本篇文章给大家分享的是有关怎样深入理解C语言的指针,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
之前在知乎上看了一句话,指针是C的精髓,也是初学者的一个坎。换句话说,内存管理是C的精髓,C/C++可以直接跟OS打交道,从性能角度出发,开发者可以根据自己的实际使用场景灵活进行内存分配和释放。虽然在C++中自C++11引入了smart pointer,虽然很大程度上能够避免使用裸指针,但仍然不能完全避免,最重要的一个原因是你不能保证组内其他人不适用指针,更不能保证合作部门不使用指针。
那么为什么C/C++中会存在指针呢?
这就得从进程的内存布局说起。
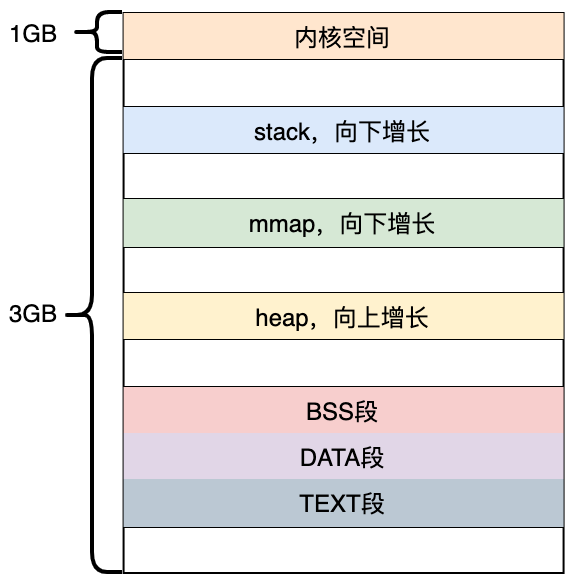
上图为32位进程的内存布局,从上图中主要包含以下几个块:
内核空间:供内核使用,存放的是内核代码和数据
stack:这就是我们经常所说的栈,用来存储自动变量(automatic variable)
mmap:也成为内存映射,用来在进程虚拟内存地址空间中分配地址空间,创建和物理内存的映射关系
heap:就是我们常说的堆,动态内存的分配都是在堆上
bss:包含所有未初始化的全局和静态变量,此段中的所有变量都由0或者空指针初始化,程序加载器在加载程序时为BSS段分配内存
ds:初始化的数据块
包含显式初始化的全局变量和静态变量
此段的大小由程序源代码中值的大小决定,在运行时不会更改
它具有读写权限,因此可以在运行时更改此段的变量值
该段可进一步分为初始化只读区和初始化读写区
text:也称为文本段
该段包含已编译程序的二进制文件。
该段是一个只读段,用于防止程序被意外修改
该段是可共享的,因此对于文本编辑器等频繁执行的程序,内存中只需要一个副本
由于本文主要讲内存分配相关,所以下面的内容仅涉及到栈(stack)和堆(heap)。
栈一块连续的内存块,栈上的内存分配就是在这一块连续内存块上进行操作的。编译器在编译的时候,就已经知道要分配的内存大小,当调用函数时候,其内部的遍历都会在栈上分配内存;当结束函数调用时候,内部变量就会被释放,进而将内存归还给栈。
class Object {
public:
Object() = default;
// ....
};
void fun() {
Object obj;
// do sth
}在上述代码中,obj就是在栈上进行分配,当出了fun作用域的时候,会自动调用Object的析构函数对其进行释放。
前面有提到,局部变量会在作用域(如函数作用域、块作用域等)结束后析构、释放内存。因为分配和释放的次序是刚好完全相反的,所以可用到堆栈先进后出(first-in-last-out, FILO)的特性,而 C++ 语言的实现一般也会使用到调用堆栈(call stack)来分配局部变量(但非标准的要求)。
因为栈上内存分配和释放,是一个进栈和出栈的过程(对于编译器只是一个移动指针的过程),所以相比于堆上的内存分配,栈要快的多。
虽然栈的访问速度要快于堆,每个线程都有一个自己的栈,栈上的对象是不能跨线程访问的,这就决定了栈空间大小是有限制的,如果栈空间过大,那么在大型程序中几十乃至上百个线程,光栈空间就消耗了RAM,这就导致heap的可用空间变小,影响程序正常运行。
在Linux系统上,可用通过如下命令来查看栈大小:
ulimit -s
10240在笔者的机器上,执行上述命令输出结果是10240(KB)即10m,可以通过shell命令修改栈大小。
ulimit -s 102400通过如上命令,可以将栈空间临时修改为100m,可以通过下面的命令:
/etc/security/limits.conf
静态分配
静态分配由编译器完成,假如局部变量以及函数参数等,都在编译期就分配好了。
void fun() {
int a[10];
}上述代码中,a占10 * sizeof(int)个字节,在编译的时候直接计算好了,运行的时候,直接进栈出栈。
动态分配
可能很多人认为只有堆上才会存在动态分配,在栈上只可能是静态分配。其实,这个观点是错的,栈上也支持动态分配,该动态分配由alloca()函数进行分配。栈的动态分配和堆是不同的,通过alloca()函数分配的内存由编译器进行释放,无序手动操作。
