这篇“Linux系统编程常用命令有哪些”文章的知识点大部分人都不太理解,所以小编给大家总结了以下内容,内容详细,步骤清晰,具有一定的借鉴价值,希望大家阅读完这篇文章能有所收获,下面我们一起来看看这篇“Linux系统编程常用命令有哪些”文章吧。
sudo apt-get install gcc
sudo apt-get install g++
C语言与C++的编译执行
C语言编译 gcc test.c -o test
C语言执行 ./test
C++编译 g++ test.cpp -o test
C++执行 ./test
以下以C语言为例:
代码用geidt编辑,用gcc编译
1.在主文件夹下新建一个文件夹,取名code
2.在code文件夹下创建一个新文档,取名test.c(如果是C++语言,取名为test.cpp)
3.直接在该文档中写好代码并保存
4.Ctr**l+Alt+T打开终端,进入test.c**所在目录
5.用gcc对test.c进行编译,生成可执行文件test:gcc test.c -o test(如果是C++语言: g++ test.cpp -o test)
6.同样在code目录下,用./test执行代码****
****
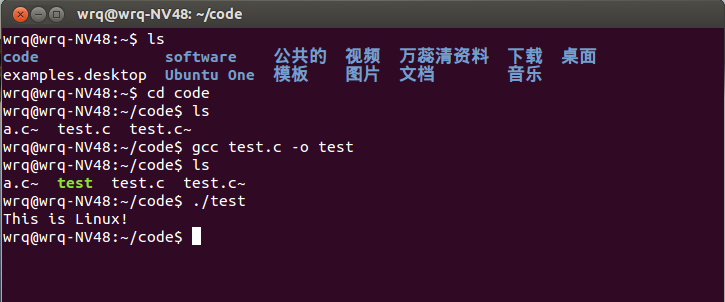
对上图进行解释:
Ctrl+Alt+T打开终端,默认进入主文件夹,通过ls命令,查看主文件夹目录下的内容;
通过cd code进入code文件夹目录;
通过ls命令查看code文件夹目录下的内容;
通过gcc test.c -o test进行编译,并生成可执行文件test;
再执行ls命令,可以看到,该目录下多了test这个文件;
通过./test执行test文件;
This is Linux!为执行结果。
Linux下如何实现多文件编程?
假设有三个文件:两个源文件(file1.cpp、file2.cpp)和一个头文件(head.h)
头文件不需要编译,只需要在源文件中包含了这个头文件即可:#include “head.h”
编译多个源文件:g++ -o output file1.cpp file2.cpp
1)编译应用程序
make -f makefile_5_2 clean
make -f makefile_5_2
2)关于共享目录
在linux虚拟机的/mnt/hgfs下可看到该文件夹
3)cd命令,进入文件夹
cd /mnt/hgfs/
4)复制cp命令
cp -ri A/B/* A1/B1/ 提示是否覆盖
\cp -rf A/B/* A1/B1/ 不提示直接覆盖
5)linux关机
shutdown -h now
6)创建目录mkdir
mkdir HPP
7)查看文件时间
stat hpp
8)在linux下启动程序 ./ccs
程序的退出,首先用ps -ef|grep XXX 查看其pid,然后用kill pid退回 ———-强制退出kill -9 PID
9)ll看看文件读写权限,chmod 777 XXX 赋予文件最高权限
10)dos2unix命令用来将DOS格式的文本文件转换成UNIX格式的,将window的文件上传到linux下有时候需要作个转换
格式:dos2unix file
#chapter 2 shell basic
1. 访问脚本从命令行接收到的参数:$n
在脚本中使用 $1 访问第一个参数,$2访问第二个,当超过9时,用大括号引起来,如 ${10}。
2. 在shell脚本执行时,使用-x打开脚本执行跟踪功能。如: $ sh -x nusers.sh
3. 列出系统所支持的所有语言: locale -a
#chapter 3 search and substitution
4. shell BRE(Basic RE) and ERE(Extended RE)正则表达式简记:
\ 关闭或者打开后续字符的特殊意义
. 匹配任何单个字符,初NUL外
* 匹配在它之前的任何数目的单个字符
+ 1个或多个(ERE only)
? 0个或多个(ERE only)
^ 表示一行的开始,在[^…]里面表示取反
$ 表示一行的结尾
[…] 匹配方括号内的任一单个字符
{n} 匹配前面单个字符出现n次(ERE,在BRE中需要使用转义\{n\})
{n,m} 出现至少n次,最多m次
() 表示一个实例(ERE only)
| 匹配之前或之后的正则表达式(ERE only)
注意:在BRE下,^$只在起始和结束处具有特殊意义,在其他位置如39.8$killo就表示$本身。
5. 向后引用: backreferences
如,\(ab\)\(cd\)[def]*\2\1 可以匹配abcdcdab, abcdeeecdab, abcdffcdab, …向后引用最多可以有9个
