由于昨晚实在太困了,解释问题的时候眼睛就花了,脑子也短路了。早上起来,发现家人都还在睡,就想继续述说昨晚没有说带劲的东西了。
再次给出我的硬件转发原理图:
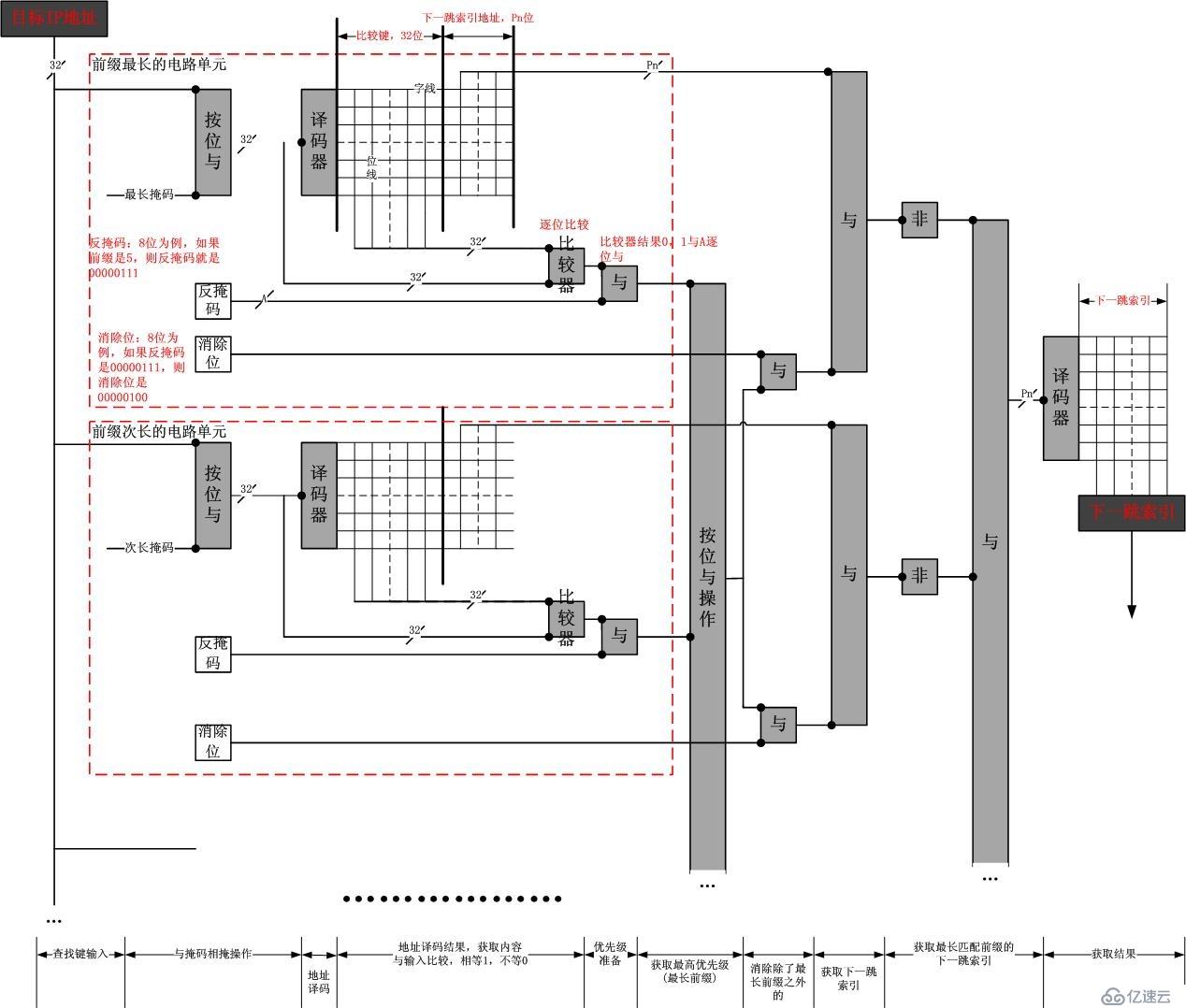
请
注意,没有任何优化,你可以试着用一些小技巧将其进一步的优化,也可以直接用标准的TCAM来映射它。此图里,我详细展示了“最长前缀”逻辑是怎么做的,
而在TCAM路由转发表的实例中,往往被画成了黑盒子,叫做“优先级逻辑控制器”,不过,这个逻辑电路比较简单,相信大家稍微思考都可以自己设计出来的。
其实,在上图中,有一个容器叫做“反掩码”,将这个反掩码逐位地安排在译码器后面的位线比较键旁边,这就是一个标准的TCAM做法了。
我们都知道cache比较贵所以不能太大,而内容就可以做很大,因为它比较便宜。
但是能否从技术层面解释一下呢?其实,贵与便宜的差异就是技术原因造成的,我们先看一下内存的存储阵列的电路:
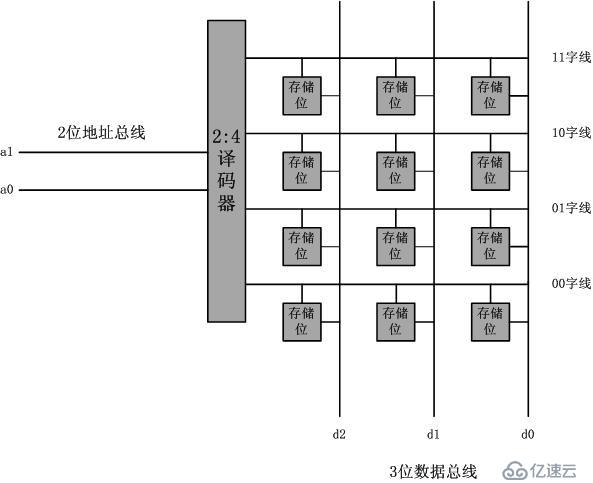
这是个非常典型的矩阵,也很简单。但是对于CAM电路,就不是这么简单了,下图所示:
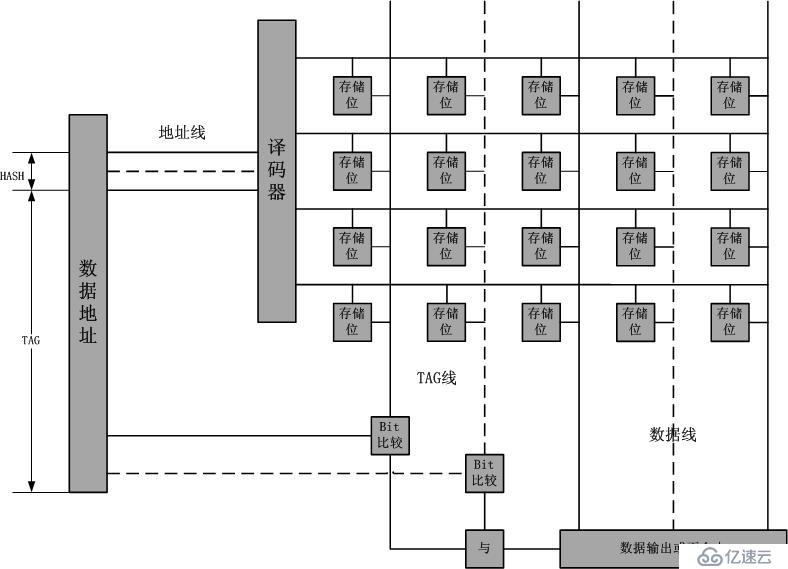
对于TCAM,需要加一个care逻辑,就更加复杂了,不光是电路复杂了,功耗也增加了,要知道,在CAM/TCAM匹配的过程中,电路的所有部分都是同时工作的。
