这篇文章主要介绍python如何实现Simhash算法,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
simhash包含分词、hash、加权、合并、降维五大步骤
simhash代码如下:
import jieba
import jieba.analyse
import numpy as np
class SimHash(object):
def simHash(self, content):
seg = jieba.cut(content)
# jieba.analyse.set_stop_words('stopword.txt')
# jieba基于TF-IDF提取关键词
keyWords = jieba.analyse.extract_tags("|".join(seg), topK=10, withWeight=True)
keyList = []
for feature, weight in keyWords:
# print('feature:' + feature)
print('weight: {}'.format(weight))
# weight = math.ceil(weight)
weight = int(weight)
binstr = self.string_hash(feature)
print('feature: %s , string_hash %s' % (feature, binstr))
temp = []
for c in binstr:
if (c == '1'):
temp.append(weight)
else:
temp.append(-weight)
keyList.append(temp)
listSum = np.sum(np.array(keyList), axis=0)
if (keyList == []):
return '00'
simhash = ''
for i in listSum:
if (i > 0):
simhash = simhash + '1'
else:
simhash = simhash + '0'
return simhash
def string_hash(self, source):
if source == "":
return 0
else:
temp = source[0]
temp1 = ord(temp)
x = ord(source[0]) << 7
m = 1000003
mask = 2 ** 128 - 1
for c in source:
x = ((x * m) ^ ord(c)) & mask
x ^= len(source)
if x == -1:
x = -2
x = bin(x).replace('0b', '').zfill(64)[-64:]
return str(x)
def getDistance(self, hashstr1, hashstr2):
'''
计算两个simhash的汉明距离
'''
length = 0
for index, char in enumerate(hashstr1):
if char == hashstr2[index]:
continue
else:
length += 1
return length分词是将文本文档进行分割成不同的词组,比如词1为:今天星期四,词2为:今天星期五
得出分词结果为【今天,星期四】【今天,星期五】
hash是将分词结果取hash值
星期四hash为:0010001100100000101001101010000000101111011010010001100011011110
今天hash为:0010001111010100010011110001110010100011110111111011001011110101
星期五hash为:0010001100100000101001101010000000101111011010010000000010010001


降维是将合并的结果进行降维,如果值大于0,则置为1小于0 则置为0,因此得到的结果为:
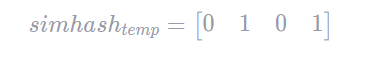
一般simhash采用海明距离来进行计算相似度,海明距离计算如下:
对于A,B两个n维二进制数
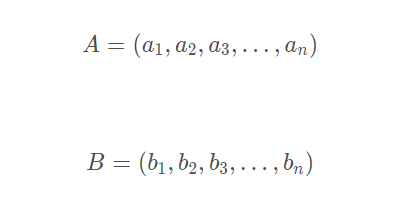
二者的海明距离为:
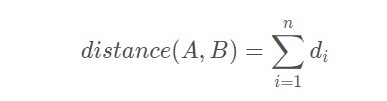
其中:
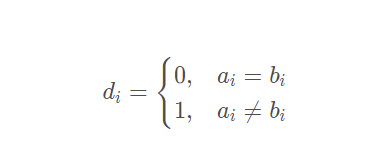
举例:
1000与1111的海明距离为3
以上是“python如何实现Simhash算法”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



