小编给大家分享一下怎么使用SQL查询Linux日志,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
SQL是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统,本篇文章将使用SQL查询 Linux日志。

q是一个命令行工具,允许我们在任意文件或者查询结果,比如可以在ps -ef查询进程命令的结果集上,直接执行SQL语句查询。
宗旨就是文本即数据库表,额~,当然这句话是我自己理解的,哈哈哈
它将普通文件或者结果集当作数据库表,几乎支持所有的SQL结构,如WHERE、GROUP BY、JOINS等,支持自动列名和列类型检测,支持跨文件连接查询,这两个后边详细介绍,支持多种编码。
安装比较简单,在Linux CentOS环境,只要如下三步搞定,Windows环境更是只需安装个exe就可以用了。
wget https://github.com/harelba/q/releases/download/1.7.1/q-text-as-data-1.7.1-1.noarch.rpm #下载版本sudo rpm -ivh q-text-as-data-1.7.1-1.noarch.rpm # 安装q --version #查看安装版本“官方文档:https://harelba.github.io/q
q支持所有SQLiteSQL语法,标准命令行格式q + 参数命令 + “SQL”
q ""我要查询myfile.log文件的内容,直接q “SELECT * FROM myfile.log”。
q "SELECT * FROM myfile.log"q不附加参数使用是完全没有问题的,但利用参数会让显示结果更加美观,所以这里简单了解一下,它的参数分为 2种。
input输入命令:指的是对要查询的文件或结果集进行操作,比如:-H命令,表示输入的数据包含标题行。
q -H "SELECT * FROM myfile.log"在这种情况下,将自动检测列名,并可在查询语句中使用。如果未提供此选项,则列将自动命名为cX,以c1起始以此类推。
q "select c1,c2 from ..."output输出命令:作用在查询输出的结果集,比如:-O,让查询出来的结果显示列名。
[root@iZ2zebfzaequ90bdlz820sZ software]# ps -ef | q -H "select count(UID) from - where UID='root'"104
[root@iZ2zebfzaequ90bdlz820sZ software]# ps -ef | q -H -O "select count(UID) from - where UID='root'"count(UID)
104还有很多参数就不一一列举了,感兴趣的同学在官网上看下,接下来我们重点演示一下使用SQL如何应对各种查询日志的场景。图片 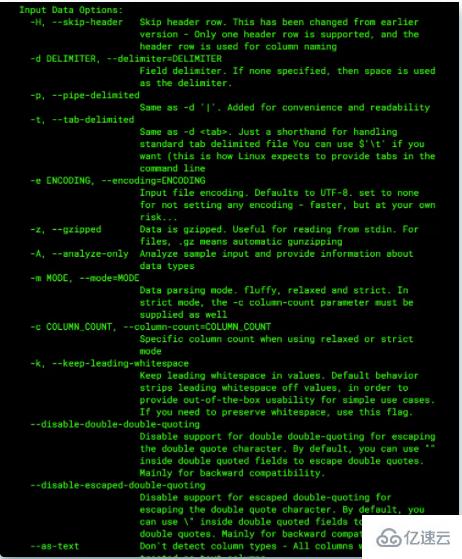
下边咱们一起看几个查询日志的经常场景中,这个SQL该如何写。
1、关键字查询
关键字检索,应该是日常开发使用最频繁的操作,不过我个人认为这一点q并没有什么优势,因为它查询时必须指定某一列。
[root@iZ2zebfzaequ90bdlz820sZ software]# q "select * from douyin.log where c9 like '%待解析%'"2021-06-11 14:46:49.323 INFO 22790 --- [nio-8888-exec-2] c.x.douyin.controller.ParserController : 待解析URL :url=https%3A%2F%2Fv.douyin.com%2Fe9g9uJ6%2F
2021-06-11 14:57:31.938 INFO 22790 --- [nio-8888-exec-5] c.x.douyin.controller.ParserController : 待解析URL :url=https%3A%2F%2Fv.douyin.com%2Fe9pdhGP%2F
2021-06-11 15:23:48.004 INFO 22790 --- [nio-8888-exec-2] c.x.douyin.controller.ParserController : 待解析URL :url=https%3A%2F%2Fv.douyin.com%2Fe9pQjBR%2F
2021-06-11 2而用grep命令则是全文检索。
[root@iZ2zebfzaequ90bdlz820sZ software]# cat douyin.log | grep '待解析URL'2021-06-11 14:46:49.323 INFO 22790 --- [nio-8888-exec-2] c.x.douyin.controller.ParserController : 待解析URL :url=https%3A%2F%2Fv.douyin.com%2Fe9g9uJ6%2F
2021-06-11 14:57:31.938 INFO 22790 --- [nio-8888-exec-5] c.x.douyin.controller.ParserController : 待解析URL :url=https%3A%2F%2Fv.douyin.com%2Fe9pdhGP%2F2、模糊查询
