本教程是在三台电脑上部署的hadoop正式环境,没有建立用户组,而是在当前用户下直接进行集群的部署的,总结如下:
1、三个节点的主机电脑名为:192.168.11.33 Master,192.168.11.24 Slaver2,192.168.11.4
Slaver1,并且这三台主机用户名都要设置一样,我的都是hadoop的用户。
因为本教程使用的是vim编辑器,如果没有vim可以下载一个:sudo apt-get install vim
2、修改hosts文件:切换到root用户下:sudo -s,然后输入密码,vim /etc/hosts,通过vim把三个电脑的主机名和ip地址都加进去,ip在前,主机名在后:
192.168.12.32 Master
192.168.12.24 Slaver2
192.168.12.4 Slaver1
3、修改主机的名称,也是在root用户下,vim /etc/hostname,把三个主机的名字分别于上面的Master,Slaver1,Slaver2,对应,一个机器对应一个主机名,不能把三个都放进去
4、在Ubuntu中查看ip地址的命令为:ifconfig
5、安装ssh,在安装ssh之前,首先要更新下载Ubuntu软件的源:sudo apt-get update
安装ssh: sudo apt-get install ssh
查看sshd服务是否启动:ps -e | grep ssh ,如果出现 1019 ?00:00:00 sshd这样的信息,表 示ssh已经启动。如果没有启动,则输入:/etc/init.d/ssh start或者sudo start ssh,进行启动
6、设置ssh的无秘钥登录,这个不需要再root用户下进行,不然不是在当前用户下,则不能进行无秘钥登录的设置
6.1、ssh-keygen -t rsa ,然后一直按回车键
6.2、上述操作完毕后,会在当且用户下有一个隐藏文件夹.ssh,可以通过:ls -al进行查看
里面的文件有:id_rsa,id_rsa.pub
6.3、进入.ssh目录下:cd .ssh,然后执行:cat id_rsa.pub >> authorized_keys(此文件刚开始 时不存在.ssh目录中的),执行完以后,会自动生成一个authorized_keys文件
6.4、然互在.ssh下直接登录:ssh localhost,不出意外的话,将成功登录并且不需要输入密码,登录完成后,在.ssh下会生成一个known_hosts的文件
7、上面的三个主机都要执行6的操作
8、设置节点之间的无秘钥登录,配置Master对Slaver1和Slaver2的无秘钥登录,把Master的id_rsa.pub复制到Slaver1和Slaver2节点上,在Slaver1和Slaver2节点上的.ssh目录下分别执行如下命令:
scp hadoop@Master:~/.ssh/id_rsa.pub ./master_rsa.pub
cat master_rsa.pub >> authorized_keys
9、完成以上操作时,在Slaver1和Slaver2上分别执行这样的操作,即实现三个机器彼此之间都要实现无秘钥登录,因为在hadoop中,主节点和从节点之间要进行通讯,namenode需要管理datanode,并且datanode也要想namenode发送状态信息,来告诉namenode自己的状态,同时datanode之间也要进行通讯,在数据的复制中和存储中,hadoop的把数据分成三个副本进行存储,在复制中,是从前一个datanode获取数据,放到当前的datanode中,所以要实现三个节点之间的相互通讯。
10、完成上面的可以进行无秘钥登录:ssh Slaver1、ssh Slaver2,ssh Master,退出当前用户可以直接用exit
11、如果在步骤6的6.4需要密码,则说明无秘钥登录设置失败,办法就是卸载ssh,在重新安装,从6在重新开始,卸载前要先关闭sshd服务:sudo stop ssh,然后执行:
sudo apt-get autoremove openssh-server
sudo apt-get autoremove openssh-client,
同时要删除.ssh文件目录:sudo rm -rf .ssh,最好重启一下,然后从步骤5重新开始。
12、安装java jdk,在当前用户下建立一个目录:sudo mkdir Java,这样不是在root用户下进行的,而是在本用户下进行安装的。
12.1 解压: tar zxvf jkd名称 -C(大写) /Java
12.2 把Java目录中的文件名改为:jdk8:sudo mv jdk名称 jdk8
12.3 配置文件java路径:vim ~/.bashrc 在文件的最后加入下面的内容