6. POSIX字符集: [:alpha:]
[:alnum:] 数字字符,如123
[:alpha:] 字母字符,如abcDEF
[:lower:] 小写字母字符,如abc
[:upper:] 大写字母字符,如DEF
[:blank:] 空格space于定位tab字符
……更多
$ grep -E ^[[:alpha:]]\{3\} data.txt
hello, world.
abcDEFdefABC
7. ERE(Extended RE)
没有向后引用。
区间表达不需要\{\},直接使用abc{3,5},表示c出现3到5次
? 表示0个或一个前置RE
+ 1个或多个
* 与BRE相同,0个或多个
| 交替,匹配这个序列或那个序列或… read|write|listen
() 分组,(abc){3,5}表示abc出现3到5次,但不包括括号()本身,
8. 额外的GNU正则表达式运算符: \w
\w 匹配任何单词组成的字符
\W 匹配任何非单词组成的字符,^\w
9. 进行文本查找替换: sed(steam editor)
sed s/regexp/replacement/
$ sed ‘s/:.*/:******/’ data.txt
hello, world.
abcDEFdefABC
password:******
another password:******
上面命令把冒号(:)后面的所有内容替换成6个星号(*),sed s/regexp/replacement/中的/作为一个定界符,任何可以显示的字符都可以,如
sed s;regexp;replacement;
sed s:regexp:replacement:
sed s,regexp,replacement,
……等
$ find /home/owen/test/todelete/ -type d -print |
sed ‘s;/home/owen/test/todelete;/home/owen/test/todel;’ |
sed ‘s/^/mkdir /’ |
sh -x
+ mkdir /home/owen/test/todel/
+ mkdir /home/owen/test/todel/xyz
该命令首先找出/home/owen/test/todelete/这个目录下的所有目录,包括这个目录自身,然后把todelete替换成todel,得到如下结果:
/home/owen/test/todel/
/home/owen/test/todel/xyz
然后在每行前面加上”mkdir “命令创建新的目录。所实现的功能类似cp。
10. 查看系统的密码信息: /etc/passwd
$ more /etc/passwd
owen:x:1000:1000:owen,,,:/home/owen:/bin/bash
每行都是以:分隔的7个字段,分别表示
owen 用户名称
x 加密后的密码
1000 用户ID编号
1000 用户组ID编号
owen,,, 用户姓名,附加其他信息,如联系方式等
/home/owen 用户的根目录
/bin/bash 登录的shell类型
11. 从文本中剪贴部分内容: cut
$ cut -d : -f 1,5 /etc/passwd | grep -E ^m
man:man
mail:mail
messagebus:
mysql:MySQL Server,,,
-d 表示分割符,-f 表示field
12. 连接2个文件,基于字段:join
join quotas.sorted sales.sorted
使用两个文件中第一个字段进行连接,如
quotas.sorted
a b
sales.sorted
a c
连接之后,为a b c
当然可以指定连接的key, -1 2 -2 5, 参考manual
13. 重新编排字段: awk
$ ls -l | awk ‘{ print $8, $5, $1}’ | sort
data.txt 67 -rw-r–r–
finduser 88 -rwxr-xr-x
merge-sales.sh 363 -rwxr-xr-x
note.sh 36 -rwxr-xr-x
nusers 60 -rwxr-xr-x
quotas 58 -rw-r–r–
sales 71 -rw-r–r–
total
这里先列出当前目录下的文件,然后使用awk显示文件名,大小,权限,最后进行排序显示。
awk默认使用空格作为分隔字符。
$ ls -l | awk ‘{ printf “%s %s\t %s\n”, $1, $5, $8}’ | sort
其基本模式如下:
#chapter 4 text process tools
14. 文本排序: sort
$ sort -t : -k 3,3 /etc/passwd
