这篇文章主要为大家展示了“Python中如何实现支持向量机数据分类和回归预测”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“Python中如何实现支持向量机数据分类和回归预测”这篇文章吧。
支持向量机常用于数据分类,也可以用于数据的回归预测
我们经常会遇到这样的问题,给你一些属于两个类别的数据(如子图1),需要一个线性分类器将这些数据分开,有很多分法(如子图2),现在有一个问题,两个分类器,哪一个更好?为了判断好坏,我们需要引入一个准则:好的分类器不仅仅能够很好的分开已有的数据集,还能对为知的数据进行两个划分,假设现在有一个属于红色数据点的新数据(如子图3中的绿三角),可以看到此时黑色的线会把这个新的数据集分错,而蓝色的线不会。**那么如何评判两条线的健壮性?**此时,引入一个重要的概念——最大间隔(刻画着当前分类器与数据集的边界)(如子图4中的阴影部分)可以看到蓝色的线最大的间隔大于黑色的线,所以选择蓝色的线作为我们的分类器。(如子图5)此时的分类器是最优分类器吗?或者说,有没有更好的分类器具有更大的间隔?有的(如子图6)为了找到最优分类器,引入SVM
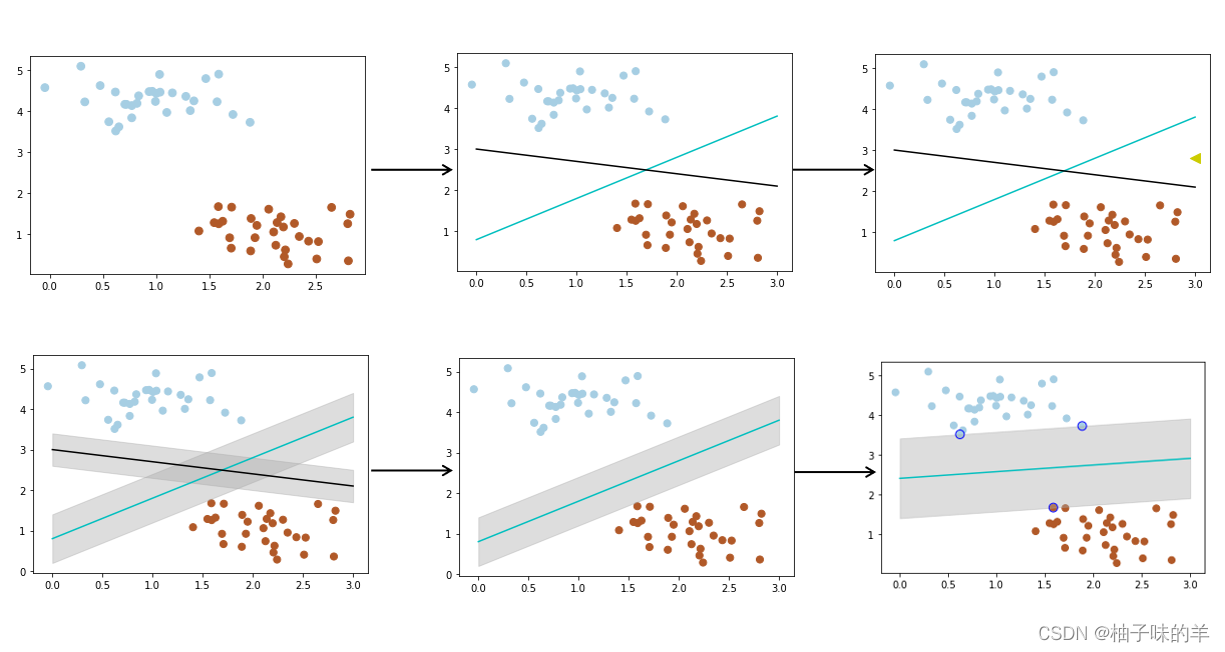
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=60, centers=2, random_state=0, cluster_std=0.4)
x_fit = np.linspace(0, 3)
#使用SVM
from sklearn.svm import SVC
# SVM 函数
clf = SVC(kernel='linear')
clf.fit(X, y)
# 最佳函数
w = clf.coef_[0]
a = -w[0] / w[1]
y_p = a*x_fit - (clf.intercept_[0]) / w[1]
# 最大边距 下边界
b_down = clf.support_vectors_[0]
y_down = a* x_fit + b_down[1] - a * b_down[0]
# 最大边距 上届
b_up = clf.support_vectors_[-1]
y_up = a* x_fit + b_up[1] - a * b_up[0]
# 画散点图
X, y = make_blobs(n_samples=60, centers=2, random_state=0, cluster_std=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
# 画函数
plt.plot(x_fit, y_p, '-c')
# 画边距
plt.fill_between(x_fit, y_down, y_up, edgecolor='none', color='#AAAAAA', alpha=0.4)
# 画支持向量
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], edgecolor='b',