分配速度快:分配大小由编译器在编译器完成
不会产生内存碎片:栈内存分配是连续的,以FIFO的方式进栈和出栈
大小受限:栈的大小依赖于操作系统
访问受限:只能在当前函数或者作用域内进行访问
堆(heap)是一种内存管理方式。内存管理对操作系统来说是一件非常复杂的事情,因为首先内存容量很大,其次就是内存需求在时间和大小块上没有规律(操作系统上运行着几十甚至几百个进程,这些进程可能随时都会申请或者是释放内存,并且申请和释放的内存块大小是随意的)。
堆这种内存管理方式的特点就是自由(随时申请、随时释放、大小块随意)。堆内存是操作系统划归给堆管理器(操作系统中的一段代码,属于操作系统的内存管理单元)来管理的,堆管理器提供了对应的接口_sbrk、mmap_等,只是该接口往往由运行时库进行调用,即也可以说由运行时库进行堆内存管理,运行时库提供了malloc/free函数由开发人员调用,进而使用堆内存。
正如我们所理解的那样,由于是在运行期进行内存分配,分配的大小也在运行期才会知道,所以堆只支持动态分配,内存申请和释放的行为由开发者自行操作,这就很容易造成我们说的内存泄漏。
变量可以在进程范围内访问,即进程内的所有线程都可以访问该变量
没有内存大小限制,这个其实是相对的,只是相对于栈大小来说没有限制,其实最终还是受限于RAM
相对栈来说访问比较慢
内存碎片
由开发者管理内存,即内存的申请和释放都由开发人员来操作
理解堆和栈的区别,对我们开发过程中会非常有用,结合上面的内容,总结下二者的区别。
对于栈来讲,是由编译器自动管理,无需我们手工控制;对于堆来说,释放工作由程序员控制,容易产生memory leak
空间大小不同
一般来讲在 32 位系统下,堆内存可以达到4G的空间,从这个角度来看堆内存几乎是没有什么限制的。
对于栈来讲,一般都是有一定的空间大小的,一般依赖于操作系统(也可以人工设置)
能否产生碎片不同
对于堆来讲,频繁的内存分配和释放势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。
对于栈来讲,内存都是连续的,申请和释放都是指令移动,类似于数据结构中的进栈和出栈
增长方向不同
对于堆来讲,生长方向是向上的,也就是向着内存地址增加的方向
对于栈来讲,它的生长方向是向下的,是向着内存地址减小的方向增长
分配方式不同
堆都是动态分配的,比如我们常见的malloc/new;而栈则有静态分配和动态分配两种。
静态分配是编译器完成的,比如局部变量的分配,而栈的动态分配则通过alloca()函数完成
二者动态分配是不同的,栈的动态分配的内存由编译器进行释放,而堆上的动态分配的内存则必须由开发人自行释放
分配效率不同
栈有操作系统分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高
堆内存的申请和释放专门有运行时库提供的函数,里面涉及复杂的逻辑,申请和释放效率低于栈
截止到这里,栈和堆的基本特性以及各自的优缺点、使用场景已经分析完成,在这里给开发者一个建议,能使用栈的时候,就尽量使用栈,一方面是因为效率高于堆,另一方面内存的申请和释放由编译器完成,这样就避免了很多问题。
终于到了这一小节,其实,上面讲的那么多,都是为这一小节做铺垫。
在前面的内容中,我们对比了栈和堆,虽然栈效率比较高,且不存在内存泄漏、内存碎片等,但是由于其本身的局限性(不能多线程、大小受限),所以在很多时候,还是需要在堆上进行内存。
我们先看一段代码:
#include <stdio.h>
#include <stdlib.h>
int main() {
int a;
int *p;
p = (int *)malloc(sizeof(int));
free(p);
return 0;
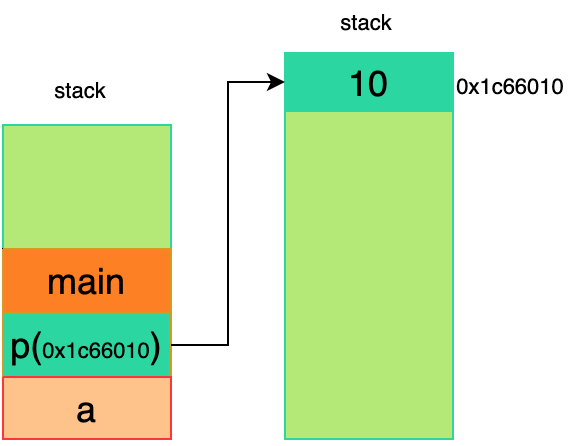
}上述代码很简单,有两个变量a和p,类型分别为int和int *,其中,a和p存储在栈上,p的值为在堆上的某块地址(在上述代码中,p的值为0x1c66010),上述代码布局如下图所示:
以上就是怎样深入理解C语言的指针,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