like模糊搜索,如果文本内容列有名字直接用列名检索,没有则直接根据列号c1、c2、cN。
[root@iZ2zebfzaequ90bdlz820sZ software]# cat test.logabc2345232425[root@iZ2zebfzaequ90bdlz820sZ software]# q -H -t "select * from test.log where abc like '%2%'"Warning: column count is one - did you provide the correct delimiter?22324253、交集并集
支持UNION和UNION ALL操作符对多个文件取交集或者并集。
如下建了test.log和test1.log两个文件,里边的内容有重叠,用union进行去重。
q -H -t "select * from test.log union select * from test1.log"[root@iZ2zebfzaequ90bdlz820sZ software]# cat test.logabc2345[root@iZ2zebfzaequ90bdlz820sZ software]# cat test1.logabc3456[root@iZ2zebfzaequ90bdlz820sZ software]# q -H -t "select * from test.log union select * from test1.log"Warning: column count is one - did you provide the correct delimiter?Warning: column count is one - did you provide the correct delimiter?234564、内容去重
比如统计某个路径下的./clicks.csv文件中,uuid字段去重后出现的总个数。
q -H -t "SELECT COUNT(DISTINCT(uuid)) FROM ./clicks.csv"5、列类型自动检测
注意:q会理解每列是数字还是字符串,判断是根据实数值比较,还是字符串比较进行过滤,这里会用到-t命令。
q -H -t "SELECT request_id,score FROM ./clicks.csv WHERE score > 0.7 ORDER BY score DESC LIMIT 5"6、字段运算
读取系统命令查询结果,计算/tmp目录中每个用户和组的总值。可以对字段进行运算处理。
sudo find /tmp -ls | q "SELECT c5,c6,sum(c7)/1024.0/1024 AS total FROM - GROUP BY c5,c6 ORDER BY total desc"[root@iZ2zebfzaequ90bdlz820sZ software]# sudo find /tmp -ls | q "SELECT c5,c6,sum(c7)/1024.0/1024 AS total FROM - GROUP BY c5,c6 ORDER BY total desc"www www 8.86311340332
root root 0.207922935486
mysql mysql 4.76837158203e-067、数据统计
统计系统拥有最多进程数的前 3个用户ID,按降序排序,这就需要和系统命令配合使用了,先查询所有进程再利用SQL筛选,这里的q命令就相当grep命令。
ps -ef | q -H "SELECT UID,COUNT(*) cnt FROM - GROUP BY UID ORDER BY cnt DESC LIMIT 3"[root@iZ2zebfzaequ90bdlz820sZ software]# ps -ef | q -H "SELECT UID,COUNT(*) cnt FROM - GROUP BY UID ORDER BY cnt DESC LIMIT 3"root 104
www 16
rabbitmq 4
[root@iZ2zebfzaequ90bdlz820sZ software]# ps -ef | q -H -O "SELECT UID,COUNT(*) cnt FROM - GROUP BY UID ORDER BY cnt DESC LIMIT 3"UID cnt
root 110
www 16
rabbitmq 4我们看到加与不加-O命令的区别就是否显示查询结果的标题。
8,连文件查
一般情况下,我们的日志文件会按天分割成很多个固定容量的子文件,在没有统一的日志收集服务器的情况下,如果不给个报错时间区间去查一个关键词,那么无异于大海捞针。  图片如果可以将所有文件内容合并后在查就会省事很多,q支持将文件像数据库表那样联合查询。
图片如果可以将所有文件内容合并后在查就会省事很多,q支持将文件像数据库表那样联合查询。
q -H "select * from douyin.log a join douyin-2021-06-18.0.log b on (a.c2=b.c3) where b.c1='root'"以上是“怎么使用SQL查询Linux日志”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