s=80, facecolors='none')运行结果
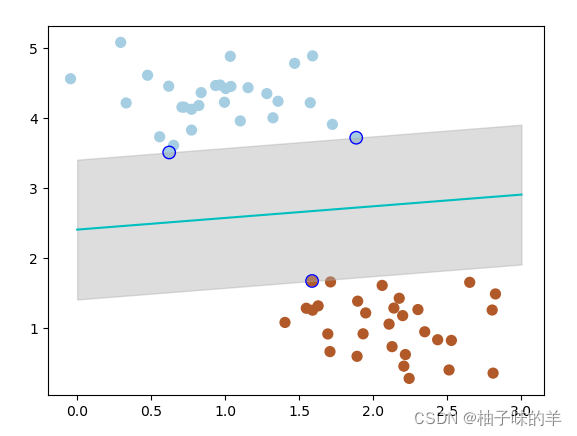
其中带边线的是距离当前分类器最近的点,将这些点称之为支持向量,支持向量机为我们在众多可能的分类器之间进行选择的原则,从而确保对为知数据集具有更高的泛化性
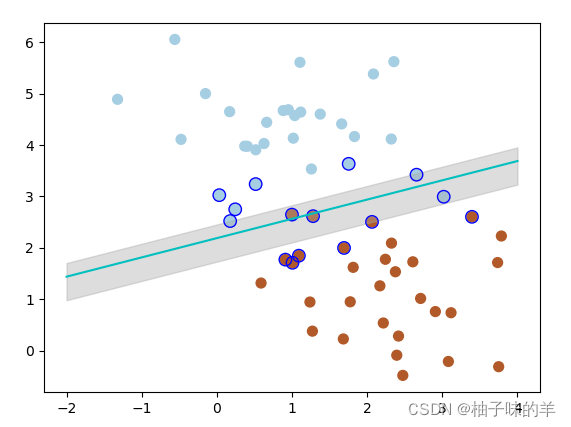
在很多时候,我们拿到是数据不想上述那样分明(如下图)这种情况并不容易找到上述那样的最大间隔。于是就有了软间隔,相对于硬间隔,我们允许个别数据出现在间隔带中。我们知道,如果没有一个原则进行约束,满足软间隔的分类器也会出现很多条。所以需要对分错的数据进行惩罚,SVM函数,有一个参数C就是惩罚参数。惩罚参数越小,容忍性就越大
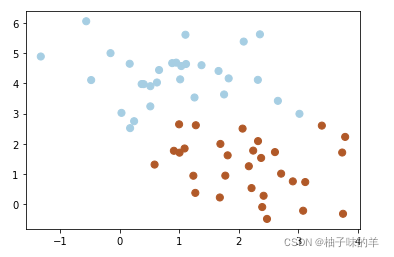
——此处C设置为1
#%%软间隔
X, y = make_blobs(n_samples=60, centers=2, random_state=0, cluster_std=0.9)
x_fit = np.linspace(-2, 4)
# 惩罚参数:C=1,
clf = SVC(C=1, kernel='linear')
clf.fit(X, y)
# 最佳函数
w = clf.coef_[0]
a = -w[0] / w[1]
y_great = a*x_fit - (clf.intercept_[0]) / w[1]
# 最大边距 下边界
b_down = clf.support_vectors_[0]
y_down = a* x_fit + b_down[1] - a * b_down[0]
# 最大边距 上边界
b_up = clf.support_vectors_[-1]
y_up = a* x_fit + b_up[1] - a * b_up[0]
# 画散点图
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
# 画函数
plt.plot(x_fit, y_great, '-c')
# 画边距
plt.fill_between(x_fit, y_down, y_up, edgecolor='none', color='#AAAAAA', alpha=0.4)
# 画支持向量
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], edgecolor='b',
s=80, facecolors='none')运行结果
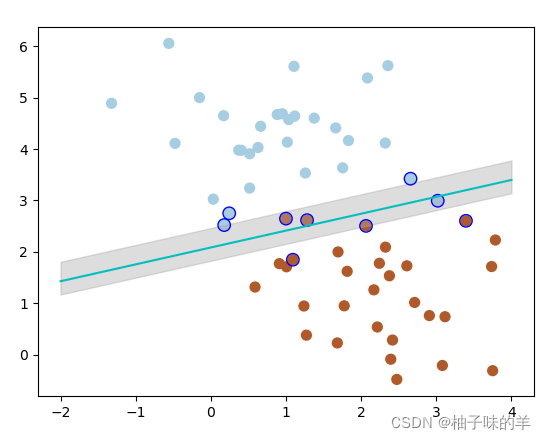
——当将C设置为0.2时,SVM会更有包容性,从而兼容更多的错分样本,结果如下:
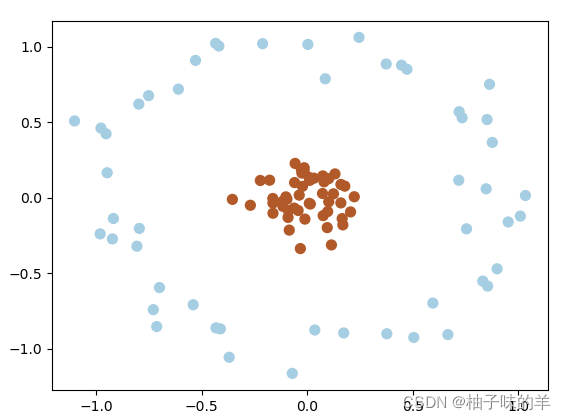
有时,我们得到的数据是这样的(如下图),这时,可以将二维空间(低维)的数据映射到三维空间(高维)中,此时,可以通过一个超平面对数据进行划分,所以,映射的目的在于使用SVM在高维空间找到超平面的能力
