这篇文章主要为大家展示了“基于pycharm的beautifulsoup4库怎么用”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“基于pycharm的beautifulsoup4库怎么用”这篇文章吧。
第一步:在控制台输入如下命令,安装beautifulsoup4库。
pip install beautifulsoup4
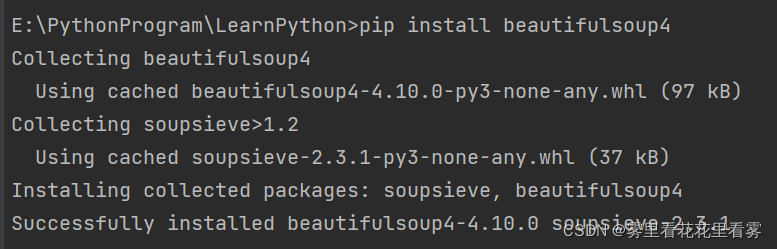
第二步:在控制台输入如下命令,验证是否成功安装beautifulsoup4库。
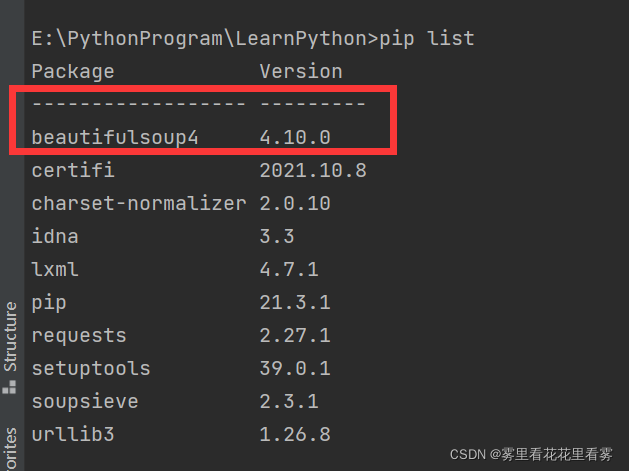
第三步:在pycharm中,点击file——settings——project——python interpreter——点击+号——搜索beautifulsoup4——install package!

这样就可以在.py文件中导入模块了!
import requests
# 虽然库名叫做beautiful4 但是在导入时 使用的是其缩写bs4 其中BeautifulSoup是一个类名
from bs4 import BeautifulSoup
url = 'https://www.baidu.com/s?'
# 由于一般网站都是供用户访问 如果检测到User-Agent是黑客或者其他可能拒绝访问 故此处模拟浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
# 以防乱码 此处将其编码设置为utf-8 因为有中文
response.encoding = 'utf-8'
# print(response.text)
# 使用的解析器是html.parser 注意是.奥
soup = BeautifulSoup(response.text, 'html.parser')
# 打印解析后的结果
print(soup.prettify())需要讲解的都在代码注释中了奥!
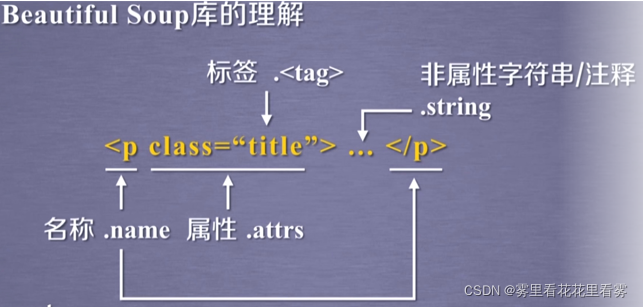
beautifulsoup4库是解析、遍历、维护“标签树”的功能库。
首先来看BeautifulSoup库解析器,前两个比较常用!

再来看BeautifulSoup库的基本元素,可以这样理解,标签树和HTML以及BeautifulSoup是一样的,我们要看HTML的某些内容就使用BeautifulSoup的实例化对象查看即可。

