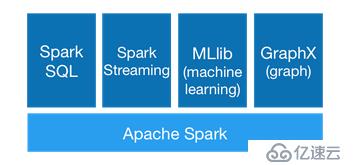
对于开发、维护、学习成本都是大大的降低。
运行在任何地方:
Spark可以运行在Hadoop的YARN、Mesos, standalone,或者运行在云上。
Spark 处理的数据,可以存储在HDFS, Cassandra, HBase,和S3等等。

Spark的发展非常快速,TimeLine如下
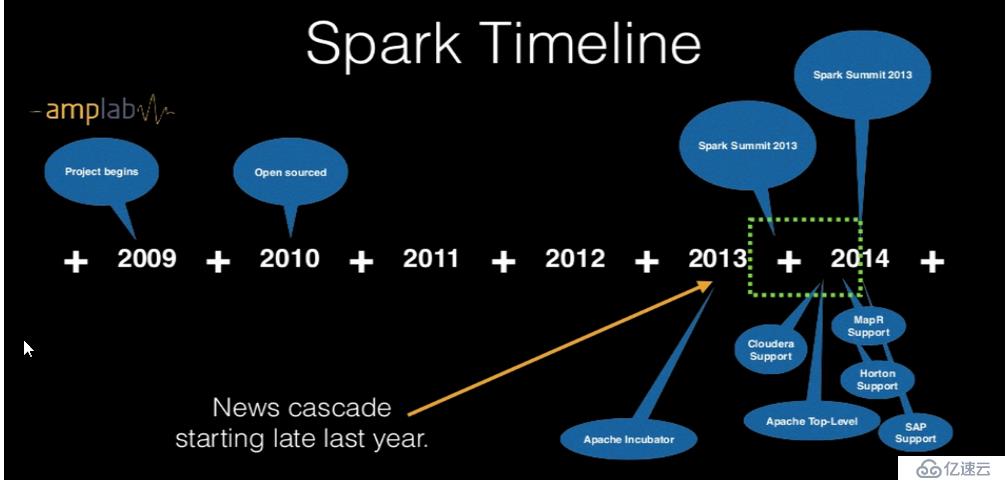
Spark进入Apache后,发展非常迅速。版本发布比较频繁。
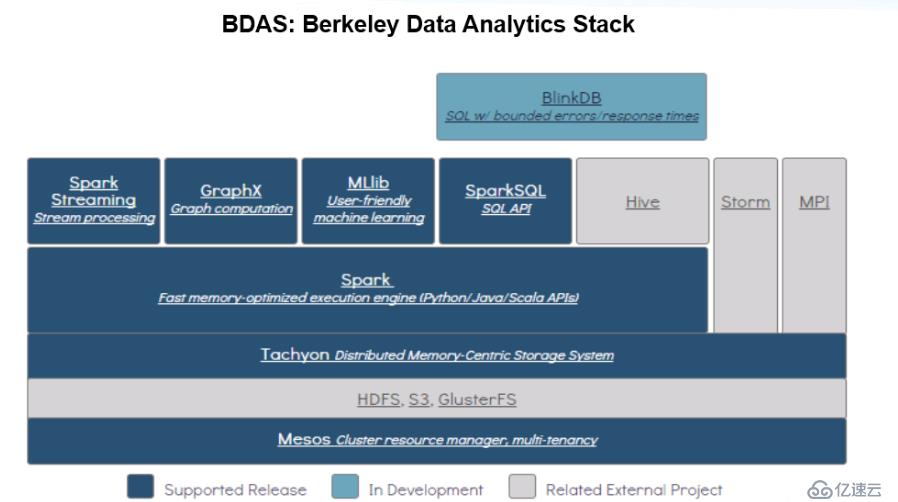
Spark的生态体系(BDAS,中文:伯克利分析栈)
MapReduce属于Hadoop生态体系之一,Spark则属于BDAS生态体系之一
Hadoop包含了MapReduce、HDFS、HBase、Hive、Zookeeper、Pig、Sqoop等
BDAS包含了Spark、Shark(相当于Hive)、BlinkDB、Spark Streaming(消息实时处理框架,类似Storm)等等
BDAS生态体系图:
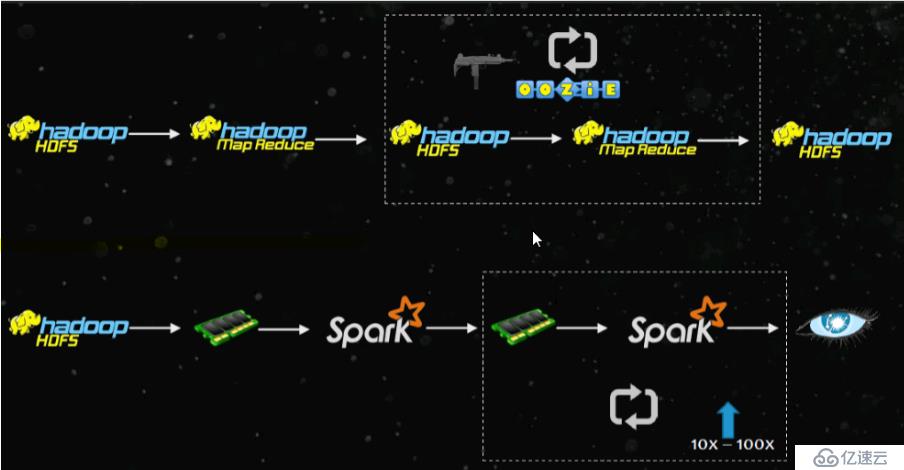
MapReduce和Spark比较
异同点:
基本原理上
MapReduce 是基于磁盘的大数据批量处理
Spark 是基于RDD(弹性分布式数据集)数据处理,RDD可以存储在内存中,也可以存储在磁盘中。
2. 模型上
MapReduce 适合处理超大规模的数据集,用于批处理。适合处理较少迭代的长任务需求。
Spark 适合数据挖掘,迭代次数较多的,例如机器学习等多轮迭代任务。
3. 容错性
MapReduce的每一步迭代,都需要将结果写入硬盘,然后再从硬盘中读取数据计算。只要一步失败,则整个任务都失败。
Spark使用DAG将任务拆分成许多步骤,每个步骤迭代的过程中,数据写内存。而且Spark还提供容错功能。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





