闲来无事,突然看到关于Hadoop集群。以前也了解过,网上找过一些关于百度,谷歌等底层hadoop集群的文档,可是面对很多陌生的技术,看不太通透。所有想自己动手虚拟机试试。经常听到这么高大上的名词,Hadoop已经成为大数据的代名词。短短几年间,Hadoop从一种边缘技术成为事实上的标准。而另一方面,MapReduce在谷歌已不再显赫。当企业瞩目MapReduce的时候,谷歌好像早已进入到了下一个时代。
Hadoop支持三种启动集群模式,分别是单机模式,wei分布式模式,安全分布式模式。下面我做的测试是单机模式。
我用的是阿里云ECS主机免费试用版,,,,,,
uname -a
Linux iZ25wbw8q4uZ 3.13.0-32-generic #57-Ubuntu SMP Tue Jul 15 03:51:08 UTC 2014 x86_64 x86_64 x86_64 GNU/Linux
1,创建hadoop户和群组

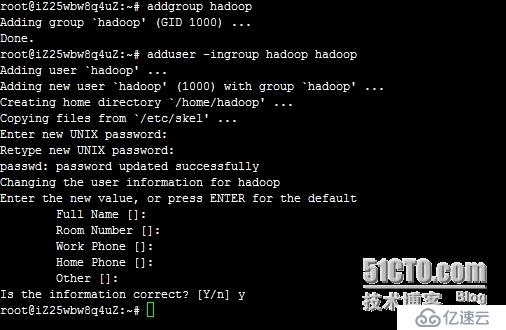
回车后会提示输入新的UNIX密码,这是新建用户hadoop的密码,输入回车即可。
如果不输入密码,回车后会重新提示输入密码,即密码不能为空。
最后确认信息是否正确,如果没问题,输入 Y,回车即可。
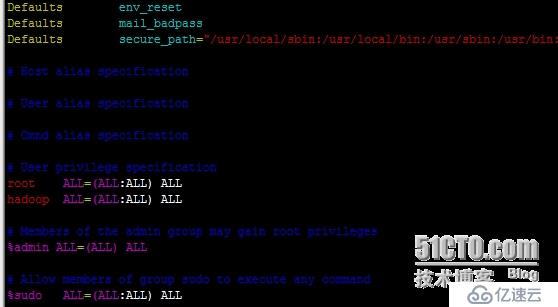
修改hadoop为root权限
vim /etc/sudoers
修改添加hadoop ALL=(ALL:ALL) ALL
2,安装ssh支持服务,实现免密登录
查询ssh包支持,并创建ssh免密登录服务器
用到的命令:su hadoop //切换用户
dpkg -l | grep openssh-server //查询ssh支持包
service ssh start //启动ssh远程连接服务
ssh-keygen -t rsa //生成ssh私/公钥密码文件
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys //拷贝公钥认证文件
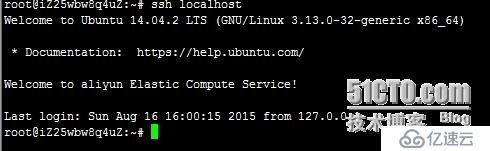
ssh localhost //本机ssh登录测试

3,安装JAVA环境
http://www.oracle.com/technetwork/java/javase/downloads/index.html 下载jdk
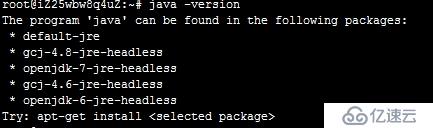
java -version命令出现如下是因为没有正确设置环境变量
tar zxvf jdk-8u51-linux-x64.tar.gz
mv jdk1.8.0_51/ /usr/local/src/jdk1.8
修改环境变量,
vim ~/.bashrc

4,安装Hadoop2.7.1
http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.1/hadoop-2.7.1.tar.gz
tar zxvf hadoop-2.7.1.tar.gz
mv hadoop-2.7.1 /usr/local/hadoop
chown -R hadoop.hadoop hadoop
chmod 774 /usr/local/hadoop/
hadoop@iZ25wbw8q4uZ:/usr/local/hadoop$ vim ~/.bashrc //修改hadoop用户环境变量,最下面添加
#HADOOP VARIABLES START
export JAVA_HOME=/usr/local/src/jdk1.8/
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib"
#HADOOP VARIABLES END

hadoop@iZ25wbw8q4uZ:/usr/local/hadoop$ vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh //修改handoop认证环境变量,最下面添加一行
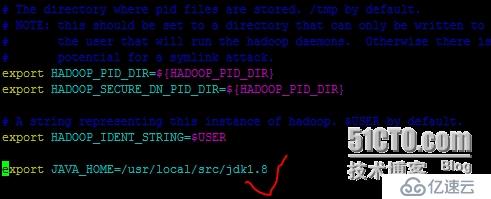
5,WordCount测试
单机模式安装完成,下面通过执行hadoop自带实例WordCount验证是否安装成功
/usr/local/hadoop路径下创建input文件夹
mkdir input
cp README.txt input //拷贝README.txt到input
执行WordCount
hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.7.1-sources.jar org.apache.hadoop.examples.WordCount input output
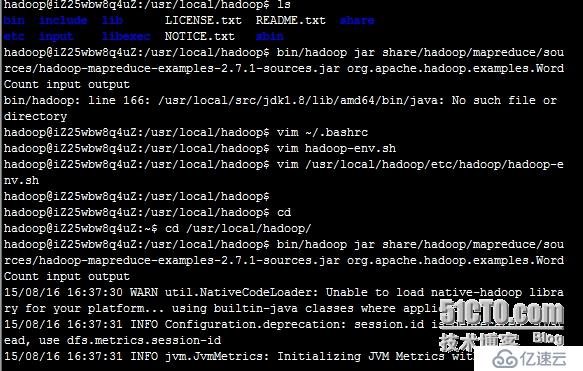

执行 cat output/*,查看字符统计结果
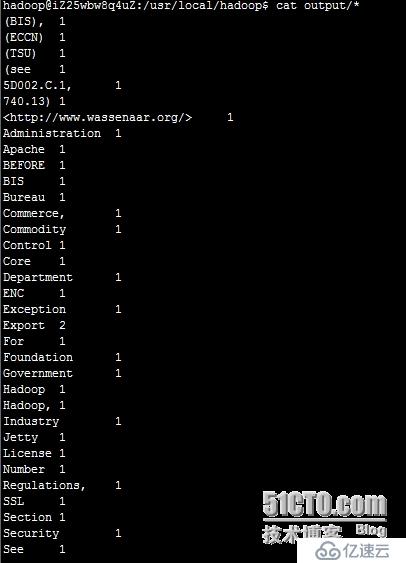
到此,hadoop单机模式已经完成。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