export JAVA_HOME = /home/hadoop/Java/jdk8
export JRE_HOME =${JAVA_HOME}/jre
export CLASSPATH=.:{JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
12.4 退出后,执行:source ~/.bashrc使其立即生效
12.5 检查jdk是否安装成功:java -version,如果出现java的版本等信息,则说明安装成功
13、安装hadoop,在主机Master进行hadoop的安装和配置,然后把此hadoop复制到Slaver1和Slaver2上,这样的一种安装虽然说不是最优的,但是对于初学者来说,是最方便的,当逐渐深入hadoop的学习时,可以在根据不同的机器以及性能,对hadoop进行调优。
13.1 把hadoop解压到用户的当前目录中:tar -zxvf /Downloads/hadoop压缩文件,压缩文件后面没有跟任何的路径,就会在用户下当前目录建立一个解压的hadoop目录。
13.2 修改hadoop的文件名:mv hadoop名称 hadoop
13.3 配置profile文件:vim /etc/profile:
export HADOOP_INSTALL =/home/hadoop/hadoop
export PATH = $PATH:${HADOOP_INSTALL}/bin
13.4 进入hadoop目录中:cd hadoop,然后输入:source /etc/profile 从而使刚才配置的文件生效
14、Hadoop配置文件的配置,由于hadoop1.x和hadoop2.x使用了不同的资源管理,在hadoop2.x增加了yarn来管理hadoop的资源,同时hadoop的文件目录hadoop1.x和hadoop2.x还是有比较大的差别的,本教程采用的是hadoop2.7.0,在这里本人多说一句,有很多人建议对于初学者而言,最好使用hadoop0.2.0这样的版本来进行学习;本人建议没有必要这样,因为hadoop是在不断发展,说白了我们学习hadoop的目的是为了以后在工作中可以使用,现在公司一般都把自己的hadoop集群升级到hadoop2.x的稳定版本了,而且hadoop0.2.0与现在的hadoop版本有了很大的区别;对于理解hadoop的学习时有一定的帮助,但是没有必要非要从头开始学习,可以直接学习hadoop2.x,也可以不费太大的力气就可以学会的,并且hadoop2.x的书籍中,对之前的版本是会有介绍的,而且资料也比较的多。
14.1 进入到hadoop的配置文件(这个是hadoop2.7.0版本的文件组织):
cd /hadoop/etc/hadoop
使用:ls,可以看到很多的配置信息,首先我们配置core-site.xml
14.2 配置hadoop的core-site.xml: vim core-site.xml,
在尾部添加:
<configuration>
<property>
<value>hdfs://192.168.12.32:9000</value> //这个一定要用主机的ip,在eclipse 的配置中需要用到。这个在eclipse链接hadoop将会谈到,暂且这样来进行配置
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop/temp</value>
</property>
</configuration>
在按照上面的配置时,上面的注释一定要去掉啊
14.3 配置hadoop的hdfs-site.xml:vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address<name>
<value>192.168.12.32:50090</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoop/temp/dfs/name</value>
//其中home为根目录,第一个hadoop是我建立的hadoop用户,第二个hadoop是安装hadoop时,建立的hadoop文件名,这个是设置临时文件的地方,当在初始化文件系统后,我们会在我们安装的hadoop路径下看见有一个temp的目录,这个路径的设置,大家可以根据各自的喜好进行设置,但是设置好后,自己以后能找到啊~~
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoop/temp/dfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>2</value> //由于本人是三台机器,可以设置2个副本,当两个计算机2时,要设置为1