-t指定分隔符,-k指定从哪个字段到哪个字段作为key进行排序
15. 去除重复: uniq
$ sort uniq-data | uniq -c
2 duo
3 tres
1 unus
消除重复,可以控制显示重复的或是未重复的记录
16. 简单的文本格式化命令: fmt
$ more data.txt | fmt -w 50
hello, world. abcDEFdefABC password:123456
another password:666888
string sort\nbased on lines delimilated by new
line sign
格式化成每行最多50个字符
17. 计算行数、字数和字符数: wc
/usr/share/dict$ more words | grep ^herb | wc -lwc
17 17 165
18. 查看标准输入的前n条记录,或是文件列表中的前n条,或后n条: head, tail
head -n 5 /etc/passwd
sed -e 5q /etc/passwd
显示倒数n条,一般用来查看最近的日志记录
tail -n 5 /etc/passwd
#chapter 5 the magic power of pipe
19. 文字解谜好帮手puzzle-help.sh文件: example
FILES=”
/usr/dict/words
/usr/share/dict/words
”
pattern=”$1″
egrep -h -i “$pattern” $FILES 2> /dev/null | sort -u -f
使用这个脚本来进行查找具有10个字母的单词,以b开头,第7位不是x就是y:
$ sh puzzle-help.sh ‘^b.{5}[xy].{3}$’ | fmt
beatifying Birdseye’s blarneying Brooklyn’s Bulawayo’s
等价于使用命令:
/usr/share/dict$ more words | egrep -i ‘^b.{5}[xy].{3}$’| sort
beatifying
Birdseye’s
blarneying
Brooklyn’s
Bulawayo’s
20. 转换或者删除字符:tr
tr [ options ] source-char-list replace-char-list
-c 取source-char-list的反义,即对没有出现在source-char-list中的字符进行转换或删除
-d 删除source-char-list里出现的字符,如删除所有元音字母:
echo hello world | tr -d [aeiou]
hll wrld
-s 浓缩重复的字符,如:
echo hello world | tr -s l
helo world
一般会组合来使用,如全部转换成小写字符,所有非字母字符转换成换行符号
echo heLLo WorLd 123 End | tr A-Z a-z | tr -cs A-Za-z ‘\n’
hello
world
end
这里没有包括数字,如果需要包括,则添加A-Za-z0-9就可以了
21. 统计一篇文章中单词出现频率: wf
tr -cs A-Za-z0-9 ‘\n’ | 将非字母字符转换成换行符号,-cs参考第20条笔记
tr A-Z a-z | 全部转换成小写字母
sort | 排序
uniq -c | 统计频率,结果: 13 the等
sort -k1,1nr -k2 | 首先只取第一个field即数字,按照数字顺序-n逆序-r排序,再对单词以字典顺序排序
sed ${1:-25}q ${1}获取命令行的第一个参数,如果没有默认为25,后面q表示退出程序
${1:-25}是shell里面的一个参数展开形式,具体如下:
${var:-default-var}
展开方式是:首先查找${var},如果找到,值就为${var},如果没有找到,值就等于default-var
使用(需要chmod +x wf,然后把wf放到$PATH路径下),使用频率最高的:
man awk | wf | pr -c4 -t -w80
292 the 69 are 50 0 40 mawk
169 and 69 string 49 s 40 n
168 is 65 1 48 expr 39 be
155 a 64 if 45 as 38 awk
124 of 52 for 45 or 38 file
118 to 52 with 40 an 38 i
80 in
pr命令,打印格式化,page column for printing
-c4 表示column4,相当于word的分栏操作,这里设置为4栏