很
多人都说CPU
cache里面有一个硬件HASH,比如取地址的第n到m位,事实上就是一个移位,取模操作!这在程序员看来只能呵呵了,程序员们知道的最简单的HASH
算法都比这个复杂。其实硬件工程师对程序员的呵呵是不屑一顾的,因为他们的关注点是如何使得电路同时工作时功耗最低,电路规模更小。CAM/TCAM都用
了硬件HASH,很简单的硬件HASH,然而电路是可以同时工作的。这可是软件hash的大难题,软件hash旨在使得hash分布更加均匀,平均性能更
好。这样冲突链表长度的平均方差最小。软件hash旨在解决冲突,而硬件HASH不需要这么做,因为在软件看来必须串行遍历冲突链表的时候,硬件却是可以
同时进行的。
计算机被设计之初,就是一个顺序执行的模型,指令是一条接一条执行的。这是因为它是完全模拟真实
世界中人的行为的。这就意味着所有的跑在计算机上的算法步骤都是要时间流逝中串行实施的,一个好的算法旨在让时间花费最短。然而硬件电路的设计并不遵循真
实世界的人做事的样子,起码说不是太像。一个人不可能同时做很多事,硬件电路的执行流程更像是洪水泛滥的过程,由于势能,洪水同时往(注意,同时!)所有
它可以去的地方冲去,瞬时就吞噬了一切。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





