小编给大家分享一下Kafka怎么读写副本消息,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
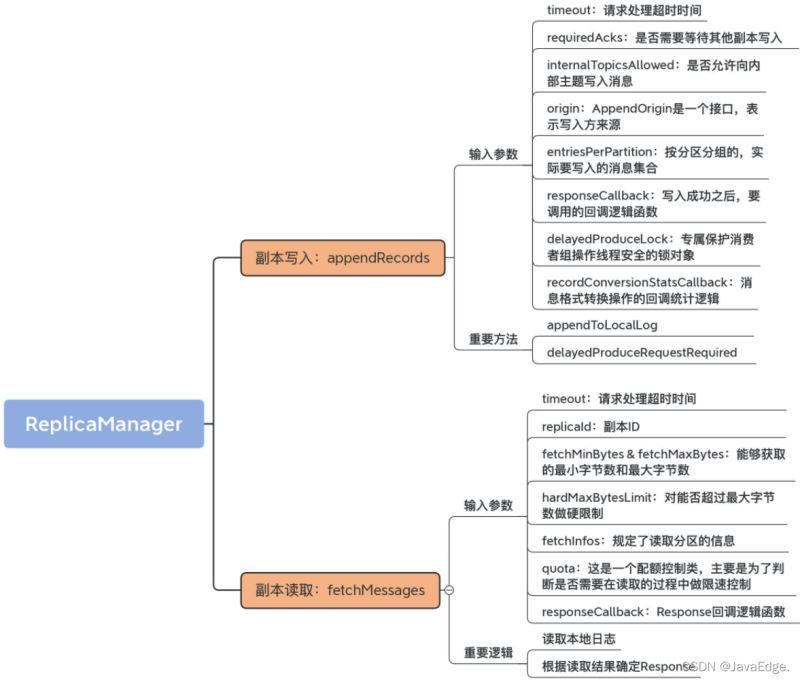
向副本底层日志写入消息的逻辑就实现在ReplicaManager#appendRecords。
Kafka需副本写入的场景:
生产者向Leader副本写入消息
Follower副本拉取消息后写入副本
仅该场景调用Partition对象的方法,其余3个都是调用appendRecords完成
消费者组写入组信息
事务管理器写入事务信息(包括事务标记、事务元数据等)
appendRecords方法将给定的一组分区的消息写入对应Leader副本,并根据PRODUCE请求中acks的设置,有选择地等待其他副本写入完成。然后,调用指定回调逻辑。
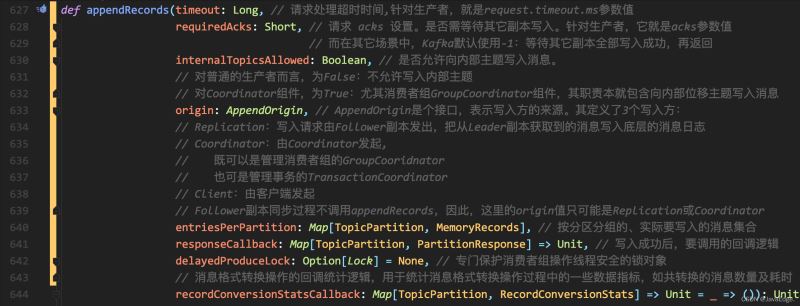
appendRecords向副本日志写入消息的过程:


执行流程
可见,appendRecords:
实现消息写入的方法是appendToLocalLog
判断是否需要等待其他副本写入的方法delayedProduceRequestRequired
appendToLocalLog写入副本本地日志
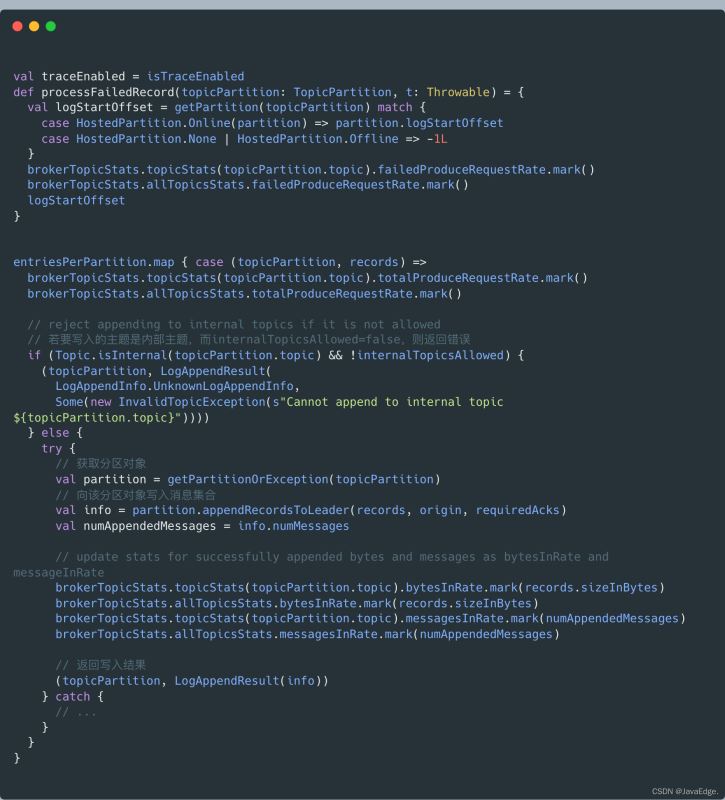
利用Partition#appendRecordsToLeader写入消息集合,就是利用appendAsLeader方法写入本地日志的。
delayedProduceRequestRequired
判断消息集合被写入到日志之后,是否需要等待其它副本也写入成功:
private def delayedProduceRequestRequired(
requiredAcks: Short,
entriesPerPartition: Map[TopicPartition, MemoryRecords],