</property>
</configuration>
当大家在配置时,一定要把//后面的注释去掉啊~~
14.4 配置mapred-site.xml,这个文件开始时不存在的,首先需要从模板中复制一份:
cp mapred-site.xml.template mapred-site.xml
如果存在这个文件,就不用使用这个操作啦
然后进行mapred-site.xml的配置:vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
14.5 配置yarn-site.xml :vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value> //这个是主机名
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
14.6 配置slaves文件:vim slaves
Slaver1
Slaver2
15、配置hadoop-env.sh文件,在此文件中有一个导入java的目录,但是用#给注释掉啦,去掉后#,然后,把刚才安装的jdk8目录放在后面:export JAVA_HOME=/home/hadoop/Java/jdk8
16、复制hadoop到Slaver1和Slaver2上:
scp -r ./hadoop Slaver1:~
scp -r ./hadoop Slaver2:~
17、由于我们步骤13的配置,把hadoop的bin加入到shell命令中,因此在当前目录下就可以使用hadoop命令了啊:
17.1 格式化文件系统:hadoop namenode -formate
会显示多行的配置,在倒数5行左右,如果看到sucessfull等字,说明格式化成功
17.2启动hdfs:start-dfs.sh
17.3 启动yarn:start-yarn.sh
17.4 查看是否启动成功:jps,如果在Master上出现四行提示信息:
5399 Jps
5121 ResourceManager
3975 SecondaryNameNode
4752 NameNode
则表示启动成功,显示的顺序和左边的数字可以不一样,
在Slaver上如果出现三行提示信息:
4645 Jps
4418 DataNode
4531 NodeManager
则表示成功;如果在Slaver上,datanode无法启动,可能是因为以前配过伪分布式的hadoop集群,可以试着把刚才配置的temp文件夹给删除掉,重新进行格式化:hadoop namenode -format,在进行启动,应该可以使用啦
17.5 这个时候,我们就可以用hadoop的shell命令来进行操作了啊:
hadoop dfs -ls
这个可能会出现错误提示’ls’ ‘.’:no file or directiory
这个时候我们可以试试:hadoop dfs -ls /,就不会出现错误了啊
建立目录:
hadoop dfs -mkdir /user
hadoop dfs -mkdir /user/hadoop
Hadoop dfs -mkdir /user/hadoop
Hadoop dfs -mkdir /user/hadoop/input
Hadoop dfs -mkdir /user/hadoop/output
完事以后,就会出现三级目录了,然后建立一个文本,来运行一下wordcount程序:
Vim a.txt,在里面随便写一下东西:
Hadoop
Hadoop
Aaa
Aaa
Spark
Spark
然后把这个传到hdfs上:hadoop dfs -copyFromLocal a.txt /user/hadoop/input/a.txt
运行wordcount程序:
hadoop jar hadoop/share/hadoop/mapreduce/hadop-mapreduce-examples-2.7.0.jar wordcount /user/hadoop/input/a.txt /user/hadoop/output/wordcount/
查看运行的结果:hadoop dfs -cat /user/hadoop/output/wordcount/part-r-00000,就可以看到单词的统计。
18、静态ip的设置:网上有很多的关于静态ip的设置,本人找了一个,按照上面的教程方法,结果把Master主机上的右上角的上网图标给弄没有了啊,并且有些还上不了网啊,花费了一个下午的时间,终于弄明白了啊。设置永久性的静态ip,需要三个步骤,配置三个文件即可。
18.1 设置静态ip:sudo vim /etc/network/interfaces,会有如下信息:
auto lo
iface lo inet loopback