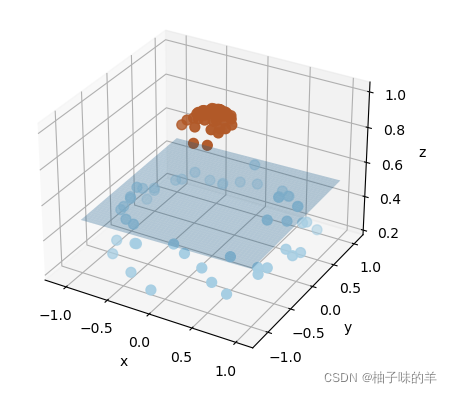
#%%超平面
from sklearn.datasets import make_circles
# 画散点图
X, y = make_circles(100, factor=.1, noise=.1, random_state=2019)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
# 数据映射
r = np.exp(-(X[:, 0] ** 2 + X[:, 1] ** 2))
ax = plt.subplot(projection='3d')
ax.scatter3D(X[:, 0], X[:, 1], r, c=y, s=50, cmap=plt.cm.Paired)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
x_1, y_1 = np.meshgrid(np.linspace(-1, 1), np.linspace(-1, 1))
z = 0.01*x_1 + 0.01*y_1 + 0.5
ax.plot_surface(x_1, y_1, z, alpha=0.3)运行结果
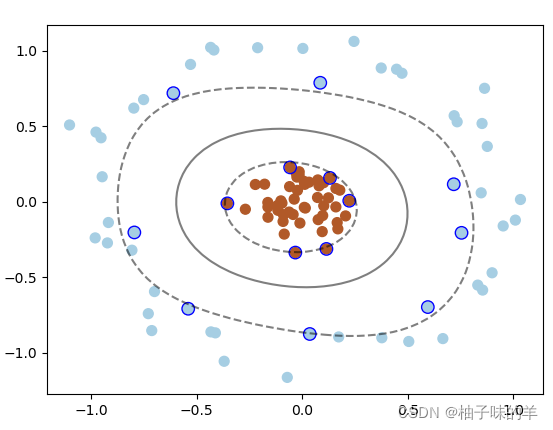
使用高斯核函数实现这种情形的分类
#%%使用高斯核函数实现这种分类:kernel=‘rbf'
# 画图
X, y = make_circles(100, factor=.1, noise=.1, random_state=2019)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
clf = SVC(kernel='rbf')
clf.fit(X, y)
ax = plt.gca()
x = np.linspace(-1, 1)
y = np.linspace(-1, 1)
x_1, y_1 = np.meshgrid(x, y)
P = np.zeros_like(x_1)
for i, xi in enumerate(x):
for j, yj in enumerate(y):
P[i, j] = clf.decision_function(np.array([[xi, yj]]))
ax.contour(x_1, y_1, P, colors='k', levels=[-1, 0, 0.9], alpha=0.5,linestyles=['--', '-', '--'])
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], edgecolor='b',s=80, facecolors='none');运行结果
以上是“Python中如何实现支持向量机数据分类和回归预测”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