-t 表示不显示页头和页尾,如果没有这个,就是一张打印纸那么大
-w80 设置页面宽度,这里是80个字符
最低的呢:
$ man awk | wf 99999 | tail -n 25 | pr -c4 -t -w80
1 typically 1 under 1 values 1 wc
1 u 1 underscores 1 variations 1 we
1 unaltered 1 unlike 1 variety 1 whidbey
1 unambiguous 1 unnecessary 1 vdiesp 1 writing
1 unbuffered 1 unsafe 1 vertical 1 xaxbxcx
1 unchanged 1 usually 1 via 1 xhh
1 undefined
我的path
echo $PATH
/home/owen/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
这个程序比较有意思,我们可以算出awk手册里使用了多少个不重复的单词,才1014个,99999这个数没有实际意义,只是很大而已
$ man awk | wf 99999 | wc -l
1014
高频词汇(频率在5次以上,包括5次)个数,尽然是这么得少!
$ man awk | wf 99999 | awk ‘$1 >= 5’ | wc -l
220
22. 学以致用: 标记和自动目录生成
$ more shell笔记.txt | grep -E ‘#’
#chapter 2 shell basic
#chapter 3 search and substitution
#chapter 4 text process tools
#chapter 5 the magic power of pipe
more shell笔记.txt | grep -E ‘^[0-9]+\.’ | sed ‘s/^/@-/’
@-1. 访问脚本从命令行接收到的参数:$n
@-2. 在shell脚本执行时,使用-x打开脚本执行跟踪功能。如: $ sh -x nusers.sh
@-3. 列出系统所支持的所有语言: locale -a
@-4. shell BRE(Basic RE) and ERE(Extended RE)正则表达式简记:
@-5. 向后引用: backreferences
@-6. POSIX字符集: [:alpha:]
@-7. ERE(Extended RE)
@-8. 额外的GNU正则表达式运算符: \w
@-9. 进行文本查找替换: sed(steam editor)
@-10. 查看系统的密码信息: /etc/passwd
@-11. 从文本中剪贴部分内容: cut
@-12. 连接2个文件,基于字段:join
@-13. 重新编排字段: awk
@-14. 文本排序: sort
@-15. 去除重复: uniq
@-16. 简单的文本格式化命令: fmt
@-17. 计算行数、字数和字符数: wc
@-18. 查看标准输入的前n条记录,或是文件列表中的前n条,或后n条: head, tail
@-19. 文字解谜好帮手puzzle-help.sh文件: example
@-20. 转换或者删除字符:tr
@-21. 统计一篇文章中单词出现频率: wf
@-22. 学以致用: 标记和自动目录生成
使用sed命令给每条数据添加一个@-前缀,以便与真正的目录混淆。
#chapter 6 variables, repetitions
23. 设置或修改环境变量: export
PATH=$PATH:/home/owen/bin
export PATH
打印环境变量export -p
24. 从shell中删除变量于函数: unset
$ foo=123
$ echo $foo
123
$ unset foo
$ echo $foo
使用unset -f function_name删除函数,默认为-v即删除变量
25. 参数展开: ${varname:-word}
替换运算:
${varname:-word} 如果varname存在且非Null,则返回其值;否则返回word。用途: 如果变量未定义,则使用默认值
${varname:=word} 如果varname存在且非Null,则返回其值;否则设置它的值为word,并返回其值。用途: 如果变量未定义,则设置变量为默认值
${varname:+word} 如果varname存在且非Null,则返回word;否则返回null。用途: 为测试变量的存在。
${varname:?message} 如果varname存在且非Null,则返回其值;否则显示varname:message,并退出当前命令或脚本。用途: 捕捉由于变量未定义所导致的错误