localProduceResults: Map[TopicPartition, LogAppendResult]): Boolean = {
requiredAcks == -1 && entriesPerPartition.nonEmpty &&
localProduceResults.values.count(_.exception.isDefined) < entriesPerPartition.size
}若等待其他副本的写入,须同时满足:
requiredAcks==-1
依然有数据尚未写完
至少有一个分区的消息,已成功被写入本地日志
2和3可结合来看。若所有分区的数据写入都不成功,则可能出现严重错误,此时应不再等待,而是直接返回错误给发送方。
而有部分分区成功写入,部分分区写入失败,则可能偶发的瞬时错误导致。此时,不妨将本次写入请求放入Purgatory,给个重试机会。
ReplicaManager#fetchMessages负责读取副本数据。无论:
Java消费者
APIFollower副本
拉取消息的主途径都是向Broker发FETCH请求,Broker端接收到该请求后,调用fetchMessages从底层的Leader副本取出消息。
fetchMessages也可能会延时处理FETCH请求,因Broker端必须要累积足够多数据后,才会返回Response给请求发送方。


整个方法分为:
读取本地日志
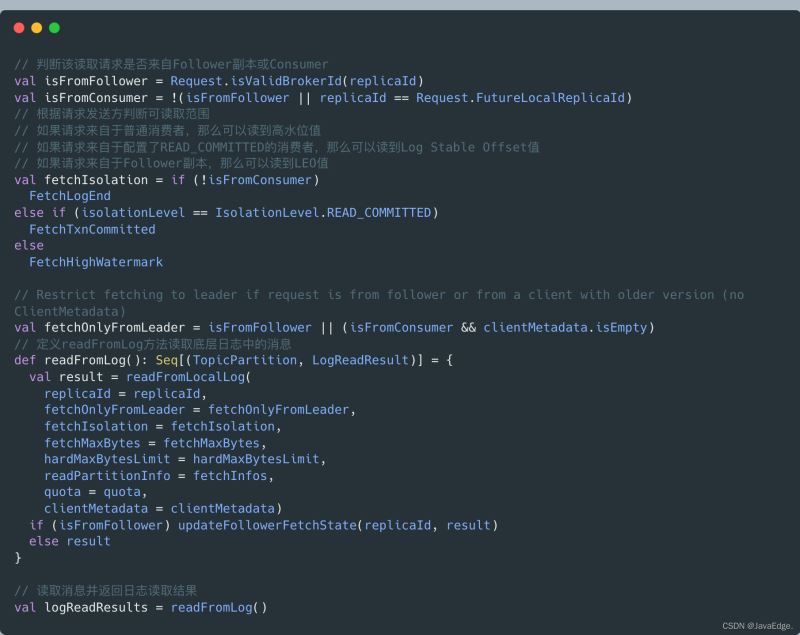
首先判断,读取消息的请求方,就能确定可读取的范围了。
fetchIsolation,读取隔离级别:
对Follower副本,它能读取到Leader副本LEO值以下的所有消息
普通Consumer,只能“看到”Leader副本高水位值以下的消息