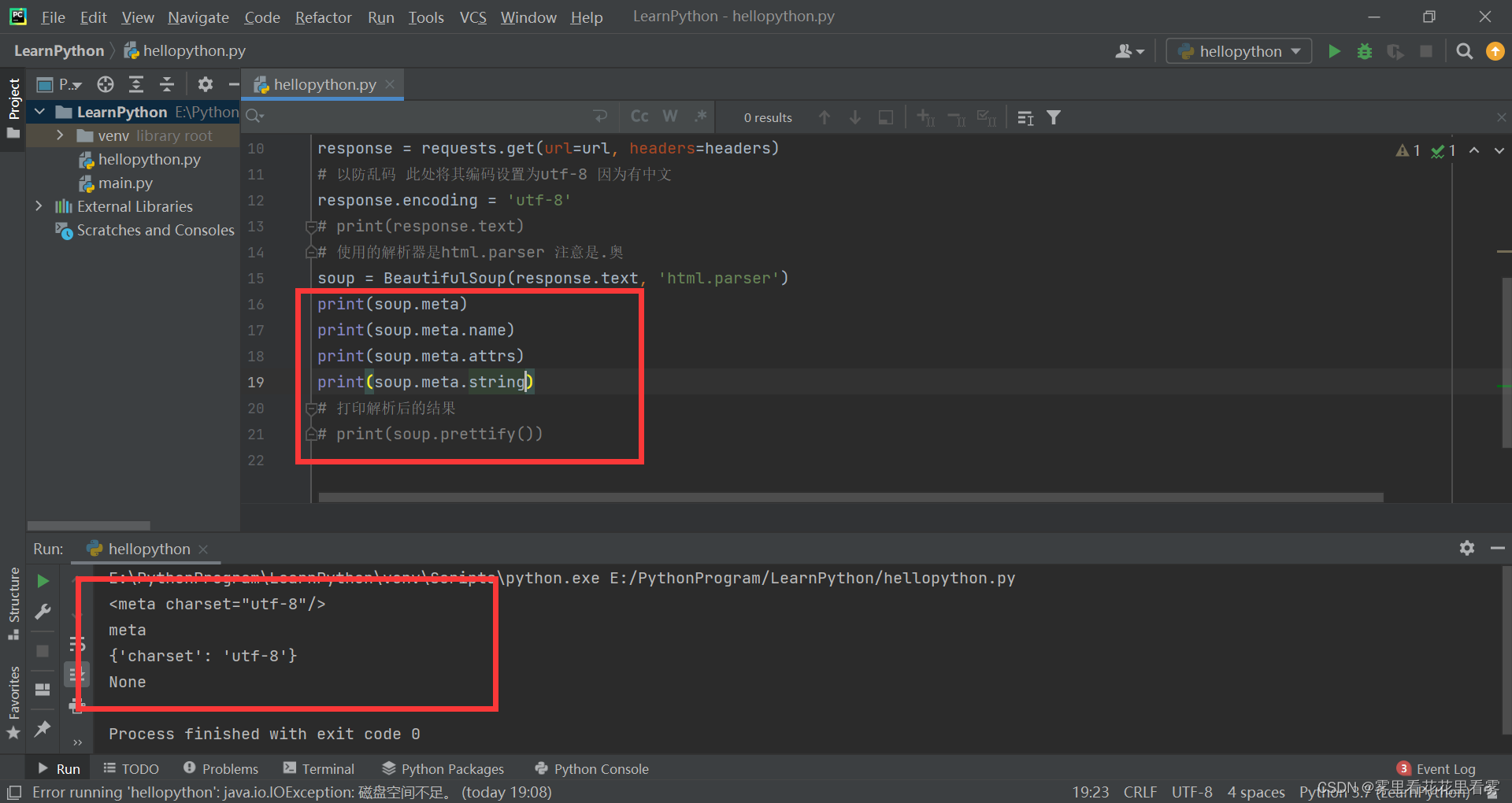
在上述代码的基础上,增加如下几行,结合基本元素的使用,可得到如图所示。
需要注意的是,.string可以跨标签,所以很有可能结果也为注释,为了区分是标签内的字符串还是注释,可以通过打印类型来判断。
总结起来,可如下:


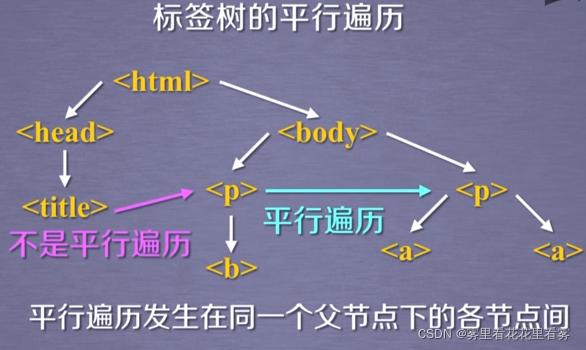
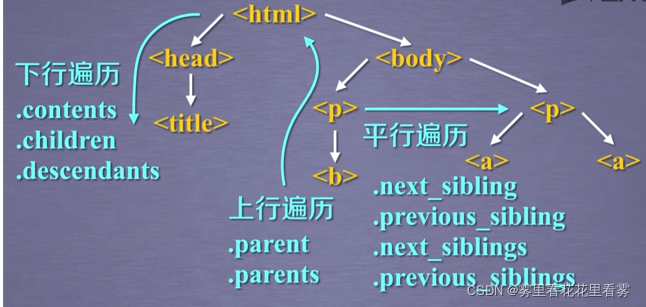
接下来,看一下BeautifulSoup库的遍历,其中画红框的迭代遍历,可以用于for in循环中。
find_all( name , attrs , recursive , string , **kwargs )find_all() 方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件。
name 参数可以对名字为 name 的标签进行检索。
attrs参数可以对标签属性值为attrs的标签进行检索。
recursive参数表示是否对子孙全部检索,默认是TRUE,如果只想搜索当前节点的儿子信息,可以置其为FALSE。
string 参数可以标签中的字符串内容进行检索。

我们学过js的或者java的,应该对Json不陌生吧!
Json是一种有类型的键值对!
需要注意的是,键和值都需要用"“括起来,如果值是整数,则可以不用”"!
如果值是多值,则可以用[,];如果值是键值对,则可以用{:,:,},可以嵌套使用。

JSON一般用于接口,而YAML是无类型键值对,一般用于配置文件。
以上是“基于pycharm的beautifulsoup4库怎么用”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



