简介
Strom是一个开源的分布式流式计算系统,用来处理流式的数据,被称作为流式的hadoop,在电信行业,可以用来做大流量预警、终端营销、访问竞争对手产品从而做挽留等业务。本文将从storm在hadoop生态圈中所处位置、storm中术语、storm平台搭建、storm应用程序构建等详细介绍storm。
Strom在大数据生态圈中的位置
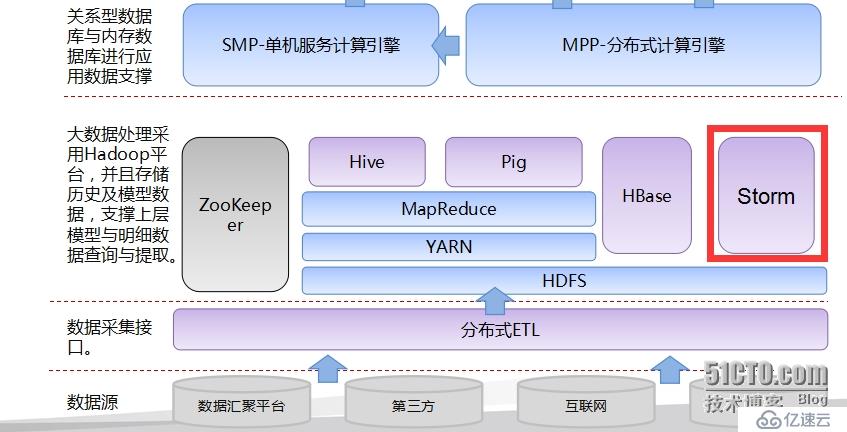
上图可以看出,Storm处于HDFS之上,但是并不是说Storm只能是处理HDFS中数据,反而Storm的数据来源一般是Log日志或者是Kafka中数据,当数据通过Strom处理完成之后,其流向可以是HDFS、HBase、关系型数据库等。
Strom是一个计算系统,在大数据处理中,我们耳熟能详的计算系统是mapreduce,这张架构图看出storm和mapreduce是同级关系,而storm被称作是流式的hadoop。所以接下来将通过与mapreduce进行对比来介绍storm
3.Strom常用术语介绍
| Strom | MapReduce(基于hadoop2.X) | 描述 |
| Nimbus | ApplicationMaster | MapReduce中Resourcemanager负责任务分配、资源申请,同样的在Strom中Nimbus负责代码的分发,任务的分配和调度工作 |
| Supervisor | NodeManager | MapReducer中NodeManager负责资源的申请,工作进程启动和监控,Strom中Supervisor同样负责任务进程的启动和停止 |
| Worker | YarnChild | 真正负责任务处理的进程 |
| Topology | MapReduce | 驱动程序 |
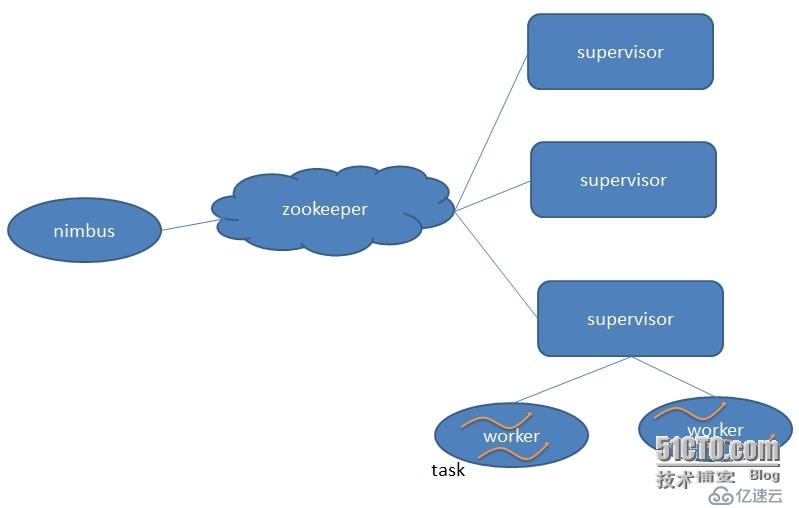
Strom架构Topology:通过Storm构建的应用程序描述了数据的来源、数据的处理逻辑和数据的流向。
Spout:Topology中的组件,通过Spout描述了数据的来源,Spout中有一个nextTuple()函数,该函数会不停的被调用,源数据的生成就在该函数中实现,然后数据流向下一节点,每个Topology中只允许有一个Spout。
Bolt:Topology中的组件,该组件接收上一节点(Spout或Bolt)发射过来的数据,该组件中有一个execute(Tuple tuple)方法,当接收到数据后该函数会被动执行,进行合并、筛选、持久化等操作。Bolt可以是Topology中一次完整的数据处理流程的终点,或者是转移点。
Tuple:Tuple是Storm中传递消息的基本单元,Tuple的数据结构为一个List。
Stream:连续不断的Tuple就组成了Stream。
Stream grouping:描述了数据在不同的组件(Spout/Bolt)之间流转时,partition的规则,类型如下:
1.shuffle Grouping:随机分组,随机派发stream里面的tuple,保证每个bolt接收到的tuple数目相同
2.Fields Grouping:按照字段分组,相同的字段会分配到相同的bolt,不同的字段分配到不同的Bolt
3.ALL Grouping:广播,对每一个tuple,所有的bolt都会收到
4.Global Grouping:全局分组,这个tuple被分配到storm的一个bolt的一个task内,即id最低的那个
5.Non Grouping:不分组,目前效果和Global Groouping一样
6.Direct Grouping:直接分组,指定消息的接收者。亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