$ echo ${vars:?”undefined, pls check it”}
bash: vars: undefined, pls check it
注意上面的${varname:-word}每个冒号(:)都是可选的,如果没有冒号,条件变为“如果varname存在”,也就是可以为空
更多模式匹配
$ p=/home/jwu/cases/long.file.name
$ echo $p
/home/jwu/cases/long.file.name
${variable#pattern} 如果模式匹配于变量的开头处,则删除匹配的最短部分,返回剩下的部分
$ echo ${p#/*/}
jwu/cases/long.file.name
${variable##pattern} 如果模式匹配于变量的开头处,则删除匹配的最长部分,返回剩下的部分
$ echo ${p##/*/}
long.file.name
${variable%pattern} 如果模式匹配于变量的结尾处,则删除匹配的最短部分,返回剩下的部分
$ echo ${p%.*}
/home/jwu/cases/long.file
${variable%%pattern} 如果模式匹配于变量的结尾处,则删除匹配的最长部分,返回剩下的部分
$ echo ${p%%.*}
/home/jwu/cases/long
注意,这里使用的pattern,以及shell里其他的地方,如case语句等,不同于前面正则表达式的模式匹配。如上,这里*代表任何一个符号,而.只代表点号本身。
26. POSIX标准化字符从长度运算符: ${#variable}返回$variable值的长度
$ d=diversification
$ echo $d
diversification
$ echo ${#d}
15
27. shell特殊变量,访问参数: $#, $@, $*
设置参数: $ set — hello “hi there” greeting
$# 传递到shell脚本或函数的参数总数
$@ 传递进来的命令行参数,置于双引号(“”)内,会展开为个别的参数
$ for i in $@
> do echo i is $i
> done
i is hello
i is hi
i is there
i is greeting
注意上面的hi there之间的空格丢失了
$ for i in “$@”
> do echo i is $i
> done
i is hello
i is hi there
i is greeting
加上””会得到每个参数
$* 传递进来的命令行参数,置于双引号(“”)内,会展开为一个单独的参数
28. shell运算符与C语言类似: + – * /
运算置于$((…))之内,注意是圆括号
具体参考运算表
例:
$((3 && 2))
1
$ echo $((3 > 2))
1
$ echo $((3 > 4))
0
$ echo $(( (3 > 2) || (3 > 4) ))
1
与C及其衍生语言C++, Java, and awk等相同,非0值表示true。
29. 退出状态: $?
$ echo hello
hello
$ echo $?
0
$ e s
e: command not found
$ echo $?
127
POSIX的结束状态
0 命令成功退出
其他状态都是失败退出,如
127 命令找不到
可以在shell脚本中传递一个退出值给它的调用者,如exit 42
30. 判断语句: if-elif-else-fi
if pipeline
then …
elif pipeline
then …
else …
fi
31. 逻辑判断: NOT, AND, OR
NOT if ! (…)
AND (…) && (…)
OR (…) || (…)
32. test命令: if…
if [ $# -ne 1 ]
then
echo Usage: finduser username >&2
exit 1
fi
主要的数字比较有
-eq equal
-ne not equal
-lt less than
-gt great than
-le less or equal
-ge great or equal
#chapter 7 input/output, file, and commands execute
to be continue…
以上就是关于“Linux系统编程常用命令有哪些”这篇文章的内容,相信大家都有了一定的了解,希望小编分享的内容对大家有帮助,若想了解更多相关的知识内容,请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务