注释掉:#ifacelo inet loopback
添加:
auto eth0
iface eth0 inet static
address 192.168.12.32 ip地址
netmask 255.255.255.0 子网掩码
gateway 192.168.12.1 网关
network 192.168.0.0
broadcast 192.168.11.255 广播
然后保存退出
18.2 配置DNS服务器,这个网上有很多,关于这个的配置,但是当我们重启Ubuntu后,又恢复默认的配置,导致无法正常上网,因此我们需要设置永久的DNS服务器:
sudo vim /etc/resolvconf/resolv.conf/base
在里面添加:nameserver 202.96.128.86 DNS服务器(这个是我的DNS地址),如果不知道自己的DNS服务,可以从windows中的网络中查看,网上有很多放法,这里就不多说了啊
然后保存退出
18.3 配置Networkmanager.conf文件
sudo vim /etc/NetworkManager/NetworkManager.conf
里面的managed=false,如果是false,则需要把它改为true,否则不加修改,保存退出
18.4 一定要是重新启动机器,如果启动机器时,无法上网,则需要看18.3,的文件是否是false,需要改过来,再重启机器就可以上网了啊。
19、上面是关于正式环境的集群,已经搭建成功;然后我们一般不会再Master上进行开发的,我们需要在windows环境下的eclipse进行开发,并在eclipse进行测试,因此,我们下面需要做得就是在windows7+eclipse下构建hadoop的开发环境;
19.1、下载eclipse的hadoop组件,由于hadoop2.x以后,Apache就不在提供eclipse的hadoop组件,只提供源码,我们需要自己构建。我是从网上下载一个eclipse的hadoop组件。
如果采用的hadoop是2.7.0版本的,使用hadoop2.6.0的hadoop组件是可以使用的,我的hadoop版本是2.7.0,而eclipse的hadoop组件是hadoop2.6.0,
下载组件地址:
19.2、选择eclipse的版本,我采用的是spring-tool,它是集成了eclipse的,采用这个的原因是实习的时候用的就是这个版本,而且从网上看到好多直接用eclipse的人,需要版本的选择,以及出现的错误比较多。
下载地址:http://spring.io/tools,点击下图的地方进行下载,下载后直接解压到一个磁盘上就可以使用啦。
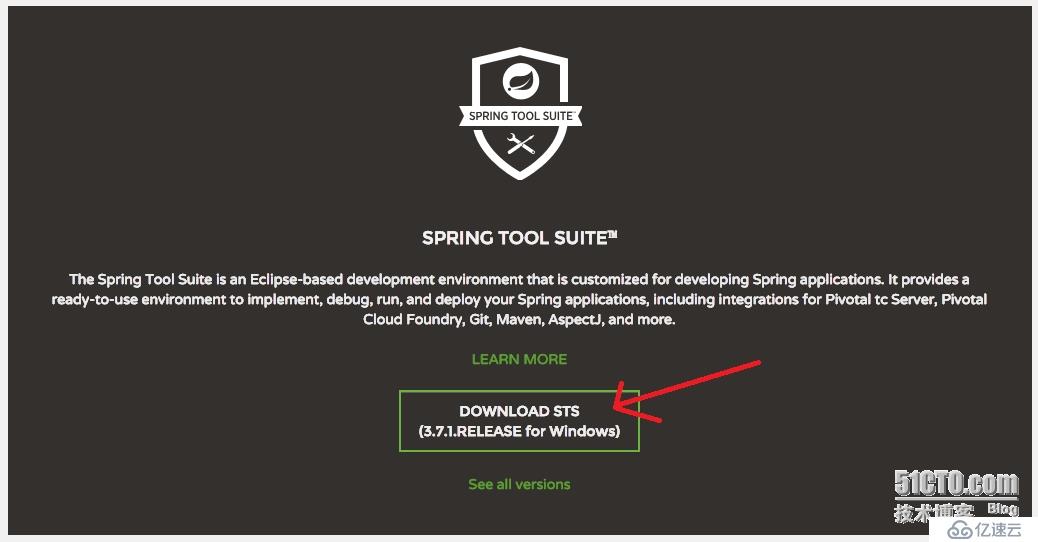
进入到sts-3.7.1RELEASE里面,有一个STL.exe就可以打开了。
19.3、把刚才下载的eclipse的hadoop组件2.6.0放到上图中plugins里面,就可以重启STL,然后点击Window->Preferences,就会看到
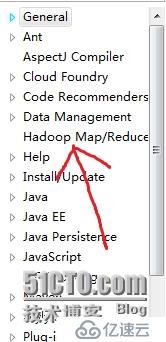
则表示组件安装成功,然后点击Window->Perspective->Open Perspectiver->other,就会在左上角看到:
在正下方会看到:
右键点击上图的Location,会出现这个三个选项,点击New Hadoop Location,就会弹出如下信息:
上面的Location name:可以自己随便填写一个名字我起的是:myhadoop
Host:192.168.12.32,这个是我们安装集群的Master的ip地址,而不是直接填写Master,是因为当填写Master时,当链接hdfs时,会出现listing folder content错误,而且,我们在配置core-site.xml,文件的时,也是建议大家用ip地址,而不是Master,用意就是在这个地方。
Port:9001,这个是和我们设置的core-site.xml的配置一样的,
DFS Master中,Prot:9000,
然后保存退出;
19.4、然后点击这个的DFS Locations
会出现
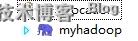 这个名字,和刚才我们设置的一样啊,
这个名字,和刚才我们设置的一样啊,
然后再点击myhadoop,会出现:
这个是我建立的hadoop目录。到这里整个hadoop的安装,以及hadoop在windows下的远程开发都已经基本介绍完毕。但是真正实现hadoop的开发,还需要在eclipse中进行maven的安装学习。这个以后再慢慢写吧
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