确定可读取范围后,调用readFromLog读取本地日志上的消息数据,并将结果赋给logReadResults变量。readFromLog调用readFromLocalLog,在待读取分区上依次调用其日志对象的read方法执行实际的消息读取。
根据读取结果确定Response
根据上一步读取结果创建对应Response:
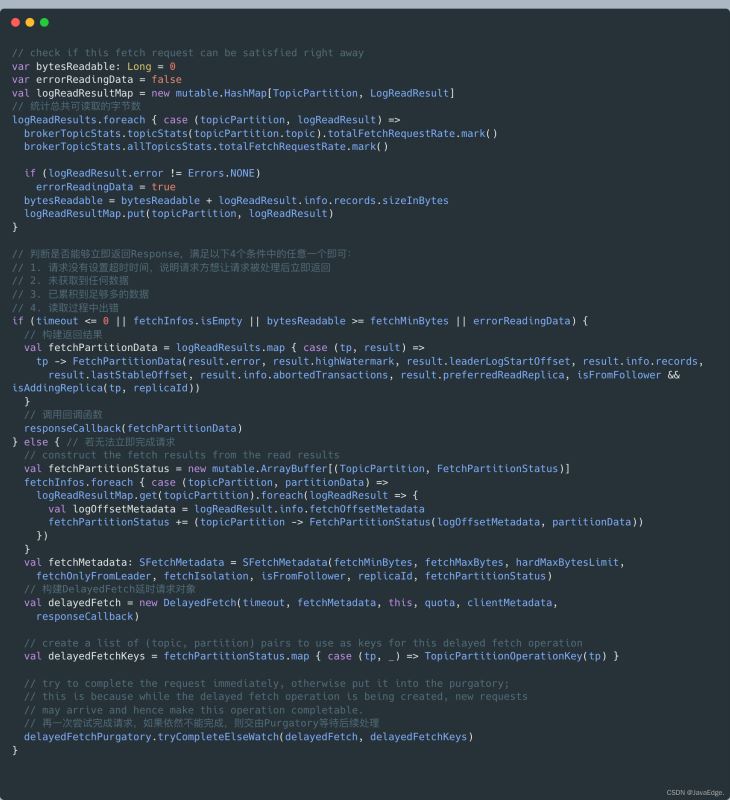
根据上一步得到的读取结果,统计可读取的总字节数,然后判断此时是否能够立即返回Reponse。
副本管理器读写副本的两个方法appendRecords和fetchMessages本质上在底层分别调用Log的append和read方法,以实现本地日志的读写操作。完成读写操作后,这两个方法还定义了延时处理的条件。一旦满足延时处理条件,就交给对应Purgatory处理。
从这俩方法可见单个组件融合一起的趋势。虽然我们学习单个源码文件的顺序是自上而下,但串联Kafka主要组件功能的路径却是自下而上。
如副本写入操作,日志对象append方法被上一层的Partition对象中的方法调用,而后者又进一步被副本管理器中的方法调用。我们按自上而下阅读了副本管理器、日志对象等单个组件的代码,了解了各自的独立功能。
现在开始慢慢地把它们融合一起,构建Kafka操作分区副本日志对象的完整调用路径。同时采用这两种方式来阅读源码,就能更高效弄懂Kafka原理。
Kafka副本状态机类ReplicaManager读写副本的核心方法:
appendRecords:向副本写入消息,利用Log#append方法和Purgatory机制实现Follower副本向Leader副本获取消息后的数据同步操作
fetchMessages:从副本读取消息,为普通Consumer和Follower副本所使用。当它们向Broker发送FETCH请求时,Broker上的副本管理器调用该方法从本地日志中获取指定消息
以上是“Kafka怎么读写副本消息”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



